计算机网络——自顶向下的方法第三章的学习
自顶向下,目前是比较重要的一层,在传输层。
这里有两个比较重要的协议:TCP和UDP协议。
梗概
TCP 是面向连接的,可靠的运输层传输协议
UDP 是面向无连接的,不可靠的运输层传输协议。
概述和运输层服务
运输层提供了应用进程之间的逻辑通信,因为对于应用程序来看,依靠 TCP 和 UDP 协议好像可以使互联网上任意两台主机进行直接通信。应用进程使用运输层提供的逻辑通信功能发送报文,无需考虑这些报文的物理基础设施的细节,我们把运输层的分组叫报文段(segment)。
运输层和网络层关系
网络层实际而言提供了两台主机之间的通信,而运输层提供了两台主机所在进程的逻辑通信。
我自己理解了一遍创建了一个新的类比,就可以类比成快递。
假如我有一个很大的物件,我想通过快递直接送给另一个人(逻辑上)。
那么我会先把他交给我们市所在的菜鸟驿站,菜鸟驿站可以理解为一个运输层协议了。像上可以直接提供快递收发服务(这直接是两个人之间的发送接收,菜鸟驿站本身提供的功能),向下可以直接将快递无差错运输到其它市的菜鸟驿站(这里的向下可以理解为物流服务,物流服务用于给两个驿站之间提供服务)。
在这个了例子中:
端系统=菜鸟驿站
进程=寄快递和收快递的人
运输层协议=菜鸟驿站的工作人员
网络层协议=物流服务
应用层报文=人们寄的快递
网络层只需交付到具体主机即可,而应用层会进一步地交付到主机的具体进程。
网络层协议是不可靠的,它会使分组丢失,篡改,冗余,即使这样,运输层协议也能提供可靠的数据传输服务。而且即使网络层是透明传输,不保证保密性,传输层依然可以使用某种方式确保其保密性。
因特网运输层概述
一种是 UDP(用户数据协议),另一种是 TCP(传输控制协议),开发人员在生成套接字的时候必须指定两个协议的其中一种。
在讲运输层之前先简单介绍下网络层:网络层有一个协议叫 IP,即网际协议,IP 为主机之间提供了逻辑通信,IP的服务模型是尽力而为交付服务(best-effort delivery service)。IP 被称为不可靠服务,每个主机至少会有一个网络层地址,也叫 IP 地址。
UDP 和 IP 一样,都是提供不可靠的数据传输服务,但是 TCP 和 UDP 都有出错检查,比如 UDP 首部有一个校验和,如果出错那么就会直接丢弃该分组,并且不会要求重传;如果是 TCP 的话,目的主机除了丢弃分组以外还会发送信号表示该分组没有接收到要求重传。
TCP 为应用程序附加了几种服务:
- 可靠数据传输:通过使用流量控制、序号、确认和定时器
- 拥塞控制:在网络拥堵的时候会限制发送速率,而 UDP 流量不可调节,应用程序可以以根据其需要以任意速率发送数据。
多路复用和多路分解
这俩概念其实很简单:
- 多路复用:对源主机的所有套接字发送的报文段进行收集,并通过网络层协议统一封装发送。
- 多路分解:将发送到该主机的所有数据报进行分发。
运输层多路复用的要求:
- 套接字具有唯一的标识符,便于分发。
- 报文段有特殊的字段标识了要交付的某个套接字。
这个其实都好解决,就是使用我们平时所说的端口,每个套接字可以绑定 0-65535 之间的任意端口。
我们来看看运输层报文的字段。

这里没 IP 地址是因为 IP 是在网络层封装上去的数据,这里没有。
无连接的多路复用与多路分解
在 python 中,使用下面代码创建一个 UDP 套接字:
1 | clientsocket=socket(AF_INET, SOCK_DGRAM) |
创建一个套接字之后,默认它是客户端套接字,在发送数据或者是创建连接的时候,会从 1024~65535 内分配一个端口号(透明的,客户端不知道也不需要知道这个具体的数值)。
另外我们可以使用 bind 函数绑定一个本地端口,并把客户端套接字转换为服务端套接字。
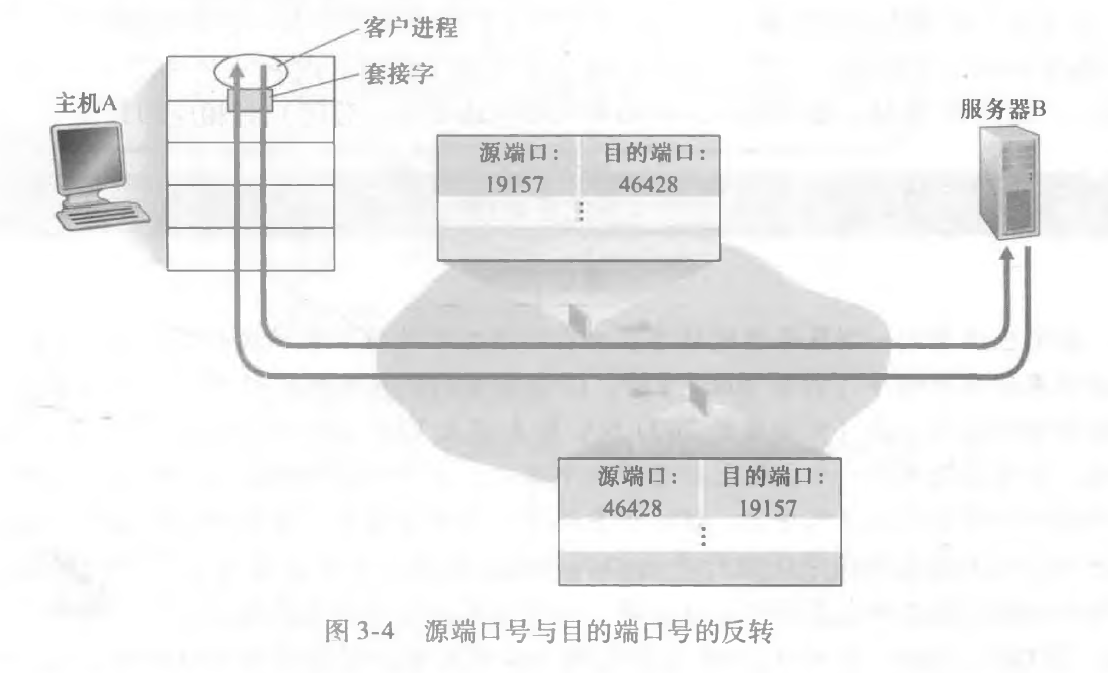
对于 UDP 来说,目的 IP 地址和目的端口一样的报文段会被发送到同一个主机的指定进程上,因此 UDP 数据报可以使用二元组来表示(目的IP,目的端口)。源端口号存在的目的就是用于回发,当服务端收到信息如果要回复给客户端的话需要从里面取出相应的数据。
面向连接的多路复用和多路分解
这个和UDP略微不一样,因为它要建立连接才可以发送报文,因此一个 TCP 数据报是由四元组标识的,即(源IP,目的IP,源端口,目的端口)。
WEB服务与TCP
这个在 CSAPP 的第11章讨论过了,推荐移步
无连接运输:UDP
UDP 被称为无连接的协议。因此客户端不能保证自己一定能接收到,也不能保证一定能发送到服务器。
应用层服务中,DNS 就是典型的使用 UDP 协议,当一次 DNS 查询得不到响应时,要么通知应用程序不能获得响应,要么发送到其它 DNS 服务器上。
