CS:APP第十一章学习
开始学 CSAPP的第十一章
逐步更新:
- 2023-02-06:开始写
梗概
这一章就是讲了网络编程的实用性,我们身边要用到的所有跟网络有关的服务都需要用到网络编程,包括了浏览 Web、发送 email 信息或是玩在线游戏,你就正在使用网络应用程序。
这一节综合了前面一些理论知识,最后会做出一个成品来,期待ing。
客户端/服务器编程模型
客户端/服务器编程模型(Client/Server)是网络编程的基本模型,模型中的基本操作是事务(transaction)

一个客户端—服务器事务由以下四步组成:
- 当一个客户端需要服务时,它向服务器发送一个请求,发起一个事务。例如,当 Web 浏览器需要一个文件时,它就发送一个请求给 Web 服务器。
- 服务器收到请求后,解释它,并以适当的方式操作它的资源。例如,当 Web 服务器收到浏览器发出的请求后,它就读一个磁盘文件。
- 服务器给客户端发送一个响应,并等待下一个请求。例如,Web 服务器将文件发送回客户端。
- 客户端收到响应并处理它。例如,当 Web 浏览器收到来自服务器的一页后,就在屏幕上显示此页。
这里需要认识到一点:客户端和服务器是进程而不是一个主机,一台主机可以同时运行许多不同的客户端和服务器,而且一个客户端和服务器的事务可以在同一台或是不同的主机上。无论客户端和服务器是怎样映射到主机上的,客户端—服务器模型都是相同的。
网络
对于主机而言,网络只是一个 IO 设备。
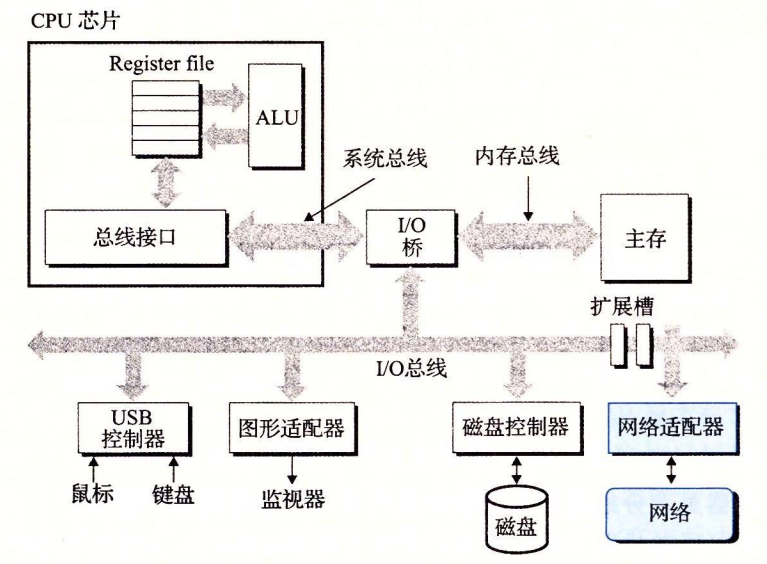
网络设备和内存的交换是 DMA (直接内存访问)方式交换。
局域网
在物理上而言,网络是按照地理远近组成的层次系统,最底层是 LAN(Local Area Network,局域网),迄今为止,最流行的局域网技术是以太网(Ethernet),它的适应力极强。
一个以太网段(Ethernet segment)包括一些电缆(通常是双绞线)和一个叫做集线器的小盒子,如图 11-3 所示。以太网段通常跨越一些小的区域,例如某建筑物的一个房间或者一个楼层。每根电缆都有相同的最大位带宽,通常是 100 Mb/s 或者 1 Gb/s。
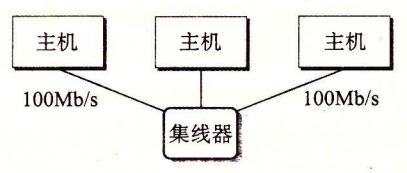
集线器的工作原理就是:在一个的端口所读到的内容会发给其它所有端口,因此在对一个集线器发送数据会让与之相连的所有主机看到发送的内容。
每个以太网适配器都有一个全球唯一的 48 位地址(MAC地址),它存储在这个适配器的非易失性存储器上。
一台主机可以发送一个标识了目的 MAC 地址的帧到网段内的任何主机以及其它一些元数据,每个主机都能看到同网段发送的任何消息,但是一般只有 MAC 地址一致的主机会读取这个帧。
可以使用网桥将多个网段连接成较大的局域网,称为桥接以太网。
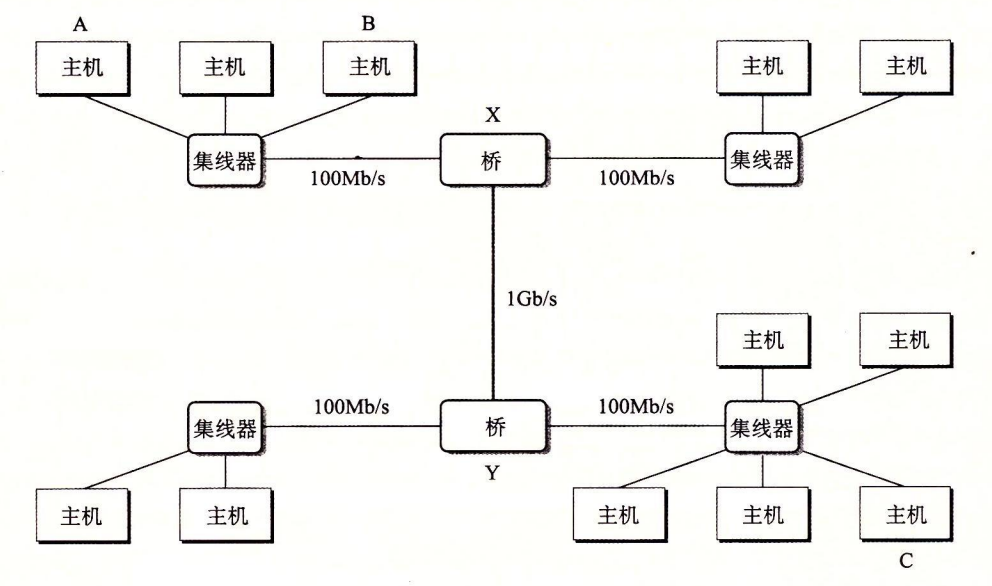
网桥与集线器不同,有自适应算法,它们随着时间自动学习哪个主机可以通过哪个端口可达,然后只在有必要时,有选择地将帧从一个端口复制到另一个端口。
为了简化局域网的表示,我们将把集线器和网桥以及连接它们的电缆画成一根水平线:
