CS:APP第十章学习
开始学 CSAPP的第十章
逐步更新:
- 2023-02-01:开始写
梗概
这里介绍了我们学习 Unix IO 的一个原因。第一点就是帮助我们理解更深层次的系统概念,第二点就是在某些编程环境下,除了最底层的 IO 我们别无选择。
Unix IO
在 Linux 当中,一切皆文件,所有的 IO 设备都以文件的形式挂载在文件系统当中,我们需要输入输出只需要简单的读写文件即可,这使得我们访问任何设别都可以以简单一致的方式去访问:
- 打开文件:通过 open 函数打开一个文件,内核会记录这个文件的所有信息,用户层会返回一个文件描述符,用户层要操作文件只需要对文件描述符操作即可。
- Linux在创建进程的时候有默认的三个打开的问及那:标准输入(stdin),标准输出(stdout),标准错误(stderr)。
- 改变当前文件的位置:对于每个打开的文件,内核会记录文件所在的位置 k,初始为 0,通过 seek 操作我们可以改变这个值。
- 读写文件:读文件就是把文件中从 k 开始到 k+size 的文件内容复制到内存,写文件就是把文件中从 k 开始到 k + size 的文件内容用内存中的某些值替换。
- 关闭文件:完成了访问之后,我们应当使用 close 函数去通知内核关闭这个文件,释放系统资源。
文件
每个 Linux 文件都有一个类型来表示它的角色,通常情况下我们把 Linux 的文件类型分为以下几个类型:
- 普通文件(regular file):应用程序要细分下面两个类型,内核不会区分。
- 文本文件(text file):只包含 ASCII 或者是 UNICODE 字符的普通文件
- 二进制文件(binary file):包含任意字节的普通文件。
- 目录(directory):是包含一组链接的文件,每个链接都将一个文件名映射到一个文件,这个文件可能是另一个目录。目录中至少包含两个链接:
.和..分别表示指向自己的链接和自己的父目录的链接。 - 套接字(socket):用来与另一个进程进行跨网络通信的文件。
Linux 的文件系统:
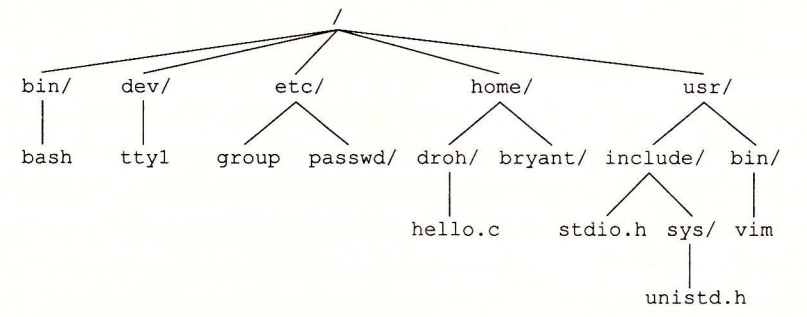
每个进程都会有一个当前工作目录(current working directory)来确定其在目录层次结构中的当前位置。可以用 cd 命令来修改 shell 中的当前工作目录。
目录层次结构中的位置用路径名(pathname)来指定。路径名是一个字符串,包括一个可选斜杠,其后紧跟一系列的文件名,文件名之间用斜杠分隔。路径名有两种形式:
- 绝对路径名(absolute pathname)以一个斜杠开始,表示从根节点开始的路径。例如,在图 10-1 中,hello.c 的绝对路径名为 /home/droh/hello.c。
- 相对路径名(relative pathname)以文件名开始,表示从当前工作目录开始的路径。例如,在图 10-1 中,如果 /home/droh 是当前工作目录,那么 hello.c 的相对路径名就是 ./hello.c。反之,如果 /home/bryant 是当前工作目录,那么相对路径名就是 ../home/droh/hello.c。
打开和关闭文件
使用 open 函数打开一个文件,返回一个文件描述符。
1 |
|
open 函数将 filename 转换为一个文件描述符,并且返回描述符数字。返回的描述符总是在进程中当前没有打开的最小描述符。flags 参数指明了进程打算如何访问这个文件:
- O_RDONLY:只读。
- O_WRONLY:只写。
- O_RDWR:可读可写。
(以上宏存在于头文件 fcntl.h)
flags 参数也可以按位或更多位掩码,为写提供给一些额外的指示:
- O_CREAT:如果文件不存在,就创建它的一个截断的(truncated)(空)文件。
- O_TRUNC:如果文件已经存在,就清空里面的内容。
- O_APPEND:在每次写操作前,设置文件位置到文件的结尾处。
第三个参数是我们创建文件时的权限,我们都知道 Linux 的文件权限有 9 位二进制数字组成,因此它也有定义九个宏分别表示这些权限。