之前就有一个疑问,为什么应用开发人员宁愿在UDP之上构建应用,而不选择在 TCP 上构建应用?既然TCP提供了可靠数据传输服务,而UDP不能提供,那么TCP是否总是 首选的呢?答案是否定的,因为有许多应用更适合用UDP,原因主要以下几点:
- UDP 没有拥塞控制机制:只要应用层应用愿意,可以以任意支持的速率发送。
- 无需建立连接:少了三次握手的时延。
- 无状态连接:UDP 不维护序号及确认参数,这一部分时延也会减小。
- 分组首部开销小:TCP 首部有 20 字节,而 UDP 首部只有 8 个字节。
不管怎么说,主要原因还是因为 UDP 没有拥塞控制机制,对于需要高带宽,高速率,低延迟,且能容忍数据丢失的应用就更适合使用 UDP 协议。
但是因为 UDP 这样的无限制速度,就有可能导致网络陷入拥塞,因此很多防火墙丢弃 UDP 流量使得网络变得顺畅,因此有些应用不单单使用 UDP,在 UDP 分组被丢弃时,可能会转而使用 TCP 协议。
并且为了实现可靠的数据传输,使用 UDP 运输层协议需要自己在应用层实现出错重传等机制,确保数据的有效性。
UDP 报文段结构
报文段结构图如下
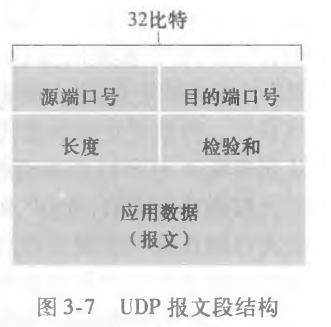
首部有四个字段,每个字段两个字节。
长度字段指示了包括自己首部在内的总数据长度,校验和是用于检查该报文段是否出现了差错。
UDP 校验和
校验的步骤是:
把除了校验位以外的数据进行 2 字节分组相加(若为奇数个字节长度,则最后一位填充全0字节),相加若产生溢出,则高位的溢出视为最低位的 1 相加。
举个例子就是 1000000000000000+1000000000000000=0000000000000001。
最后得到的结果取反就是校验位的值了,接收方接收到 UDP 数据报之后,将所有的数据两个字节两个字节相加,最后得到的结果应当是 1111111111111111,如果不是,则一定出错了。
虽然UDP提供差错检测,但它对差错恢复无能为力。
可靠数据传输原理
为上层实体提供的服务抽象是:数据可以通过一条可靠的信道进行传输。借助于可靠信道,传输数据比特就不会受到损坏
(由0变为1,或者相反)或丢失,而且所有数据都是按照其发送顺序进行交付。
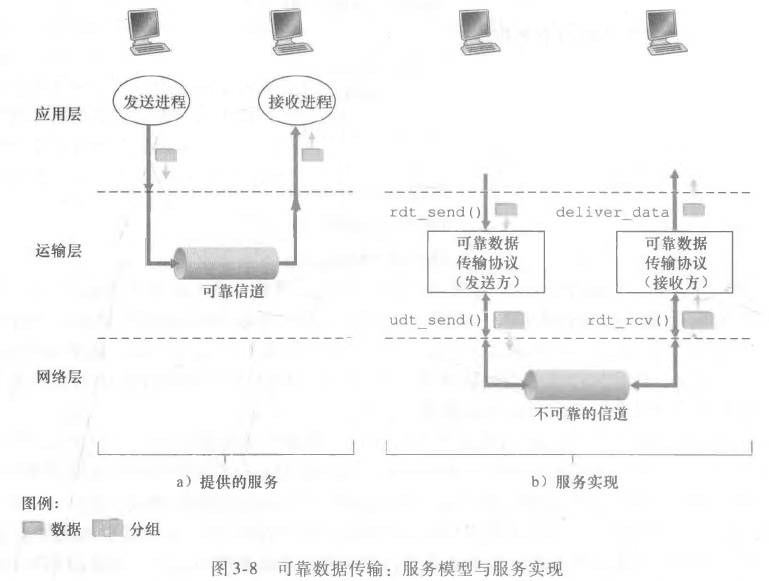
实现这种服务抽象是可靠数据传输协议(reliable data transfer protocol)的责任。由于下层的 IP 协议是不可靠的数据传输协议(unreliable data transfer protocol),在此基础之上实现可靠的传输协议是困难的。
再上图中:
rdt_send表示可靠的数据发送udt_send表示不可靠的数据发送rdt_rcv表示可靠的数据接收deliver_data表示数据向上层的分发
为了简化模型,我们把网络层视为不可靠的点对点信道。
构造可靠数据传输协议
接下来是我们构造可靠传输协议的一个步骤,我们先从最理想的情况开始,一步一步减少条件,没有条件,那就创造条件。
经完全可靠信道的可靠数据传输:rdt1.0
我们定义一个有限状态自动机(Finite-State Machine,FSM),来看发送端和接收端。
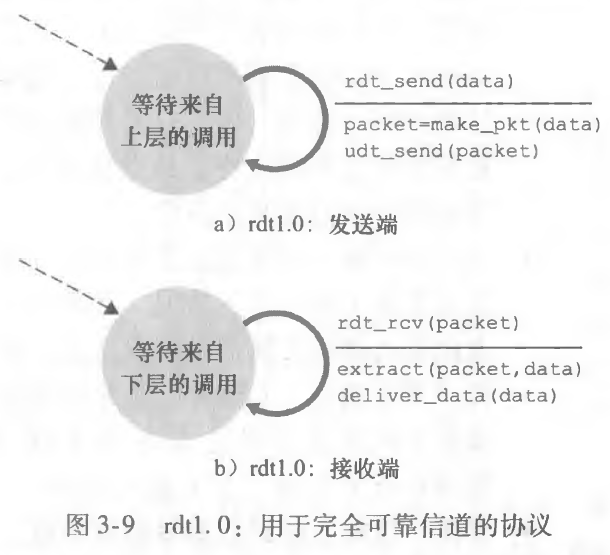
对于信道完全可靠的情况,我们只需要把信息交给下层处理即可马上恢复到可以重新发送信息的状态。
经具有比特差错信道的可靠数据传输:rdt2.0
到了这里开始,包可能会出现了比特差错。
为了解决这个问题,我们需要像 UDP 一样引入一个校验和判断传输包的过程中是否发生差错。但是不能像 UDP 那样,出错了就不管了直接丢弃分组,我们需要跟接收方说一声:我没听清,你再说一遍,然后它重新传一个包过来。
这里我们一引入了肯定确认(positive acknowledgment)与否定确认(negative acknowledgment),引入这个确认机制可以让接收方知道哪些数据有错误,并选择重传,基于这样重传机制的可靠数据传输协议称为自动重传请求(Automatic Repeat request,ARQ)协议。
- 差错检测。首先,需要一种机制以使接收方检测到何时出现了比特差错。
- 接收方反馈。接收方在收到分组之后要校验发送的数据是否正确,并即使给发送方回复
- 重传。接收方收到有差错的分组时,发送方将重传该分组文。
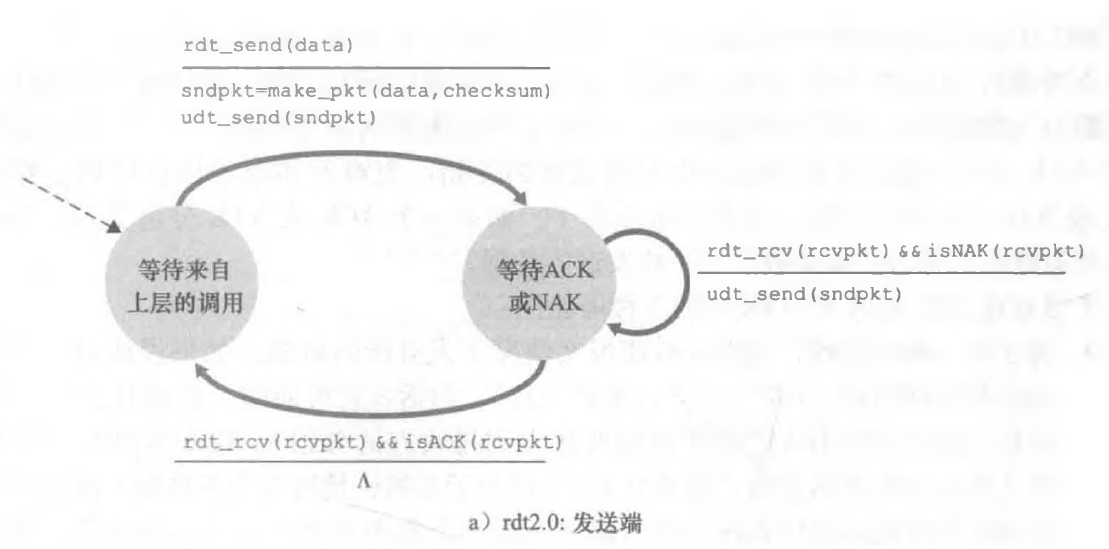
发送端就只有两种状态:一个是等待上层的请求发送,一个是等待 ACK 或者是 NAK 的到来,当上层调用的时候,发送数据之后,转为等待ACK,NAK的状态,等到接收完一个ACK或者是NAK的时候