广域网
在层次的更高级别中,多个不兼容的局域网可以通过叫做路由器(router)的特殊计算机连接起来,组成一个 internet(互联网络)。每台路由器对于它所连接到的每个网络都有一个适配器(端口)。路由器也能连接高速点到点电话连接,这是称为 WAN(Wide-Area Network,广域网)
下图是三台路由器连接起两个局域网和两个广域网:
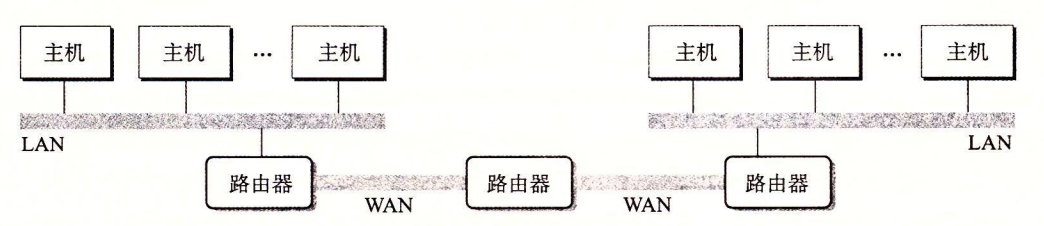
互联网最重要的特性是能兼容不同技术的局域网和广域网,每台主机都是物理相连,但是由于网络的差异,我们需要统一一个规则。解决办法就是设定一个协议,让所有计算机和路由器都遵守这个协议,这种协议控制主机和路由器如何协同工作来实现数据传输。这种协议必须提供两种基本能力:
- 命名机制 :不同的局域网和广域网有不同的方式分配地址。互联网络协议要求定义一种一致的主机地址格式消除了这些差异,每台主机需要分配至少一个互联网络地址来唯一地标识这个主机。
- 传送机制 :在电缆上编码位和将这些位封装成帧方面,不同的联网技术有不同的和不兼容的方式。互联网络协议通过定义一种把数据位捆扎成不连续的片(称为包)的统一方式,从而消除了这些差异。一个包是由包头和有效载荷组成的,其中包头包括包的大小以及源主机和目的主机的地址,有效载荷包括从源主机发出的数据位。
传送数据包的时候经历了以下步骤
- 发送主机的进程通过系统调用,将发送的数据从用户区拷贝到内核区。
- 主机上的协议软件再通过在数据前添加网络协议,添加 LAN1 的帧头,当然在此之前还会封装互联网包头。
- LAN1 适配器复制该帧到网络上,交给路由器
- 当此帧到达路由器时,路由器的 LAN1 适配器从电缆上读取它,并把它传送到协议软件。
- 路由器剥落 LAN1 的帧头,替换上寻址到主机 B 的 LAN2 的帧头,并传送给 LAN2 的适配器,这里猜测可能会有一个广播的方式去传送给 LAN3 LAN4 之类的,又或者是路由器对自己的网络很了解,因此不需要广播。
- 路由器把该帧传送到 LAN2 网络上。
- 该帧到达主机 B 时,读取这个帧,传送到协议软件
- 脱落包头和帧头,得到数据。最终,服务会将对应的数据拷贝到对应服务的虚拟地址空间。
当然了,在这里完全不用考虑很多特殊的情况,我们只要知道它在顺畅的状况下怎么通信就可以了。
全球 IP 因特网
全球 IP 因特网是最著名和最成功的互联网络实现,下图展示了两个在互联网上的主机的通信:
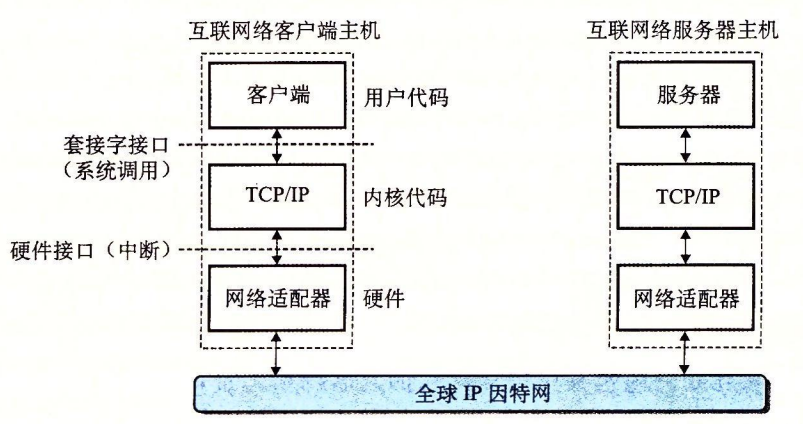
每台因特网主机都运行实现 TCP/IP 协议的软件,几乎每个现代计算机系统都支持这个协议。因特网的客户端和服务器混合使用套接字接口函数和 Unix l/O 函数来进行通信。
TCP/IP 实际是一个协议族,其中每一个都提供不同的功能。例如,IP 协议提供基本的命名方法和递送机制,这种递送机制能够从一台因特网主机往其他主机发送包,也叫做数据报(datagram)。
- IP 机制从某种意义上而言是不可靠的,因为,如果数据报在网络中丢失或者重复,它并不会试图恢复。