| 掩码 | 描述 |
|---|---|
| S_IRUSR | 使用者(拥有者)能够读这个文件 |
| S_IWUSR | 使用者(拥有者)能够写这个文件 |
| S_IXUSR | 使用者(拥有者)能够执行这个文件 |
| S_IRGRP | 拥有者所在组的成员能够读这个文件 |
| S_IWGRP | 拥有者所在组的成员能够写这个文件 |
| S_IXGRP | 拥有者所在组的成员能够执行这个文件 |
| S_IROTH | 其他人(任何人)能够读这个文件 |
| S_IWOTH | 其他人(任何人)能够写这个文件 |
| S_IXOTH | 其他人(任何人)能够执行这个文件 |
以上宏在 sys/stat.h 定义。
当然,属性 Linux 的大可不用,如果我们想设置 777 权限直接给参数 0777 即可,前缀 0 表明是一个八进制的数字。
umask可以让防止创建文件权限带上某些权限,拥有最高的统治地位,一般来说 umask 为 0,我们在设置文件权限的时候,会让文件权限按位与上一个 ~umask,~0 其实就是全 1。
比如我不想文件带有执行权限,那么我设置 umask(0111),屏蔽每一组的执行权限。
例如我们写了下面这个程序:
1 |
|
那么我们得到的 flag 文件最终权限是 0666。
练习1:下面程序的输出是什么?
2
3
4
5
6
7
8
9
10
11
12
int main()
{
int fd1, fd2;
fd1 = Open("foo.txt", O_RDONLY, 0);
Close(fd1);
fd2 = Open("baz.txt", O_RDONLY, 0);
printf("fd2 = %d\n", fd2);
exit(0);
}
因为文件描述符的分配是最小没有被使用的一个非负数,因为默认有 0 1 2,fd1=3,但是fd3被关闭了,因此fd2=3。
所以最终输出 fd2 = 3。
读文件和写文件
使用 read 函数和 write 函数来读写文件。
1 |
|
size_t 和 ssize_t 类型的最大区别就是 ssize_t 有符号。
在某些情况下,read 和 write 传送的字节比应用程序要求的要少。这些不足值(short count)不表示有错误。出现这样情况的原因有:
- 读时遇到 EOF。假设我们准备读一个文件,该文件从当前文件位置开始只含有 20 多个字节,而我们以 50 个字节的片进行读取。这样一来,下一个 read 返回的不足值为 20,此后的 read 将通过返回不足值 0 来发出 EOF 信号。
- 从终端读文本行。如果打开文件是与终端相关联的(如键盘和显示器),那么每个 read 函数将一次传送一个文本行,返回的不足值等于文本行的大小。
实际上,除了 EOF,当你在读磁盘文件时,将不会遇到不足值,而且在写磁盘文件时,也不会遇到不足值。然而,如果你想创建健壮的(可靠的)诸如 Web 服务器这样的网络应用,就必须通过反复调用 read 和 write 处理不足值,直到所有需要的字节都传送完毕。
比如常见的的一定能读完 50 字节的模板:
1 | int n=50; |
使用健壮的包
这个在打 PWN 的时候也真是见得多了,所以这章略了。
读取文件元数据
应用程序能够通过调用 stat 和 fstat 函数,检索到关于文件的信息(有时也称为文件的元数据(metadata))。
1 |
|
在 Linux shell 中,使用 man 2 stat 可以查看文件元数据的结构体。
1 | /* Metadata returned by the stat and fstat functions */ |
它也定义在 sys/stat.h 头文件中。
st_size 成员包含了文件的字节数大小。st_mode 成员则编码了文件访问许可位和文件类型。
Linux 在 sys/stat.h 中定义了宏谓词来确定 st_mode 成员的文件类型:
- **S_ISREG(m)**。这是一个普通文件吗?