接收端只有一种状态:那就是等待包的到来,有两种结果,一个是包无误,此时应该发送 ACK,一个是包有误,那么发送NAK。

由于这种行为,rdt2.0这样的协议被称为停等(stop-and-wait)协议。
对于这个协议,看似可以运行了,但是我们忽略了 ACK 和 NAK 出差错的情况。
考虑处理受损ACK和NAK时的3种可能性:
- 考虑在口述报文情况下人可能的做法,如果我不确定对面发送的确认请求是不是确认请求,得不到确认请求的我可能一直要等,或者是重传,而无论发送方怎么做;对方也有不确定的理解,接收方可以认为是请求结束了,或者是新的报文段过来了。
- 我们可以在 ACK 和 NAK 加入足够的检验和比特,使得发送方对于 ACK 请求不仅能够检错,还能纠错。如果分组不丢失,那么问题就解决了。
- 第三种方法就是,当发送方收到了模糊的 ACK 和 NAK 的时候,我直接选择重传,但是接收方可能不知道这个分组时新的分组还是重传的分组。
这就出现了 rdt2.1。
解决这个问题的思路很简单:在数据包中添加一位的序号字段,这个字段用实际分组序号进行 %2 填充。这样的话,如果接收方收到了和上一次序号一样的分组,马上就知道这是重传的分组了。
因此我们的 FSM 变得复杂了,状态直接变为原来的两倍。
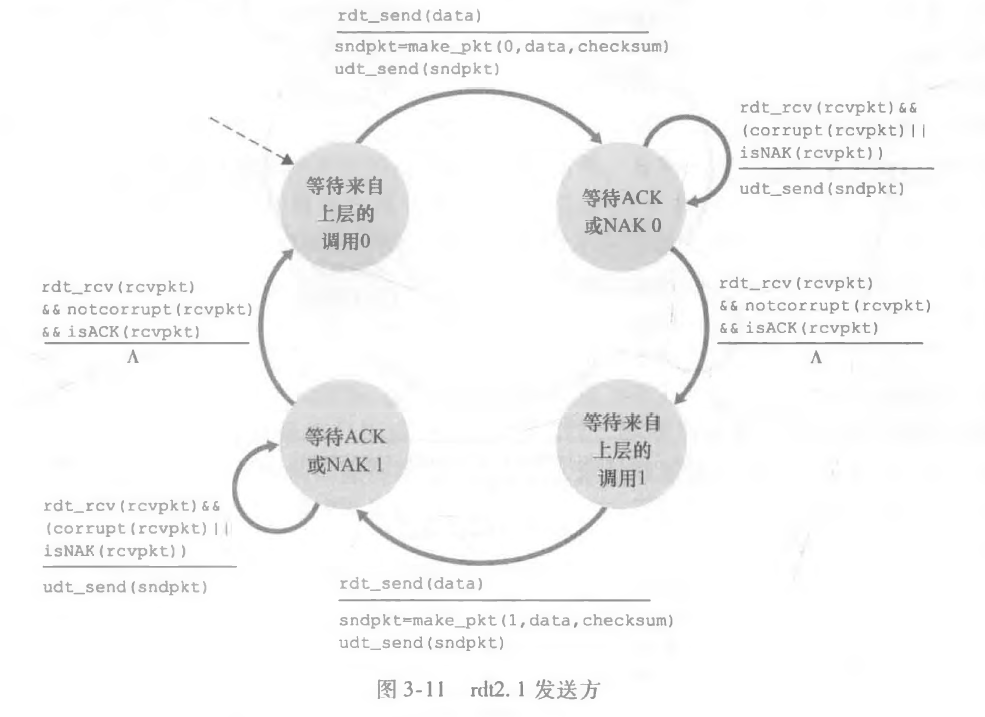
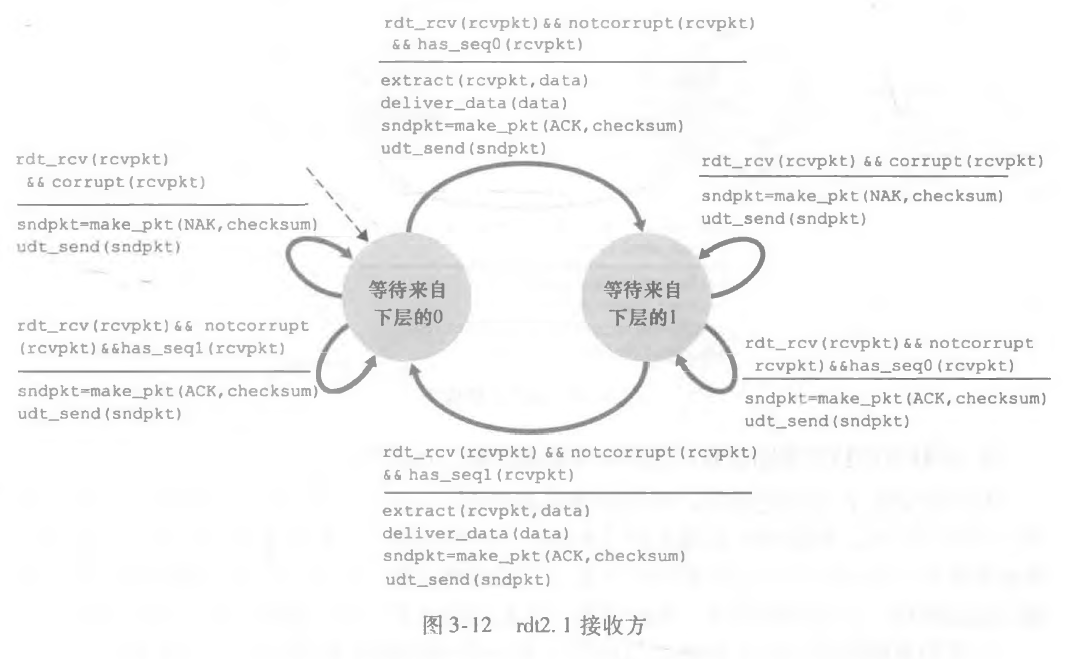
接收方同理,我从仅仅等待的状态变成了等1和等0的两种状态。
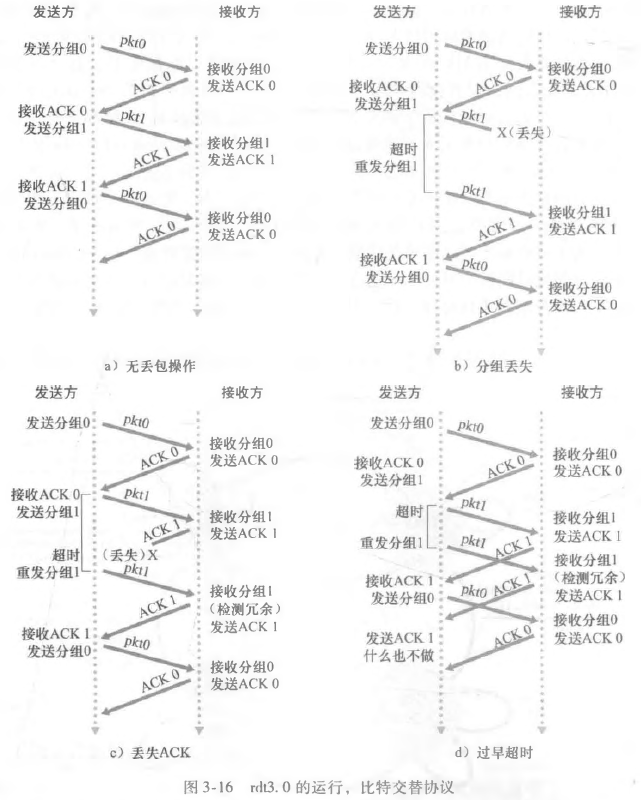
经具有比特差错的丢包信道的可靠数据传输:rdt3.0
此时,我们信道变得更恶劣了,不仅可能使分组数据出错,还有可能丢失分组。
对于这个问题,我需要添加一个计时器,如果在两倍的 RTT 时间范围内没有即时收到确认分组,那么我就认为出现了分组丢失,我选择丢失的分组进行重传即可。
对于 3.0 的协议,我只需要额外增加一个超时重传即可。
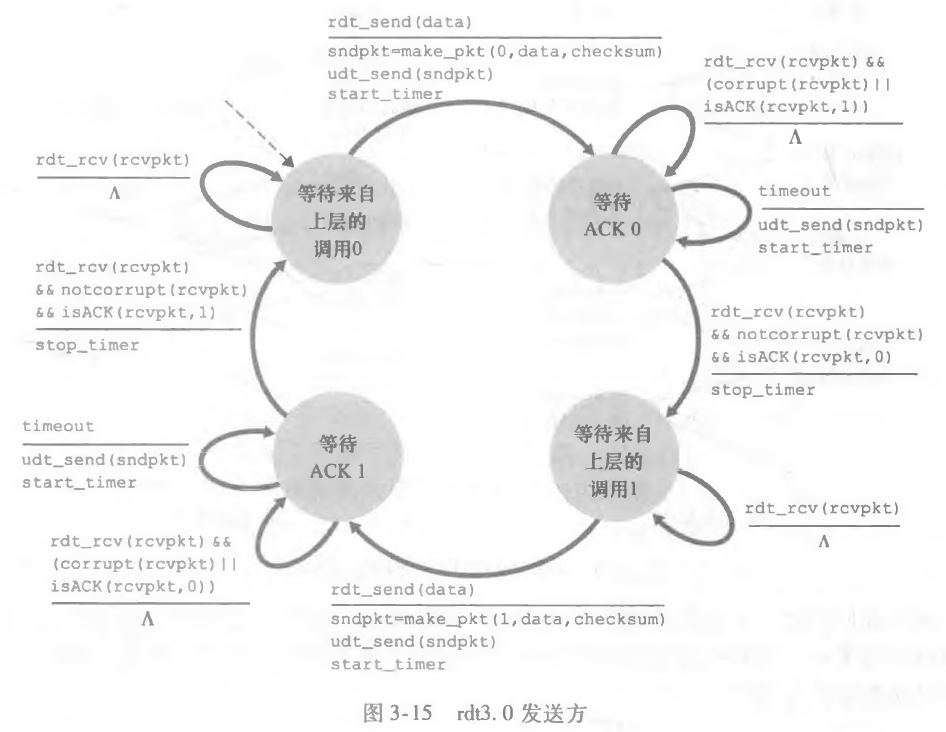
书上没有给接收方的 FSM,但是其实超时重传和接收方没有关系,因为有了超时重传之后,对于接收方来说,最大多的可能也就是可能会受到冗余的分组,我选择丢弃即可。
下图表示了在不可靠信道中出现的四种情况:
流水线可靠数据传输协议
停等协议最大的一个问题就是在于它浪费了很多的时间在等待上面,发送一个数据包之后到等待的时间中,发送方什么都没做,信道基本是空闲的。
书上举了一个例子,证实了停等协议仅仅有万分之2.7的利用率,这个利用率是极低的。
因此我们的应对措施就是使用流水线技术(pipelining):每次选择 n 个分组发送,然后等待 n 个分组的确认,期间有分组失败了那就选择重传即可。
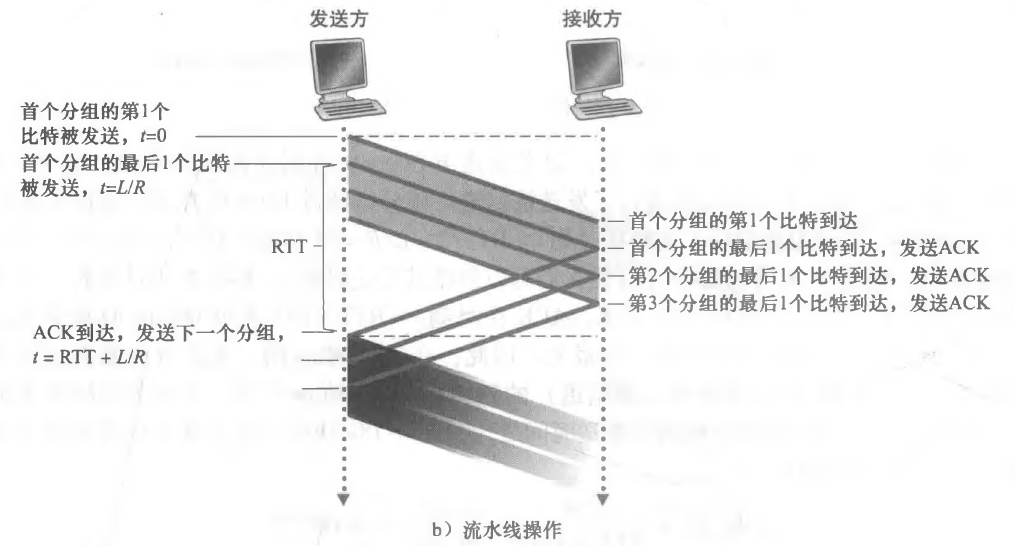
为了实现流水线技术,我们必须满足下面的一些条件。
- 我们必须增加序号的范围,以便发送方确认哪个分组被正确接收了。
- 协议的发送方和接收方两端也许不得不缓存多个分组。发送方最低限度应当能缓 冲那些已发送但没有确认的分组。接收方或许也需要缓存那 些已正确接收的分组。
- 我们需要如何处理出错的分组?错恢复有两种基本方法是:回退N步(Go Back N,GBN)和选择重传(Selective Repeat, SR)。
回退N步
首先,把流水线的分组限制一下,正在等待接收确认的分组和可发送的分组不能超过 N 组。
把所有分组按照顺序放在一个队列当中,定义一个基序号,这个序号满足这样的条件:
- 当前分组未被确认或者还未发送。
- 在当前分组之前的所有分组都已经被确认。
那么在这之后的 N 个分组就是可以发送的分组。
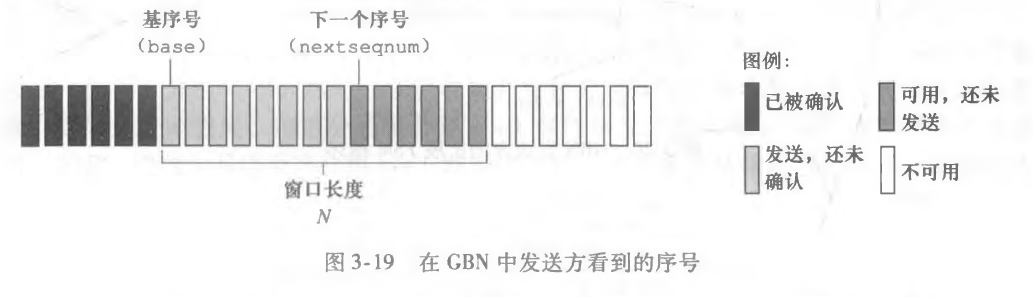
随着协议的运行,该窗口在序号空间向前滑 动。因此,N 常被称为窗口长度(window size) , GBN协议也常被称为滑动窗口协议 (sliding-window protocol)。
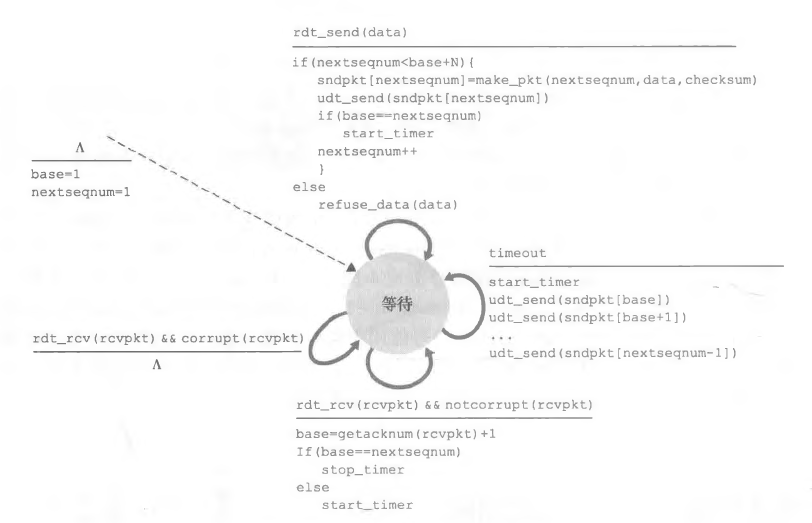
我们看看滑动窗口的发送方,我们需要响应以下的事件:
- 上层调用 send 的时候:我们需要检查滑动窗口是否已满,如果未满则可以填入窗口并发送,如果满了则可能需要告诉上层,让上层过会再发送。
- 收到一个 ACK:在GBN协议中,对序号为几的分组的确认采取累积确认(cumulative acknowledgment)的方式,表明接收方已正确接收到序号为 n 的以前且包括 n 在内的所有分组。