- UDP(Unreliable Datagram Protocol,不可靠数据报协议)稍微扩展了 IP 协议,这样一来,包可以在进程间而不是在主机间传送。
- TCP 是一个构建在 IP 之上的复杂协议,提供了进程间可靠的全双工(双向的)连接。
为了简化讨论,我们将 TCP/IP 看做是一个单独的整体协议。
从程序员的角度,我们可以把因特网看做一个世界范围的主机集合,满足以下特性:
- 主机集合被映射为一组 32 位的 IP 地址。
- 这组 IP 地址被映射为一组称为因特网域名(Internet domain name)的标识符。
- 因特网主机上的进程能够通过连接(connection)和任何其他因特网主机上的进程通信。
IP地址
ip地址数据类型由一个结构体实现
1 | /* IP address structure */ |
但是其实这个应该被定义为一个标量类型才对,但是现在更改的话会有大量的网络应用受到波及。
这就导致了我们在写套接字的时候,有一堆的结构体要处理,会感觉很麻烦。
因为因特网主机可以有不同的主机字节顺序,TCP/IP 为任意整数数据项定义了统一的网络字节顺序(network byte order)(大端字节顺序),例如 IP 地址,它放在包头中跨过网络被携带。在 IP 地址结构中存放的地址总是以(大端法)网络字节顺序存放的,即使主机字节顺序(host byte order)是小端法。Unix 提供了下面这样的函数在网络和主机字节顺序间实现转换。
一般我们机器上的整数类型都是小端法存储,放到网络上传输时需要反一下。
UNIX 提供了以下函数供我们转换。
1 |
|
IP 地址通常是以一种称为点分十进制表示法来表示的,这里,每个字节由它的十进制值表示,并且用句点和其他字节间分开。例如,128.2.194.242 就是地址 0x8002c2f2 的点分十进制表示。在 Linux 系统上,你能够使用 HOSTNAME 命令来确定你自己主机的点分十进制地址:
1 | linux> hostname -i |
应用程序使用 inet_pton 和 inet_ntop 函数来实现 IP 地址和点分十进制串之间的转换。
1 |
|
也是终于明白这玩意怎么玩的了。
1 |
|
而 inet_ntop 函数就是会把 src 所指向的四字节整数代表的 IP 地址,把它转为点分十进制 ip 地址,并把最多 size 长度的字符串拷贝到 dst 当中。
域名
因特网客户端和服务器互相通信时使用的是 IP 地址。然而,对于人们而言,大整数是很难记住的,所以因特网也定义了一组更加人性化的域名(domain name),以及一种将域名映射到 IP 地址的机制。域名是一串用句点分隔的单词(字母、数字和-),例如 whaleshark.ics.cs.emu.edu。
域名集合形成了一个层次结构,每个域名编码了它在这个层次中的位置。通过一个示例你将很容易理解这点。下图展示了域名层次结构的一部分:
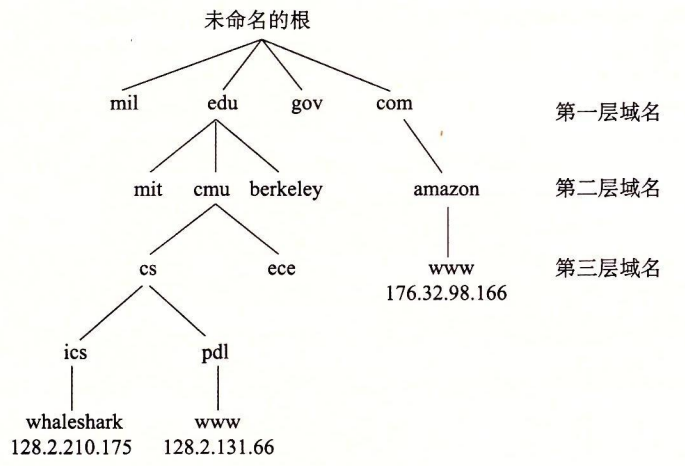