- **S_ISDIR(m)**。这是一个目录文件吗?
- **S_ISSOCK(m)**。这是一个网络套接字吗?
通过读取 st_mode 成员来判断文件类型。
1 |
|
读取目录内容
同样的套路:打开,读,关闭,而且因为目录的特殊性,目录的写其实就是在里面创建文件或者是文件夹。
打开:
1 |
|
读:
1 |
|
对于这里返回的 dirent 结构体,它的定义如下:
1 | struct dirent { |
inode 其实就是底层逻辑的文件命名。
第一个字段表示节点编号,第二个字段表示文件名。
关闭:
1 |
|
那么根据这些函数,我们可以写一个类似 ls 命令的功能。
1 |
|
共享文件
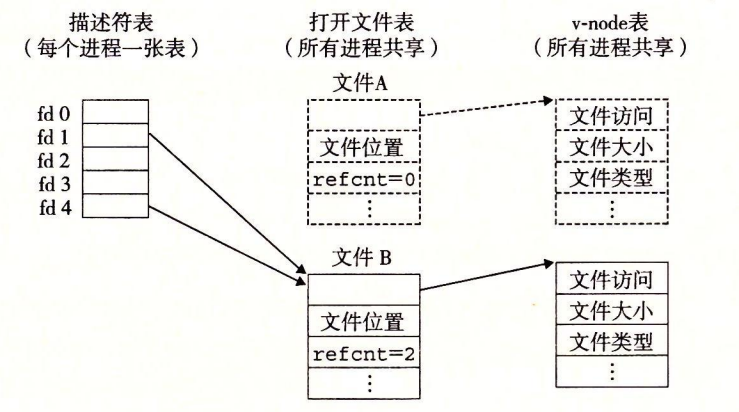
这里介绍了三个表:
- 描述符表:进程之间独立,每个打开的文件描述符表项指向文件表中的一个表项。
- 文件表:进程之间共享,它有所有进程打开的文件表项,每个表项包括了文件位置、引用计数、以及指向 v-node 表项对应的指针。当引用计数为 0 也就是所有进程都关闭了这个文件时,内核会删除这个表项。
- v-node 表:也是所有进程共享,里面的一个表项包含了 stat 结构信息以及其它一些额外的字段。
下面有张图很好的描述了这几张表之间的关系:
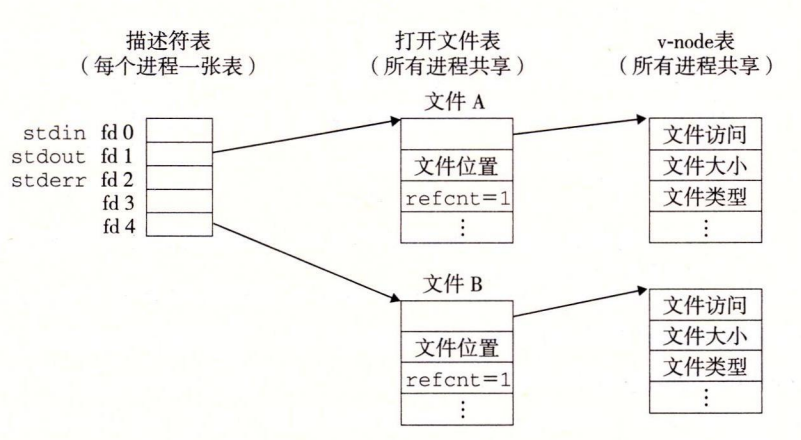