- 超时事件:一旦有分组超时未得到确认,即需要重传所有窗口中未被确认的分组。
那么我们发送方的状态机如下:
对于接收方,如果序号为 n 的分组被按序接收到(n-1 及其之前的分组都已经确认完成),那么发送一个分组 n 的 ack。因此发送了一个序号的 ack 则表示该序号以及之前的分组都被成功接收。
如果收到了失序分组(该分组之前的分组并未完全接收完成),那么我需要丢弃该分组(尽管很蠢,但是有道理的),因为数据交付上层需要按序交付。
这里举了一个例子:
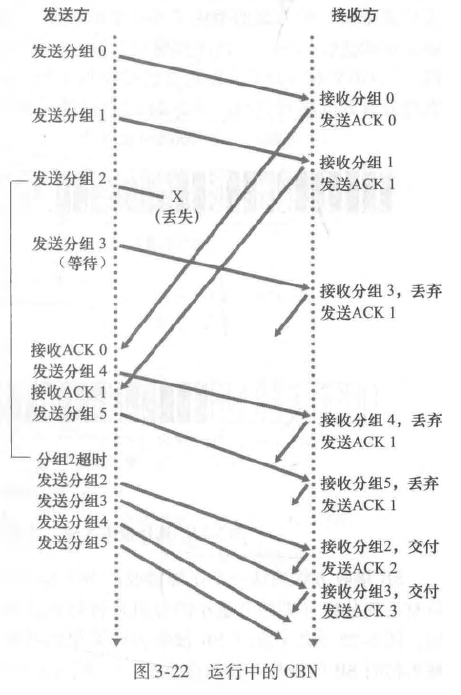
可以看到在分组 2 丢失之后,分组 3 被接收,接收方选择丢弃,并发送分组序号为 1 的 ACK,这就说明了,接收方只能按序接收。对于接收方来说,我不需要缓存任何失序分组,我收到了数据即可以马上交给上层,至始至终我只需要维护一个变量,这个变量标识了我当前希望接收的分组,因此接收方 FSM 很简单:

在这个协议中,每收到一个分组都要确认,确认序号为当前希望接收的序号 - 1。
选择重传
选择重传(SR)协议通过让发送方仅重传那些它怀疑在接收方出错(即丢失或受损)的分组而避免了不必要的重传。
它会缓存失序的分组,等到能排成有序时候交付上层,移动窗口,同时发送确认报文,使得接收方同步移动。
我们来看一个例子:
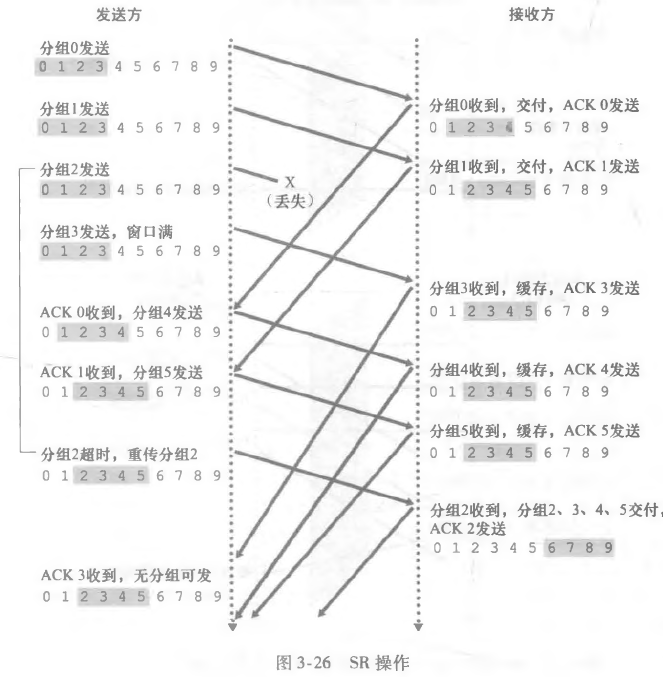
可以发现,分组 2 的丢失使得我们只需重传分组2即可,等到分组 2 确认完毕之后,窗口才可以向前滑动。
到收到冗余分组的时候,我们需要重新确认而不是置之不理。
窗口大小问题
来看一个情况:
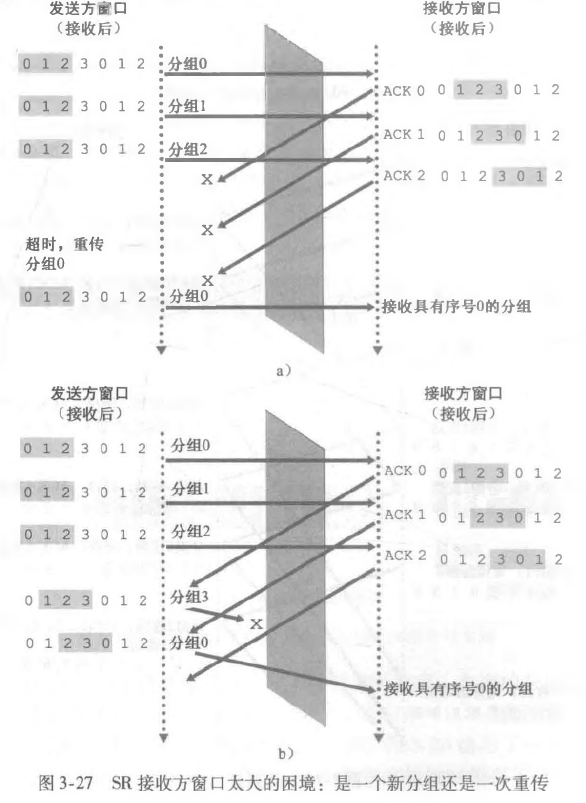
如果窗口大小和序号大小一致,很容易出现接收方不知道这个序号是一个新分组还是重传,因为都有可能。
这里其实只要窗口大小<=序号大小的一半即可。因为考虑最极端情况,滑动窗口一次滑动最多不超过自身的长度,因此我接收的分组一定是最新分组。这里举一个极端的例子:
1 | 0 1 2 3 4 5 6 7 8 0 1 2 3 4 |
假设窗口大小为 5,那么此时 0 1 2 3 4 是待发送的。我假设 1 2 3 4 都已经被确认完毕,此时 0 到达,但是在 ACK 抵达发送端之前产生了超时,而接收端因为接受了 0 1 2 3 4 滑动窗口已经移动到 5 6 7 8 0,那么此时我再接收到一个 0 我就不知道是重传还是新分组了。
所以我需要保证我一次滑动的距离不能有和我之前在窗口中相同序号的分组。
证明一下:假设序号大小为 n,窗口大小为 p。
假设当前所在分组为 i,此时的最后一个分组是 i+p-1,那么我一次最多滑动 p 的距离,此时第一个分组是 i+p,最后一个分组是 i+2p-1。那么观察上面的序列号,如果两个序号逻辑位置相差为 n+1,那么这两个序号是相同的。
不难发现,我需要让我的最右端点,落不到这个 n+1 那个点的距离。
也就是 i+n+1>i+2p-1 稍微移一下得到了 $p<\frac{n+2}{2}$,等价于 $p\le\frac{n}{2}$,也就是 p 要小于等于 n 的一半。
证毕!
这里总结一下一些机制和用途:
| 机制 | 用途和说明 |
|---|---|
| 检验和 | 用于检测在一个传输分组中的比特错误 |
| 定时器 | 用于超时/重传一个分组,可能因为该分组(或其 ACK)在信道中丢失了。由于当一个分组延时但未丢失(过早超时),或当一个分组已被接收方收到但从接收方到发送方的ACK丢失时,可能产生超时事件,所以接收方可能会收到一个分组的多个冗余副本 |
| 序号 | 用于为从发送方流向接收方的数据分组按顺序编号。所接收分组的序号间的空隙可使接收方检测出丢失的分组。具有相同序号的分组可使接收方检测出一个分组的冗余副本 |
| 确认 | 接收方用于告诉发送方一个分组或一组分组已被正确地接收到了。确认报文通常携带着被确认的分组或多个分组的序号。确认可以是逐个的或累积的,这取决于协议 |
| 否定确认 | 接收方用于告诉发送方某个分组未被正确地接收。否定确认报文通常携带着未被正确接收的分组的序号 |
| 窗口、流水线 | 发送方也许被限制仅发送那些序号落在一个指定范围内的分组。通过允许一次发送多个分组但未被确认,发送方的利用率可在停等操作模式的基础上得到增加。我们很快将会看到,窗口长度可根据接收方接收和缓存报文的能力、网络中的拥塞程度或两者情况来进行设置 |
这里再放一个题目吧:
例题:数据链路层采用选择重传协议(SR)传输数据,发送方已发送了 0~3 号数据帧,现已收到 1 号帧的确认,而 0、 2 号帧依次超时,则此时需要重传的帧数是( )。
- A.1
- B.2
- C.3