层次结构可以表示为一棵树。树的节点表示域名,反向到根的路径形成了域名。子树称为子域(subdomain)。层次结构中的第一层是一个未命名的根节点。下一层是一组一级域名(first-level domain name),由非营利组织 ICANN(Internet Corporation for Assigned Namesand Numbers,因特网分配名字数字协会)定义。常见的第一层域名包括 com、edu、gov、org 和 net。
下一层是二级(second-level)域名,例如 cmu.edu,这些域名是由 ICANN 的各个授权代理按照先到先服务的基础分配的。一旦一个组织得到了一个二级域名,那么它就可以在这个子域中创建任何新的域名了,例如 cs.cmu.edu。
举个例子就是:有一个顶级域名服务器,它知道 .com 的所有子域,并且所有计算机都承认它的解析结果。那么我大腾讯先来这注册了一个 qq.com,这个域名解析到我腾讯的一个服务器,那么 qq.com 的所有子域就归这个服务器管了,比如 weixin.qq.com,lol.qq.com 等等子域,当然也可以由 qq.com 这个服务器另外指定一个域名服务器,在域名服务器添加一条新的记录就可以进行解析操作了。
每台因特网主机都有本地定义的域名 localhost,这个域名总是映射为回送地址(loopback address)127.0.0.1:
域名可以映射一个或者多个 IP 地址,一个 IP 地址也可以有多个域名。
因特网连接
因特网客户端和服务器通过在连接上发送和接收字节流来通信,他们是点对点,全双工,可靠的通信。
一个套接字是连接的一个端点。每个套接字都有相应的套接字地址,是由一个因特网地址和一个 16 位的整数✦端口✦组成的,用 ip:port 来表示。
当客户端发起连接时,会随机分配一个临时端口,服务器的接收通常是知名端口。例如,Web 服务器通常使用端口 80,而电子邮件服务器使用端口 25。每个具有知名端口的服务都有一个对应的知名的服务名。例如,Web 服务的知名名字是 http,email 的知名名字是 smtp。文件 /etc/services 包含一张这台机器提供的知名名字和知名端口之间的映射。
一个连接是由它两端的套接字地址唯一确定的。这对套接字地址叫做套接字对(socket pair),由下列元组来表示:
(cliaddr:cliport, servaddr:servport)
其中 cliaddr 是客户端的 IP 地址,cliport 是客户端的端口,servaddr 是服务器的 IP 地址,而 servport 是服务器的端口。例如,下图展示了一个 Web 客户端和一个 Web 服务器之间的连接。

在这个示例中,Web 客户端的套接字地址是
128.2.194.242:51213
其中端口号 51213 是内核分配的临时端口号。Web 服务器的套接字地址是
208.216.181.15:80
其中端口号 80 是和 Web 服务相关联的知名端口号。给定这些客户端和服务器套接字地址,客户端和服务器之间的连接就由下列套接字对唯一确定了:
(128.2.194.242:51213, 208.216.181.15:80)
套接字接口
套接字接口(socket interface)是一组函数,它们和 Unix I/O 函数结合起来,用以创建网络应用。