这里需要说明的一点就是:打开文件表中的引用计数仅仅在 fork 的时候会增加,其余情况(如同一进程重复打开同一文件,或者不同进程打开同一文件)不会增加。
下面演示同一进程重复打开同一文件的情况:
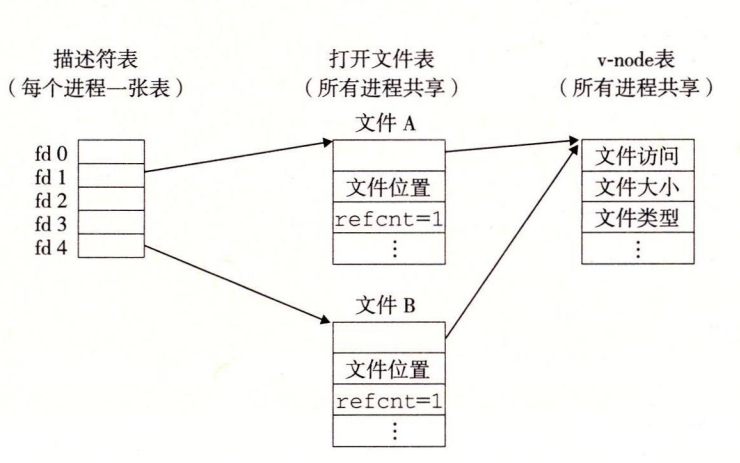
它会产生两个打开文件表的表项,而不是单纯地就指向过去就完事了。
最后就是 fork 的情况了:
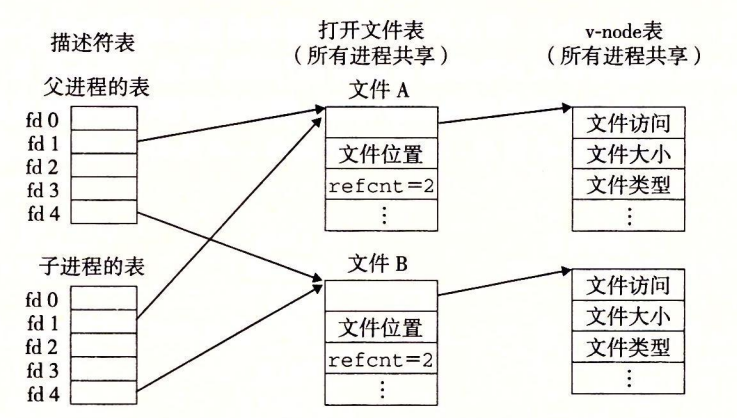
来看看例题:
练习10.2:假设磁盘文件 foobar.txt 由 6 个 ASCII 码字符 “foobar” 组成。那么,下列程序的输出是什么?
2
3
4
5
6
7
8
9
10
11
12
13
14
int main()
{
int fd1, fd2;
char c;
fd1 = Open("foobar.txt", O_RDONLY, 0);
fd2 = Open("foobar.txt", O_RDONLY, 0);
Read(fd1, &c, 1);
Read(fd2, &c, 1);
printf("c = %c\n", c);
exit(0);
}
这题很明显是属于同一进程打开同一文件的情况,因为它们不共享同一表项,因此是独立的,输出就是 c = f。
练习10.3:就像前面那样,假设磁盘文件 foobar.txt 由 6 个 ASCII 码字符 “foobar” 那么下列程序的输出是什么?