- D.4
这题选 B,只需要记住一点,SR协议只重传超时和错误的报文,没有说明 3 号数据帧的情况,说明在等待 ACK 的过程中,不需要重传。
面向连接的运输:TCP
TCP连接
TCP被称为是面向连接的(connection oriented),但是这个连接只存在于端系统并不存在于网络设备中。TCP连接也总是点对点(point-to-point)的,即在单个发送 方与单个接收方之间的连接。
TCP建立连接的具体过程是:
客户首先发送一个特殊的TCP报文段,服务器用 另一个特殊的TCP报文段来响应,最后,客户再用第三个特殊报文段作为响应。前两个报 文段不承载有效载荷,也就是不包含应用层数据。由于在这两台主机之间发送了 3个报文段,所以这种连接建立过程常被称为三次握手(three-way handshake)。
TCP可从缓存中取出并放入报文段中的数据数量受限于最大报文段长度(Maximum Segment Size,MSS)。MSS通常根据最初确定的由本地发送主机发送的最大链路层帧长度(即所谓的最大传输单元(Maximum Transmission Unit,MTU))来设置。
TCP报文段结构
下图显示了 TCP报文段的结构。

与UDP —样,首部包括源端口号和目的端口 号,它被用于多路复用/分解来自或送到上 层应用的数据。另外,同UDP—样,TCP 首部也包括检验和字段(checksum field) 。TCP报文段首部还包含下列字段:
- 32 比特的序号字段(sequence number field)和32比特的确认号字段(acknowledgment number field)),这些字段被TCP发送方和接收方用来实现可靠数据传输服务。
- 16 比特的接收窗口字段(receive window field),该字段用于流量控制。我们很快就会看到,该字段用于指示接收方愿意接受的字节数量。
- 4 比特的首部长度字段(header length field),该字段指示了以 32 比特的字为单位的TCP首部长度。由于TCP选项字段的原因,TCP首部的长度是可变的。(通常,选项字段为空,所以TCP首部的典型长度是20字节。)
- 可选与变长的选项字段(options field),该字段用于发送方与接收方协商最大报文 段长度(MSS)时,或在高速网络环境下用作窗口调节因子时使用。
- 6 比特的标志字段(flag field)。ACK比特用于指示确认字段中的值是有效的。RST、SYN和FIN比特用于连接建立和拆除。当PSH比特被置位时,就指示接收方应立即将数据交给上层。最后,URG比特用来指示报文段里存在着被发送端的上层实 体置为“紧急”的数据。紧急数据的最后一个字节由16比特的紧急数据指针字段(urgent data pointer field)指出。当紧急数据存在并给出指向紧急数据尾指针的时候,TCP必须通知接收端的上层实体。
序号和确认号
TCP把数据看成一个无结构的、有序的字节流。因为序号是建立在传送的字节流之上,而不是建立在传送的报文段的序列之上。一个报文段的序号(sequence number for a segment)因此是该报文段首字节的字节流编号。
先考虑序号,序号是字节流编址,所以假设有一个 50w 字节的文件,MSS=1000字节,那么编址如下:
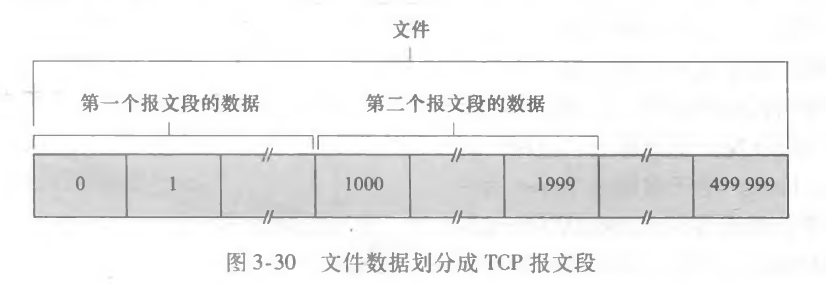
第一个报文段填充 0,第二个报文段填充 1000,第三个报文段填充 2000……以此类推。
再考虑确认号:主机 A 填充进报文段的确认号是主机 A 期望从主机 B 收到的下一字节的序号。首先认清楚一点就是 TCP 是全双工的,同一时间内,互相可能都要发送数据。我在发送数据的时候同时包含了确认号,表示我希望接收多少序号的字节数据。
再就是,TCP 是累积确认的,假如我收到了包含字节0~535的报文段,以及另一个包含字节900~1000的报文段。那么此时我发送给发送端的确认号就是536。这个时候,就谈论到了之前讨论的两种方案了,我收到了 900~1000 字节的报文段,我是选择丢弃还是保留呢?RFC 并没有规定,这个给 TCP 的实际开发人员去解决了。而实际上,出于对网络带宽的考虑,我们选择保留它,并等待中间的报文到来。
所以我这么认为:ACK字段表明我接下来希望接收的分组的数据的起始位置,seq 字段表示我当前的数据是从什么位置开始的。
Telnet:序号和确认号的一个学习案例
Telnet在成功登录到终端之后,我们输入一个字符,这个字符同样会回显到我们的命令行中。这种回显(echo back)用于确保由Telnet用户 发送的字符已经被远程主机收到并在远程站点上得到处理。