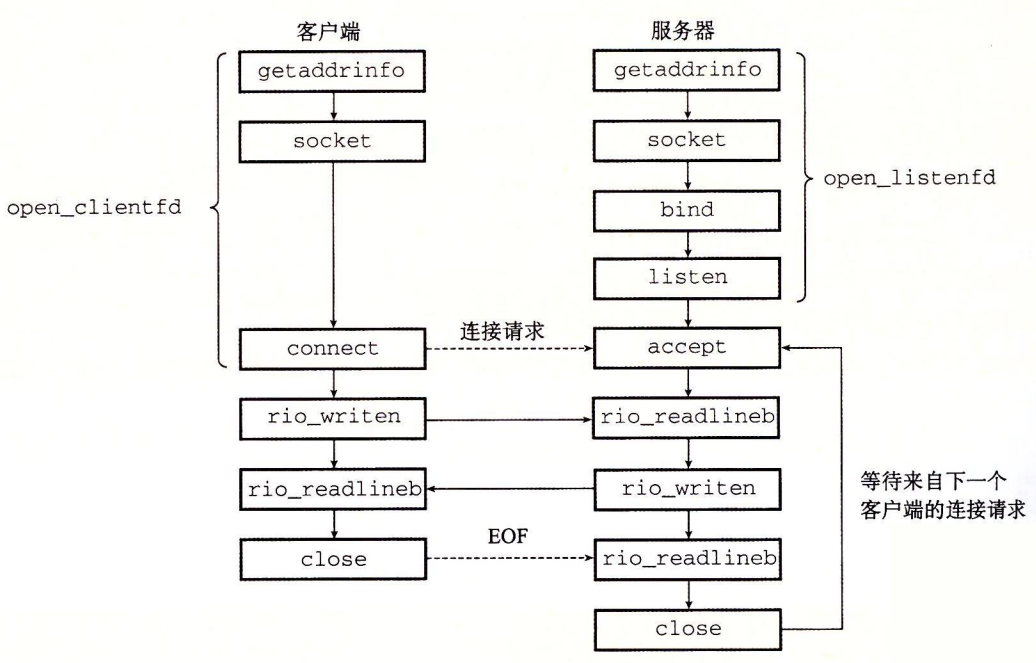
套接字地址结构
对于程序员来说,套接字其实就是一个打开的文件描述符。
因特网的套接字地址存放在如图 11-13 所示的类型为 sockaddr_in 的 16 字节结构中。对于因特网应用,sin_family 成员是 AF_INET,sin_port 成员是一个 16 位的端口号,而 sin_addr 成员就是一个 32 位的 IP 地址。IP 地址和端口号总是以网络字节顺序(大端法)存放的。
1 | /* IP socket address structure */ |
socket 函数
客户端和服务器使用 socket 函数来创建一个套接字描述符(socket descriptor)。
1 |
|
example:
1 | clientfd = socket(AF_INET, SOCK_STREAM, 0); |
其中,AF_INET 表明我们正在使用 32 位 IP 地址,而 SOCK_STREAM 表示这个套接字是连接的一个端点。
socket 返回的 clientfd 描述符仅是部分打开的,还不能用于读写。如何完成打开套接字的工作,取决于我们是客户端还是服务器。下一节描述当我们是客户端时如何完成打开套接字的工作。
connect 函数
这是 客户端连接服务端 的函数
1 |
|
其实很简单,clientfd 就是你自己本地创建的客户端套接字描述符,然后 addr 就是我要连接的地址,addrlen 就是 sizeof(sockaddr),用于连接服务器。
bind 函数
剩下的套接字函数——bind、listen 和 accept,这是服务端连接客户端的操作
1 |
|
bind 函数告诉内核将 addr 中的服务器套接字地址和套接字描述符 sockfd 联系起来。参数 addrlen 就是 **sizeof(sockaddr_in)**。对于 socket 和 connect,最好的方法是用 getaddrinfo 来为 bind 提供参数。
比如自己的地址是 192.168.1.1,那么希望通过这个 ip 地址和端口找到服务端的就可以在这里被接受了。
再打个比方,假如我绑定的地址是 127.0.0.1:8080,那么说明我只能通过本地来访问这个服务端了。
listen 函数
就是一般来说我们用 socket 创建的描述符是一个主动套接字(active socket),listen 函数就是告诉内核这不是用于客户端而是服务端的套接字。
1 |
|
listen 函数将 sockfd 从一个主动套接字转化为一个监听套接字(listening socket),该套接字可以接受来自客户端的连接请求。backlog 参数暗示了内核在开始拒绝连接请求之前,队列中要排队的未完成的连接请求的数量。backlog 参数的确切含义要求对 TCP/IP 协议的理解,这超出了我们讨论的范围。通常我们会把它设置为一个较大的值,比如 1024。
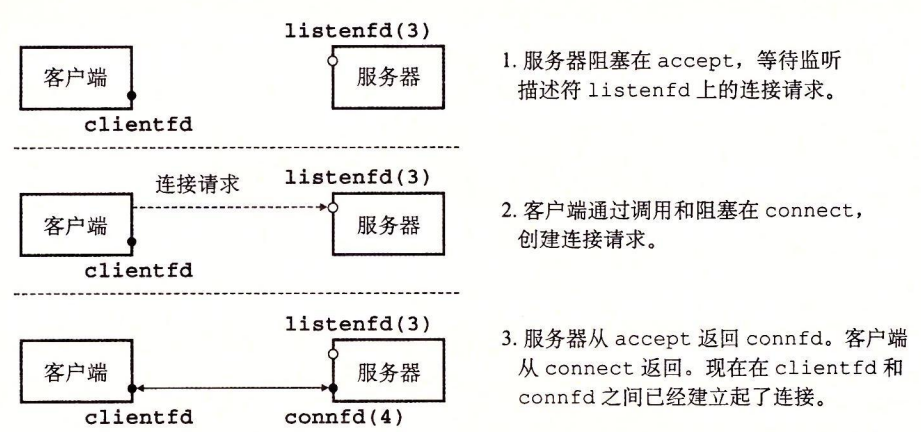
accept 函数
服务器通过调用 accept 函数来等待来自客户端的连接请求。
