概率论(2)
大概讲解参数估计的概念。
极大似然估计
这里引用一下Jason Eisner大神讲的一个例子,本篇文章近似对它的原文进行翻译。
概念
这里有两个概念,似然函数和概率密度函数,先细细理解一下这两个概念
Probability and likelihood are closely related concepts in statistics, but they have slightly different meanings and uses.
Probability is a measure of the chance that an event will occur, typically expressed as a number between 0 and 1, with 0 indicating that the event is impossible, and 1 indicating that the event is certain.
A likelihood function is used to calculate the probability of observing a specific set of data given a specific set of parameters for a model.
概率密度函数给我们反映了一个随机事件产生结果的概率大小。此时我们最大化概率密度函数(取最大值),可以得到概率最大的一个值。比如标准正态分布,我们取得最高点,得到 0,0就是这个随机变量最有可能的取值。
而似然函数给了我们一个用样本估计随机事件的概率参数,正如上面那句话提到的:似然函数用于计算在给定模型的一组特定参数的情况下观察到一组特定数据的概率。
有一个例子很好地讲述了似然估计:有两个箱子,一个箱子 99 个白球,1个红球,另一个箱子有 99 个红球,1个白球。随机从两个箱子的一个箱子中,抽取出一个球,如果是白球,那么我们不难得到,我们摸到的大概率是第一个箱子。
理解
对于概率密度函数和似然函数,我们拿 $a^b$ 这个函数为例子。如果你令 $b=2$,这样你就得到了一个关于 a 的二次函数。
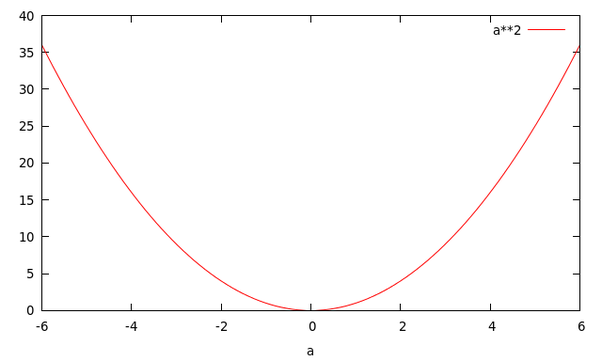
当你令 $a=2$ 时,你将得到一个关于 b 的指数函数。

可以看到这两个函数有着不同的名字,却源于同一个函数。
而 $p(x|\theta)$ 也是一个有着两个变量的函数。如果,你将 $θ$ 设为常量,则你会得到一个概率函数(关于 $x$ 的函数);如果,你将$x$ 设为常量你将得到似然函数(关于 $θ$ 的函数)。
有一个硬币,它有 $\theta$ 的概率会正面向上,有1-θ的概率反面向上。$\theta$ 是存在的,但是你不知道它是多少。为了获得 $\theta$ 的值,你做了一个实验:将硬币抛10次,得到了一个正反序列:$X=HHTTHTHHHH$ (H 为正面向上)。
我们要得到这个序列,不难算出它的概率应$P=\theta\theta(1-\theta)(1-\theta)\theta(1-\theta)\theta\theta\theta\theta=\theta^7(1-\theta)^3$
如果我们把这个概率中的 $\theta$ 当作自变量,得到似然函数如下:
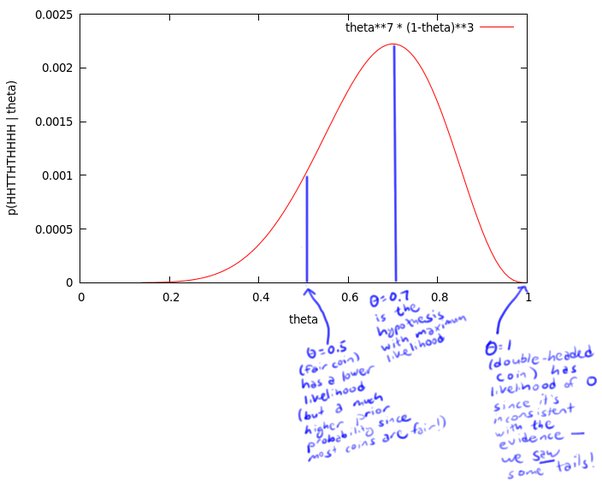
这个曲线就是 $θ$ 的似然函数,通过了解在某一假设下,已知数据发生的可能性,来评价哪一个假设更接近 $θ$ 的真实值。如图所示,最有可能的假设是在 $θ=0.7$ 的时候取到。但是,你无须得出最终的结论 $θ=0.7$。事实上,根据贝叶斯法则,0.7是一个不太可能的取值(如果你知道几乎所有的硬币都是均质的,那么这个实验并没有提供足够的证据来说服你,它是均质的)。但是,0.7却是这个样本结果的最大似然估计的取值。
对于极大似然估计,我们不难看出它的过程就是,统计一个样本发生的概率,以参数为自变量写出似然函数,最大化即可找到最大似然估计的值。
矩估计
矩估计的思想就是把样本的期望计算出来,调整参数,使得概率模型的期望等于我们的样本期望。
中心思想就是 $E(X)=\overline X$,左边是概率模型的期望,右边是样本的期望。
比如我知道一个样本符合指数分布,那么我自然知道这个概率模型的期望就是 $\frac{1}{\lambda}$,我从这个模型中抽取出 n 个样本,能算出一个均值,从而反向求出 $\lambda$。
矩估计有两种,一个是中心矩,一个是原点矩,中心距就是让所有的样本都减去期望,不难看出如果直接计算它最终结果应该要让它等于 0 才对。原点矩就是让所有样本减去 0(与远点的距离)。
矩估计还有对应的阶数,我们可以使用高阶矩估计来对多参数的概率模型进行求解。
高阶的中心矩估计其实就是:
$\sum _{i=1} ^{n}(X_i-\overline X)^k=E(X^k-E(X))$
这里的 $k$ 就是阶数。
而对应的高阶原点矩就是:
$\sum _{i=1} ^{n}X_i^k=E(X^k)$
这里的 $k$ 就是阶数。
不难看出,我们开头介绍的思想就是 $k=1$ 时候的原点矩。对于 $k=1$ 时候的中心距,我们会得到 $0=0$ 的恒等式,因此没有意义,但是二阶中心矩是我们会用到的比较多的。
$\sum _{i=1} ^{n}(X_i-\overline X)^2=E(X^2-E(X))=D(X)$
这其实就是一个方差的等式,我们让样本方差 = 总体方差得到又一个等式。