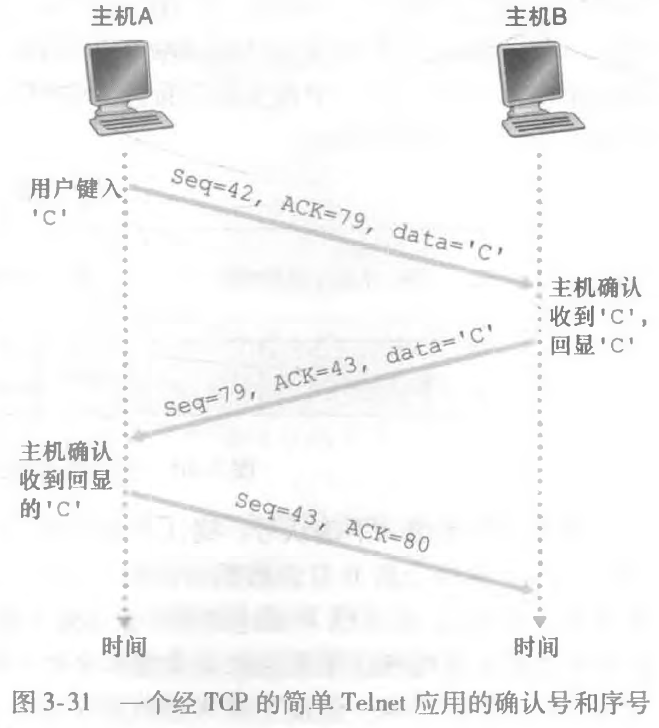
用户键入 C 的时候,发送了一个 seq=42,ACK=79 的包并携带了一个字符 C。对面主机收到 C 之后,确认收到并把该字符放到了确认包中,此时发送的 seq=79,ACK=43。主机随后确认收到的回显 C。
对客户到服务器的数据的确认被装载在一个 承载服务器到客户的数据的报文段中;这种确认被称为是被捎带(piggybacked)在服务器 到客户的数据报文段中的。
然后就是第三个包确认字段,seq 被填上了 43,虽然它没有数据。
往返时间的估计与超时
我们还需要解决报文丢失重传的问题,这里有个问题就是多少的时间比较好呢,多少时间没有收到确认我才认为报文发生了丢失呢。显然,超时间隔必须大于该连接的往返时间(RTT),即从一个报文段发出到它被确认的时间。否则会造成不必要的重传。但是这个时间间隔到底应该是多大呢?刚开始时应如何估计往返时间呢?是否应该为所有未确认的报文段各设一个定时器?
估计往返时间
一堆数学证明,不细看了……
设置和管理重传超时间隔
通过一个公式计算出合理的超时时间去设置,超时时间尽量大于理论 RTT。
可靠数据传输
TCP在IP不可靠的尽力而为服务之上创建了一种可靠数据传输服务。
TCP的可靠数据传输服务确保一个进程从其接收缓存中读出的数据流是 无损坏、无间隙、非冗余和按序的数据流;即该字节流与连接的另一方端系统发送出的字节流是完全相同。
我们来看看 TCP 的发送方逻辑:

这里接收方主要处理三个事件,一个是收到数据,生报文段,启动定时,发送报文。第二个是定时器超时,重传具有最小仍未应答的序号报文段。第三个就是收到了 ACK,因为TCP采用累计确认,因此我们直接把 send_base 转移到当前的确认号上来,当然它只能变大不能变小。如果说,当前还有已发送未应答的报文,那么重新开启定时器。
考虑有趣的情况
第一种情况:
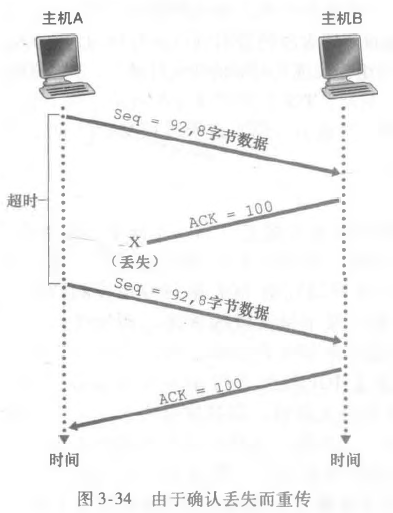
由于确认的丢失而重传
接着考虑如下情况:
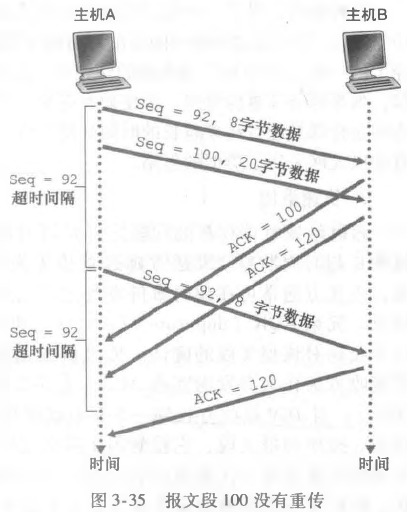
如果超时间隔比较短,那么第一个报文必定超时,在超时的时间段会重传,然后继续等待下一次超时。如果此时收到了第二个报文段的确认,那么接下来第一个第二个报文都不会再被重传,因为收到第二个报文的确认表示第一个报文也正确收到了。在第一个报文超时事件内收到了第二个报文,即使看起来第二个报文也超时到达,但是在超时重传的时间段收到了 ACK 也不会再重传第二个报文了。
再考虑如下情况:
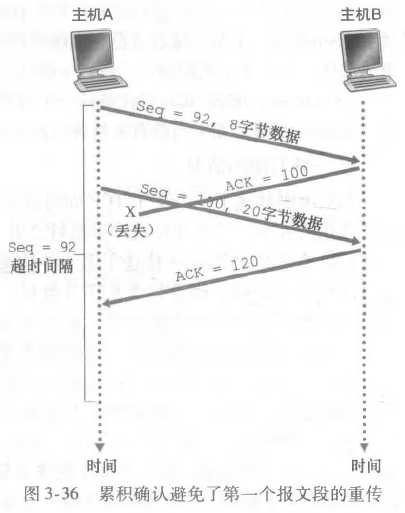
第一个报文的确认丢失,但是收到了第二个报文的确认,由于累计确认机制,我不会重传第一个报文。
超时间隔加倍
就是实际TCP的一个机制,如果一个报文发生了超时,那么我会重传该报文并把超时计时器加倍。比如设置 0.75 秒超时了,下一次重传我设置成 1.5 秒,如果这次依然超时,我把超时间隔设置为 3 秒。
考虑就是 TCP,这种修改提供了一个形式受限的拥塞控制,定时器过期很可能是由网络拥塞引起的,即太多的分组到达源与目的地之间路径上的一台(或多台)路由器的队列中,造成分组丢失或长时间的排队时延。在拥塞的时 候,如果源持续重传分组,会使拥塞更加严重。
快速重传
是指这样的一个机制:如果对于一个报文的 ACK 序号连续收到了三次,那么认为这个报文已经丢失,并直接把这个报文重传,因为 ACK 值指的是我下一次期望接收的字节序列,考虑下面的情况:
- 发送方依次发送
seq=1,2,3,4,5的报文。 - 1收到,接收端回复
ACK=2,第一次收到ACK=2。 - 2 因为某些原因丢失了。
- 3收到,由于
seq=2的分组还未确认,于是还是回复ACK=2,收到一个冗余ACK。 - 4收到,由于
seq=2的分组还未确认,于是继续回复ACK=2,收到两个冗余ACK。 - 5收到,由于
seq=2的分组还未确认,于是接着回复ACK=2,收到三个冗余ACK。
此时我们已经接收三个相同的冗余 ACK 分组,于是认为这个分组丢失,不等定时器过期,直接重传这个分组。
是回退N步还是选择重传
首先 TCP 是累积确认的,正确接收但失序的报文段是不会被接收方逐个确认。这看起来和 GBN 差不多但是 TCP 会保留失序分组,进一步假设对分组 n<N 的 ACK 丢失,但是其余 N-1个确认报文在分别超时以前到达发送端,这时又会发生的情况。在该例中,GBN不仅会重传分组 n,还会重传所有后继的分组 n+1,n+2,…,N。 在另一方面,TCP将重传至多一个报文段,即报文段 n。此外,如果对报文段 n+1的 ACK 在分组 n 超时之前到达, TCP甚至不会重传分组 n。