1 |
|
accept 函数等待来自客户端的连接请求到达侦听描述符 listenfd,然后在 addr 中填写客户端的套接字地址,并返回一个已连接描述符(connected descriptor),这个描述符可被用来利用 Unix I/O 函数与客户端通信。
这里有两个不同的概念:
- 监听描述符:创建一次,服务于整个socket周期
- 连接描述符:连接时创建,只服务当前客户端
下图很好的描述了socket的连接过程
主机和服务的转换
以下函数用于实现二进制套接字地址结构和主机名、主机地址、服务名和端口号的字符串表示之间的相互转化。
getaddrinfo 函数
getaddrinfo 函数将主机名、主机地址、服务名和端口号的字符串表示转化成套接字地址结构。
1 |
|
获得的结构如下图所示:
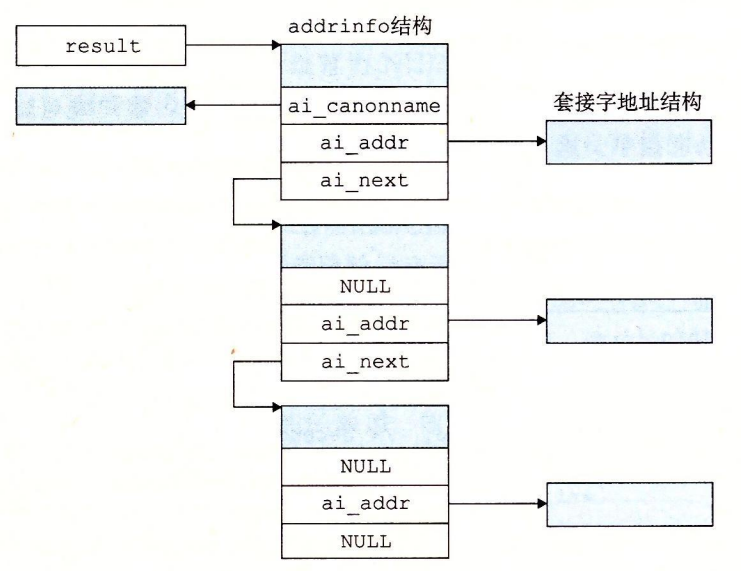
这个 getaddrinfo 函数其实就是封装的一个域名解析。
参数说明:
- host:域名,或者是ip地址
- service:服务名
- hints:传递一些标志位参数
- result:接收返回结果
后面会得到一个套接字结构,里面包含了 ip 地址和端口,端口在第二个参数给定,比如给 https 那么端口就会返回 443。具体映射关系可以在 /etc/services 中查看。
而我们可以直接使用里面的 socket 结构,也可以查看一下域名解析的结果,前面说了,域名和 ip 不一定是一对一的关系,因此它解析可能会出现多种结果。
具体介绍下第三个参数,它让我们传了一个结构体指针,结构体定义如下:
1 | struct addrinfo { |
如果要传递 hints 参数,只能设置下列字段:ai_family、ai_socktype、ai_protocol 和 ai_flags 字段。其他字段必须设置为 0(或 NULL)。实际中,我们用 memset 将整个结而清零,然后有选择地设置一些字段:
- ai_flags:设置附加选项
- AI_CANONNAME。ai_canonname 字段默认为 NULL。如果设置了该标志,就是告诉 getaddrinfo 将列表中第一个 addrinfo 结构的 ai_canonname 字段指向 host 的权威名字。
- AI_NUMERICSERV。参数 service 默认可以是服务名或端口号。这个标志强制参数 service 为端口号。
- AI_PASSIVE。getaddrinfo 默认返回套接字地址,客户端可以在调用 connect 时用作主动套接字。这个标志告诉该函数,返回的套接字地址可能被服务器用作监听套接字。在这种情况中,参数 host 应该为 NULL。得到的套接字地址结构中的地址字段会是通配符地址(wildcard address),告诉内核这个服务器会接受发送到该主机所有 IP 地址的请求。这是所有示例服务器所默认的行为。
- ai_family:指定返回地址的协议簇,取值范围:AF_INET(IPv4)、AF_INET6(IPv6)、AF_UNSPEC(IPv4 and IPv6)