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main()
{
int fd;
char c;
fd = Open("foobar.txt", O_RDONLY, 0);
if (Fork() == 0) {
Read(fd, &c, 1);
exit(0);
}
Wait(NULL);
Read(fd, &c, 1);
printf("c = %c\n", c);
exit(0);
}
这一题很明显就是 fork 的情况,fork 只会拷贝文件描述符不会新增打开文件表项,因此子进程先读取一个,父进程再读取一个就读取到了第二个字符,最后输出 c = o。
I/O 重定向
Linuxshell 提供了 I/O 重定向操作符,允许用户将磁盘文件和标准输入输出联系起来。例如,键入:
1 | linux> ls > foo.txt |
可以把 ls 命令的输出定向到当前目录下 foo.txt 的文件中。
那么它是怎么重定向的呢,第一种方式就是使用 dup2 函数。
1 |
|
dup2 函数复制描述符表表项 oldfd 到描述符表表项 newfd,覆盖描述符表表项 newfd 以前的内容。如果 newfd 已经打开了,dup2 会在复制 oldfd 之前关闭 newfd。
比如上面,这样的一个描述符表的结构:
再调用 dup2(4,1) 之后执行下面的操作:
发现 fd=1 的描述符已经打开了一个文件,那么关闭这个文件,这个文件打开表的那一项会被删除,再让描述符 1 指向描述符 4 所指向的打开文件表项。
最后结果变成了这样:
dup2 函数本意是:为已有的文件描述符创建一个新的文件描述符,如果说是要把某个描述符定向到某个文件则需要反向思考一下。
dup2(4,1) 可以被描述成:为文件描述符 4 的文件创建了一个新的文件描述符 1,因为 1 已经有一个文件了(通常是标准输出),所以把原文件关闭,这个描述符指向了被拷贝的文件描述符所指向的文件指针。
它也可以被描述成:把标准输出定向到 fd=4 的文件中去。
来看看练习题:
练习10.4:如何用 dup2 将标准输入重定向到描述符 5?
跟那个差不多,就是 dup2(5,0) 了。
练习10.5:假设磁盘文件 foobar.txt 由 6 个 ASCII 码字符 “foobar” 组成,那么下列程序的输出是什么?
2
3
4
5
6
7
8
9
10
11
12
13
14
15
>int main()
>{
int fd1, fd2;
char c;
fd1 = Open("foobar.txt", O_RDONLY, 0);
fd2 = Open("foobar.txt", O_RDONLY, 0);
Read(fd2, &c, 1);
Dup2(fd2, fd1);
Read(fd1, &c, 1);
printf("c = %c\n", c);
exit(0);
>}
这里读了 fd2 的一个字节,把 fd2 复制到了 fd1 描述符,因此再次使用 fd1 去读取就是得到了 o。
所以输出 c = o。
重定向这一节之前专门写过一篇的:传送门
标准 I/O
其实就是库对接口进行的封装,操作系统给我们提供的 IO 接口很简单,如果都使用 read 输入,write 输出的话效率会非常低。glibc提供了打开和关闭文件的函数(fopen 和 fclose)、读和写字节的函数(fread 和 fwrite)、读和写字符串的函数(fgets 和 fputs),以及复杂的格式化的 I/O 函数(scanf 和 printf)。
标准 I/O 库将一个打开的文件模型化为一个流。对于程序员而言,一个流就是一个指向 FILE 类型的结构的指针。每个 ANSI C 程序开始时都有三个打开的流 stdin、stdout 和 stderr,分别对应于标准输入、标准输出和标准错误
1 |
|
类型为 FILE 的流是对文件描述符和流缓冲区的抽象。流缓冲区的目的和 RIO 读缓冲区的一样:就是使开销较高的 Linux I/O 系统调用的数量尽可能得小。例如,假设我们有一个程序,它反复调用标准 I/O 的 getc 函数,每次调用返回文件的下一个字符。当第一次调用 getc 时,库通过调用一次 read 函数来填充流缓冲区,然后将缓冲区中的第一个字节返回给应用程序。只要缓冲区中还有未读的字节,接下来对 getc 的调用就能直接从流缓冲区得到服务。
我该使用哪些 I/O 函数?