流量控制
流量控制是一个速度匹配服务,即发送方的发送速率与接收方应用程序的读取速率相匹配。TCP发送方也可能因为IP网络的拥塞而被遏制;这种形式的发送方的控制被称为拥塞控制(congestion control)。在讲流量控制的时候,下面假设 TCP 的实现是丢失所有失序分组来实现的。
TCP通过让发送方维护一个称为接收窗口(receive window)的变量来提供流量控制。接收窗口用于给发送方一个指示一一该接收方还有多少可用的缓存空间。因为 TCP是全双工通信,在连接两端的发送方都各自维护一个接收窗口。我们在文件传输的情况下研究接收窗口。假设主机 A 通过一条TCP连接向主机 B 发送一个大文件。主机B为该连接分配了一个接收缓存,并用 RcvBuffer 来表示其大小。
定义如下:
- LastByteRead:主机 B 上的应用进程从缓存读出的数据流的最后一个字节的编号。
- LastByteRcvd:从网络中到达的并且已放入主机 B 接收缓存中的数据流的最后一个字节的编号。
很明显,我必须始终满足 LastByteRcvd-LastByteRead<=RcvBuffer。
接收窗口用 rwnd 表示,根据缓存可用空间的数量来设置:rwnd = RcvBuffer - [LastByteRcvd - LastByteRead]由于该空间是随着时间变化的,所以 rwnd 是动态的。
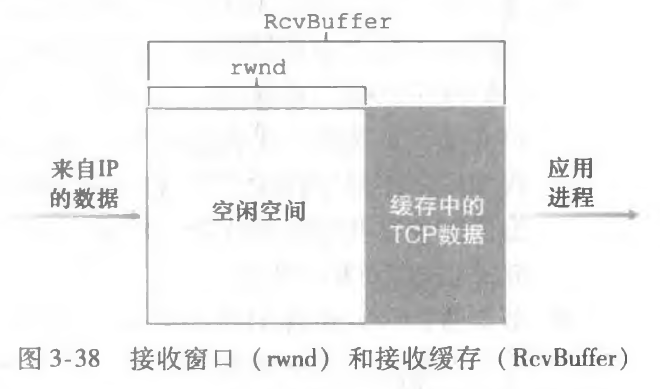
在 TCP 的报文段中,有一个字段就是接收窗口(rwnd),主机 B 会通知 A 它有多少大小的接收窗口。
开始时,主机 B 设定 rwnd = RcvBuffer。主机A轮流跟踪两个变量,LastByteSent 和 LastByteAcked,这两个变量的意义很明显。 注意到这两个变量之间的差 LastByteSent - LastByteAcked,就是主机A发送到连接中但未被确认的数据量。
通过将未确认的数据量控制在值 rwnd 以内,就可以保证主机 A 不会使主机B的接收缓存溢出。因此,主机 A 在该连接的整个生命周期须保证:
LastByteSent-LastByteAcked<=rwnd
看似没有问题了,但是实际上还是有问题的,因为当 rwnd=0 的时候,事实上, A 不能再发送数据了,如果 B 不主动告知我 rwnd 有新的空位了,我是不会知道主机 B 还有空闲的窗口的。因此 TCP 规定,如果 rwnd=0,那么 A 只能发送只有一个字节数据的报文段,使得双方可以继续交换信息。
TCP连接管理
建立TCP连接
我们来看看TCP建立连接的一个过程:
- 客户端的TCP首先向服务器端的TCP发送一个特殊的TCP报文段。该报文段中不包含应用层数据。但是在报文段的首部中的一个标志位(即SYN比特)被置为1,客户会随机地选择一个初始序号(client_isn),并将此编号放置于该起始的TCP SYN报文段的序号字段中。
- 服务器会从该数据报中提取出TCP SYN报文段,为该TCP连接分配TCP缓存和变量,并向该客户TCP发送允许连接的报文段。返回包也不包含任何应用层数据,首先 syn 也会被置为 1,ACK 确认字段 = client_isn + 1。并给出自己的序号 server_isn。表明了:我收到了你发起建立连接的SYN分组,该分组带有初始序号 client_isn。我同意建立该连接。我自己的初始序号是 server_isn。该允许连接的报文段被称为SYNACK报文段(SYNACK segment)。
- 在收到SYNACK报文段后,客户也要给该连接分配缓存和变量。客户主机则向服务器发送另外一个报文段;这最后一个报文段对服务器的允许连接的报文段进行了确认,同时携带了我请求的数据。
这三个步骤被称为三次握手(three-way handshake)。
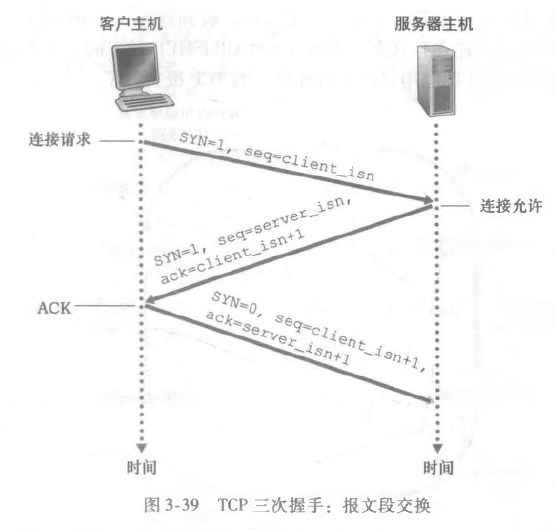
至于为什么需要三次握手,大概是为了交流一些信息吧,比如窗口大小,初始序号等等的信息。
关闭TCP连接
大概可以用下面的图描述:
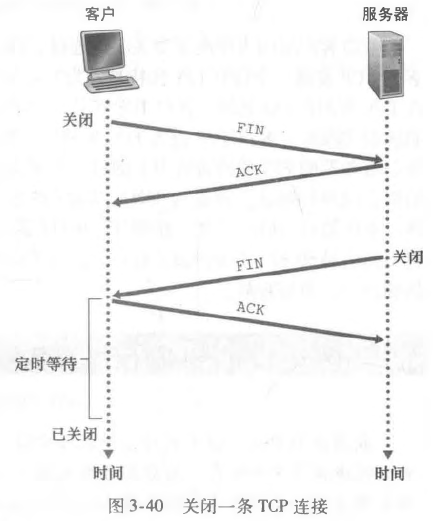
大概就是,其中一方发送 FIN=1 的报文段表示我要关闭连接了,然后会收到另一方的确认,然后另一方也会发一个 FIN=1 的数据报表示我要关闭连接了,随后也会收到这一方的确认。
至于为什么要 4 次,考虑这样一种情况:
两个人聊着聊着。
- 其中一个人突然想走了(我想关闭连接了)
- 就跟他说:我要走了(发送FIN=1的报文)
- 另一个人说:好的我知道了(发送ACK回去)