- ai_socktype:用于设定返回地址的socket类型,常用的有SOCK_STREAM、SOCK_DGRAM、SOCK_RAW, 设置为0表示所有类型都可以。
- ai_protocol:有 IPPROTO_TCP、IPPROTO_UDP 等,设置为0表示所有协议。
1 |
|
getnameinfo
这里其实感觉 getnameinfo 没啥实际的用途啊,等用到再说吧。
Web 服务器
这一节开始利用socket写后端程序了。
Web 基础
html语言的学习吧,移步这里
Web 内容
对于 Web 客户端和服务器而言,内容是与一个 MIME(Multipurpose Internet Mail Extensions,多用途的网际邮件扩充协议)类型相关的字节序列。下表展示了一些常用的 MIME 类型。
| MIME类型 | 描述 |
|---|---|
| text/html | HTML 页面 |
| text/plain | 无格式文本 |
| application/postscript | Postscript 文档 |
| image/gif | GIF 格式编码的二进制图像 |
| image/png | PNG 格式编码的二进制图像 |
| image/jpeg | JPEG 格式编码的二进制图像 |
Web 服务器以两种不同的方式向客户端提供内容:
- 取磁盘文件返回(静态的)
- 运行某个程序返回结果(动态的)
把 URL 进行拆分其实能得到以下结构组成:
protcol://host:port/router/?arg1&arg2
- protcol:协议类型
- host:主机地址
- port:端口
- router:路由
- arg1&arg2:url参数
HTTP 事务
可以使用 TELNET 去连接一个 WEB 服务器,并发起请求。
1 | $ telnet www.baidu.com 80 |
HTTP 请求
一个 HTTP 请求的组成是这样的:一个请求行(request line),后面跟随零个或更多个请求报头(request header),再跟随一个空的文本行来终止报头列表。一个请求行的形式是method URI version。
HTTP 支持许多不同的方法,包括 GET、POST、OPTIONS、HEAD、PUT、DELETE 和 TRACE。我们将只讨论广为应用的 GET 方法,大多数 HTTP 请求都是这种类型的。GET 方法指导服务器生成和返回 URI(Uniform Resource Identifier,统一资源标识符)标识的内容。URI 是相应的 URL 的后缀,包括文件名和可选的参数。
HTTP 响应
HTTP 响应和 HTTP 请求是相似的。一个 HTTP 响应的组成是这样的:一个响应行(response line)(第 8 行),后面跟随着零个或更多的响应报头(response header)(第 9 ~ 13 行),再跟随一个终止报头的空行(第 14 行),再跟随一个响应主体(response body)(第 15 ~ 17 行)。一个响应行的格式是version status-code status-message