Unix I/O、标准 I/O 和 RIO 之间的关系如下图所示:
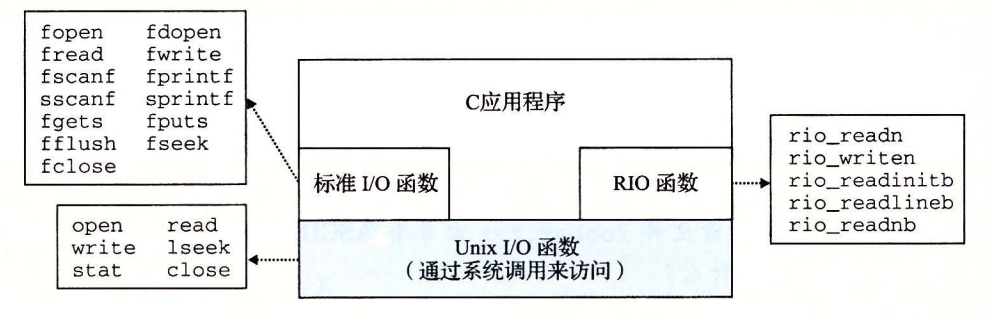
stdio 和 RIO 都是对 UNIX IO 的封装和抽象,不同的情况下各有各的好处,下面提供本书的一些基本原则:
- G1:只要有可能就使用标准 I/O。除了stat读取文件基本信息以外,都推荐使用stdio封装的函数。
- G2:不要使用 scanf 或 rio_readlineb 来读二进制文件。像 scanf 或 rio_read-lineb 这样的函数是专门设普来读取文本文件的。二进制文件可能会散布很多的 0xa 字节,一旦出现,scanf 便会终止,因此会出现奇奇怪怪的错误。
- G3:对网络套接字的 I/O 使用 RIO 函数。不幸的是,当我们试着将标准 I/O 用于网络的输入输出时,出现了一些令人讨厌的问题。如同我们将在 11.4 节所见,Linux 对网络的抽象是一种称为套接字的文件类型。就像所有的 Linux 文件一样,套接字由文件描述符来引用,在这种情况下称为套接字描述符。应用程序进程通过读写套接字描述符来与运行在其他计算机的进程实现通信。
标准 I/O 流,从某种意义上而言是全双工的,因为程序能够在同一个流上执行输入和输出。然而,对流的限制和对套接字的限制,有时候会互相冲突,而又极少有文档描述这些现象:
- 限制 1:跟在输出函数之后的输入函数。如果中间没有插入对 fflush、fseek、fsetpos 或者 rewind 的调用,一个输入函数不能跟随在一个输出函数之后。fflush 函数清空与流相关的缓冲区。后三个函数使用 Unix I/O lseek 函数来重置当前的文件位置。
- 限制 2:跟在输入函数之后的输出函数。如果中间没有插入对 fseek、fsetpos 或者 rewind 的调用,一个输出函数不能跟随在一个输入函数之后,除非该输入函数遇到了一个文件结束。
这些限制给网络应用带来了一个问题,因为对套接字使用 lseek 函数是非法的。对流 I/O 的第一个限制能够通过采用在每个输入操作前刷新缓冲区这样的规则来满足。然而,要满足第二个限制的唯一办法是,对同一个打开的套接字描述符打开两个流,一个用来读,一个用来写:
1 | FILE *fpin, *fpout; |
但是这种方法也有问题,因为它要求应用程序在两个流上都要调用 fclose,这样才能释放与每个流相关联的内存资源,避免内存泄漏:
1 | fclose(fpin); |
这一节暂时copy书上的把,后面有自己的理解了再来改改。
大体按照自己的意思总结就是:普通编程操作文件建议使用 stdio,对网络套接字尽量使用基本的 UNIX IO 函数。
小结
操作系统给我们提供了基本的操作文件的接口,stdio 和 RIO 包为我们封装了这些接口,让我们能更加顺畅地输入和输出。
Linux 内核使用三个相关的数据结构来表示打开的文件。描述符表中的表项指向打开文件表中的表项,而打开文件表中的表项又指向 v-node 表中的表项。每个进程都有它自己单独的描述符表,而所有的进程共享同一个打开文件表和 v-node 表。理解这些结构的一般组成就能使我们清楚地理解文件共享和 I/O 重定向。
标准 I/O 库是基于 Unix I/O 实现的,并提供了一组强大的高级 I/O 例程。对于大多数应用程序而言,标准 I/O 更简单,是优于 Unix I/O 的选择。然而,因为对标准 I/O 和网络文件的一些相互不兼容的限制,Unix I/O 比之标准 I/O 更该适用于网络应用程序。