- 但是此时你的不告而别可能导致另一个人还有一些话没跟你说完,他可能还有一些事情要交代,而你也比较清楚可能是一些很重要的事情,因此此时你不会马上退出。当然,正常情况你说走了他可能也没什么事了,就也说一句:我也走了(对面向你发送FIN=1的报文)
- 此时你知道了,他也没什么事要跟你交代,你也礼貌性回一句:好的我知道了(对FIN=1发送ACK确认)。
大概就是这样的一种情况吧,所以TCP取消连接需要四次挥手。
在 TCP 连接到关闭的过程中,客户端会经历如下的状态:
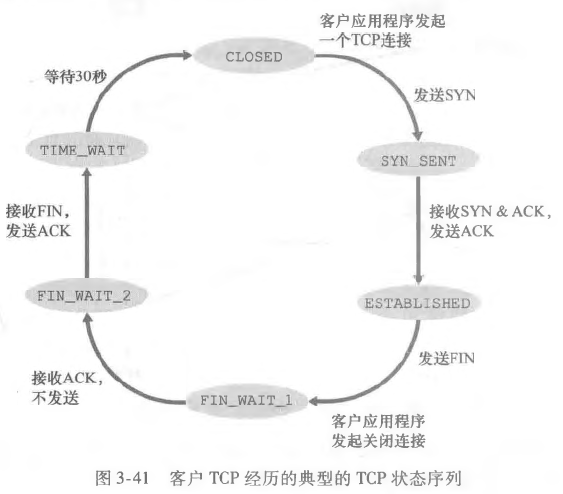
而服务端经历如下的状态变化:
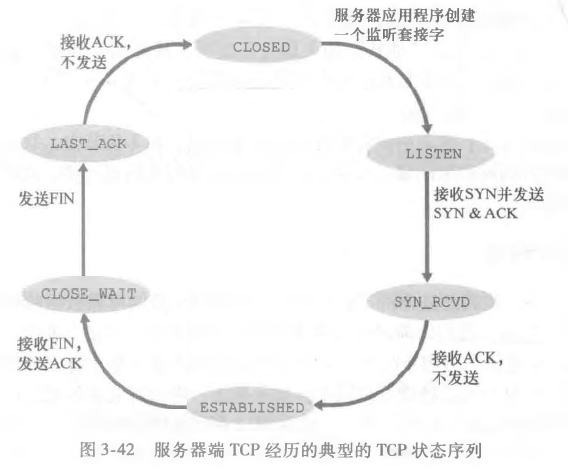
我们来考虑当一台主机接收到一个TCP报文段,其端口号或源IP地址与该主机上进行中的套接字都不匹配的情况。如果一个主机的 80 端口没有运行任何服务,则该主机将向源发送一个特殊重置报文段,该TCP报文段将RST标志位,等于在告诉源主机:我没有对应的套接字,请不要发送报文段了,我们在连接服务器的时候,经常遇到的 connection reset 就是指的这个 RST。
基于此我们可以写一个端口扫描器:
- 如果接收到了 ACK 报文,表示这个端口有可用服务。
- 如果收到了 RST 报文,表示这个端口没有可用服务。
- 如果什么也没收到,表示数据包被防火墙阻拦。
拥塞控制原理
拥塞原因与情况
通过分析三个例子来理解发生拥塞的情况:
两个发送方和一台具有无穷大缓存的路由器
其中一种网络拥塞的情况:当分组的到达速率接近链路容量时,分组经历巨大的排队时延。
两个发送方和一台具有有限缓存的路由器
另一种网络拥塞的情况:即发送方必须执行重传以补偿因为缓存溢出而丢弃(丢失)的分组。
具有多跳路径的情况
最后一种:当一个分组沿一条路径被丢弃时,每个上游路由器用于转发该分组到丢弃该分组而使用的传输容量最终被浪费掉了 。
拥塞控制的方法
端到端拥塞控制
因为网络层不给运输层反馈,因此TCP报文段的丢失(通过超时或3次冗余确认而得知)被认为是网络拥塞的一个迹象,TCP 会相应地减小其窗口长度。
网络辅助的拥塞控制
第一种方式的通知通常采用了一种阻塞分组(choke packet)的形式(主要是说:“我拥塞了!”)。
第二种形式的通知是,路由器标记或更新从发送方流向接收方的分组中的某个字段来指示拥塞的产生。一旦收到一个标记的分组后,接收方就会向发送方通知该网络拥塞指示。
TCP拥塞控制
首先明白一点:TCP必须使用端到端拥塞控制而不是使网络辅助的拥塞控制,因为IP层不 向端系统提供显式的网络拥塞反馈。(20203.04.05补)
经典的TCP拥塞控制
发送方额外维护一个拥塞窗口(cwnd),使得已发送但未被确认的字节数在 min{rwnd,cwnd} 以内。
如何在不拥塞的情况下充分利用网络带宽呢?
- 一个丢失的报文表示拥塞,因此需要降低发送速率。。
- 确认的报文段表示该网络正常发送接收,因此可以增大发送方的速率。
让我们具体看看广为流传的TCP拥塞控制算法,它有两个阶段,一个可选阶段:
- 慢启动
- 拥塞避免
- 快速重传(可选)
慢启动
慢启动开始阶段,会把cwnd置为1,每次的成功接收会使得cwnd翻倍。
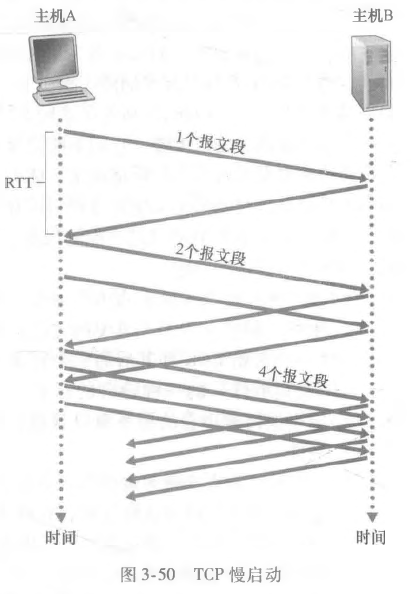
虽然叫慢启动,但是发送速度是程指数增长的。
当遇到了超时事件的时候,会把 ssthresh 状态变量设置为拥塞窗口的一半,并把 cwnd 重新设置为1。
当 cwnd>=ssthresh 的时候,马上进入拥塞避免模式,因为此时贸然翻番可能会导致拥塞,因此这里我们每次成功收完一 cwnd 个ACK之后会把 cwnd 的值加1。
如果检测到三个冗余 ACK 则会进入快速恢复模式。
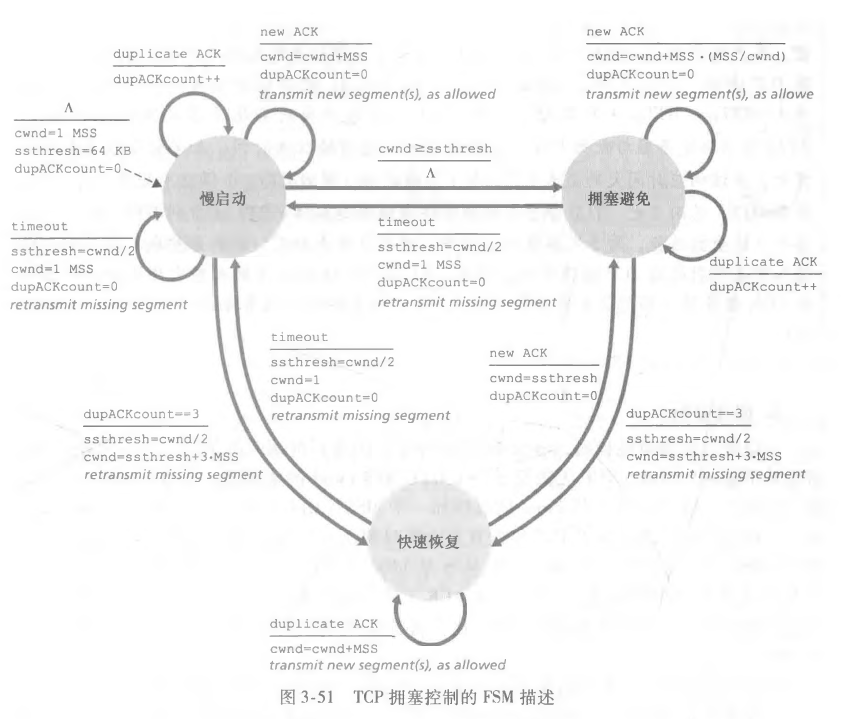
上图是 TCP 拥塞控制算法的 FSM 描述。
拥塞避免
每个到达 ACK 会将 cwnd 的值增加 1/cwnd MSS。
在这个阶段,如果超时,则回到慢启动状态,设置 ssthresh 的值并把 cwnd 重新设置为1。
收到三个冗余 ACK 则也进入快速恢复模式,并把 cwnd=ssthresh+3MSS。
快速恢复
这个阶段中,每收到一个冗余ACK会使得 cwnd+1 MSS。
超时会回到慢启动状态,同样设置 ssthresh 的值并把 cwnd 重新设置为1。
收到确认 ACK 的时候回到拥塞避免状态,让 cwnd=ssthresh。
TCP拥塞控制:回顾
通常被描述为:加性增,乘性减。
小节
因特网中的UDP协议就是这样一种不提供不必要服务的运输层协议。在另一 个极端,运输层协议能够向应用程序提供各种各样的保证,例如数据的可靠交付、时延保证和带宽保证。