version 字段描述的是响应所遵循的 HTTP 版本。状态码(status-code)是一个 3 位的正整数,指明对请求的处理。状态消息(status message)给出与错误代码等价的英文描述。下表列出了一些常见的状态码,以及它们相应的消息。
| 状态代码 | 状态消息 | 描述 |
|---|---|---|
| 200 | 成功 | 处理请求无误 |
| 301 | 永久移动 | 内容已移动到 location 头中指明的主机上 |
| 400 | 错误请求 | 服务器不能理解请求 |
| 403 | 禁止 | 服务器无权访问所请求的文件 |
| 404 | 未发现 | 服务器不能找到所请求的文件 |
| 501 | 未实现 | 服务器不支持请求的方法 |
| 505 | HTTP 版本不支持 | 服务器不支持请求的版本 |
服务动态内容
这一小节没什么内容,无非就是写了一个生成 http headers 的程序,打印到标准输出了。并且如果需要,我们可以直接使用重定向的方式发回给客户端。
实例:TINY Web 服务器
这里我们也按照自己的理解去编写一个web服务器。
主逻辑:
1 | //#include "csapp.h" |
先写成这样吧,有时间再改,目前是能实现监听并且输出客户端信息的。并且也知道了这个 getnameinfo 的作用,就是在这里记录日志的时候有很大的用处。
Listen 函数集成了 socket bind listen 三件套,返回一个监听套接字描述符。
主要利用了 getaddrinfo 函数寻找每一个合法的地址尝试去绑定,监听。
mark一下,后面有时间补完。
小结
(from book)
每个网络应用都是基于客户端—服务器模型的。根据这个模型,一个应用是由一个服务器和一个或多个客户端组成的。服务器管理资源,以某种方式操作资源,为它的客户端提供服务。客户端—服务器模型中的基本操作是客户端—服务器事务,它是由客户端请求和跟随其后的服务器响应组成的。
客户端和服务器通过因特网这个全球网络来通信。从程序员的观点来看,我们可以把因特网看成是一个全球范围的主机集合,具有以下几个属性:
- 每个因特网主机都有一个唯一的 32 位名字,称为它的 IP 地址。
- IP 地址的集合被映射为一个因特网域名的集合。
- 不同因特网主机上的进程能够通过连接互相通信。
客户端和服务器通过使用套接字接口建立连接。一个套接字是连接的一个端点,连接以文件描述符的形式提供给应用程序。套接字接口提供了打开和关闭套接字描述符的函数。客户端和服务器通过读写这些描述符来实现彼此间的通信。
Web 服务器使用 HTTP 协议和它们的客户端(例如浏览器)彼此通信。浏览器向服务器请求静态或者动态的内容。对静态内容的请求是通过从服务器磁盘取得文件并把它返回给客户端来服务的。对动态内容的请求是通过在服务器上一个子进程的上下文中运行一个程序并将它的输出返回给客户端来服务的。CGI 标准提供了一组规则,来管理客户端如何将程序参数传递给服务器,服务器如何将这些参数以及其他信息传递给子进程,以及子进程如何将它的输岀发送回客户端。只用几百行 C 代码就能实现一个简单但是有功效的 Web 服务器,它既可以提供静态内容,也可以提供动态内容。