咕了有点久了,赶紧把新的章节预习完,捡出重点知识写一写文章。
程序的机器级表示 历史观点 Intel 系列处理器俗称 x86,经历了一系列的发展变化,从最初的四位,到16位微处理器 8086,32位的 i386 以及64位的 x86-64。
摩尔定律:芯片上的晶体管数量没过一年都会增长一倍,而事实正如所预料的这么发展,计算机科学的技术正以指数级的量级发展。
计算机只能够认识机器语言,只有机器语言能够直接被执行,如今的高级语言提供的抽象级别较高,较高的抽象级别可以提高工作效率,也能提高可靠性,在过渡到低级语言(汇编,机器语言)的时候编译器也能帮助我们发现程序的错误。虽然高级语言在各方面都能碾压低级语言,不论是在前面说的工作效率可靠性,还是可移植性方面。但是并不不是说我们就没有必要学习低级语言了,因为低级语言也由人为创建,也会产生漏洞,如果语言出现底层的逻辑漏洞,那么光从高级语言去查是永远不会查出结果的,这也是我们需要学习低级语言的原因。在了解了汇编语言,机器语言之后,你也会发现,计算机漏洞并不那么难以理解。
程序编码 比如有一个程序:test.c,我们用如下命令编译:
这样编译出一个可执行的 test 文件,事实上,这一个命令调用了一整套的程序,程序拆解下来大致分为四步:
预编译
编译
汇编
链接
预编译会将 #include 所包含的文件展开以及 #define 申明指定的宏,生成 test.i。
编译会将高级语言翻译为低级语言,也就是汇编语言,生成 test.s。
汇编会将汇编语言转为对应的机器码,生成可重定向文件 test.o。到了这一步,程序仍不能独立运行,因为它缺少了相应的库函数和程序入口函数 _start 也没有填充全局的地址。
链接会将目标代码与库(libc.so.6)的代码合并,最终产生可执行文件 test。
我们可以使用以下四个命令来模拟每一步的过程:
1 2 3 4 $gcc -E test.c -o test.i $gcc -S test.i -o test.s $gcc -c test.s -o test.o $gcc -g test.o -o test [--static]
在最后一步链接的时候,我们可以添加参数 –static 进行静态链接,或者不加参数默认动态链接。静态链接时,产生的可执行文件会非常大,而动态链接产生的可执行文件相对较小,每一个静态链接的文件被执行,都会把库函数的代码写进内存当中,而动态链接则不会,因此静态链接比动态链接会耗费更多的内存。但是静态链接的文件可以脱离库(libc.so.6) 运行,而动态链接必须依赖库运行,编译出来的文件放在不同版本的环境运行下可能会有较大差别,因此静态链接的可以执行比动态链接强。
机器级代码 对于机器级编程来说,两种抽象比较重要:指令集体系结构或指令架构(ISA)定义了机器级程序的格式和行为,第二种抽象是内存地址为虚拟地址,提供的内存模型是非常大的字节数组。
一些对 C语言 程序员隐藏的处理状态对于机器代码是可见的。
程序计数器(PC),在 x86-64 种以 %rip 寄存器表示程序要执行的下一条指令的地址。
寄存器
状态寄存器
向量寄存器
在汇编代码中,不区分有符号无符号,不区分普通类型和指针类型,而操作系统负责把虚拟地址翻译成实际处理器内存中的物理地址。
机器执行的程序就是一个字节序列,是对一系列指令的编码,机器对产生这些指令的源代码几乎一无所知。
如果我们想查看一个可重定向文件或者是可执行 ELF 文件的字节码和它的反汇编指令的话,我们可以使用
1 2 $objdump -d xxx.o $objdump -d ELFfile
机器码具有如下特性:
指令可以从任意地址编码,无对齐规则,只是任意地址开始的编码很可能产生错误的编码或者是运行产生错误的结果。
指令长度从1-15个字节不等,运用了哈夫曼编码的思想:越常用的指令字节数越少,越不常用的指令字节数越多。
反汇编器只是根据字节序列确定汇编代码,它完全不需要知道编译出该程序的源文件即可得到。
汇编代码有 AT&T 和 Intel 两种风格,在本书当中,基本使用的是 AT&T 风格的汇编。
风格区别
intel
AT&T
注释
;
//
指令
无后缀
需要后缀指定数据长度
立即数
直接写常数
需要加$前缀
寄存器
直接写寄存器名称
需要加%前缀
指令书写风格
通常源操作数在后,目的在前
源操作数在前,目的在后
间接寻址
方括号里面可以直接写表达式
圆括号,只能计算ax+y+b的地址
数据格式 由于 Intel 用术语 “字(word)”表示16位的数据类型,因此 32 位数被称为 “双字(double words)”,64位数被称为 “四字(quad words)”。
在多少位的系统当中,指针就是多少位的,因此64位系统当中,指针类型的数据一律是四字,下面给出常见 C 的数据类型和数据长度。
C声明
Intel数据类型
汇编代码后缀
大小(字节)
char
字节
b
1
short
字
w
2
int
双字
l
4
long
四字
q
8
char *
四字
q
8
float
单精度
s
4
double
双精度
l
8
不过这里需要注意的是:虽然双字和双精度的后缀看似起了冲突实则没有冲突,因为浮点运算有自己独立的指令,并不影响。
访问信息 这里需要介绍以下寄存器,16位机器中,我们的通用寄存器有8个:ax,bx,cx,dx,di,si,sp,bp。对于前四个寄存器来说,把 x 替换成l 表示对应寄存器的低八位数据,替换成 h 则表示高 8 位数据。后面发展到了 32 位系统,寄存器也扩展到了 32 位,于是便于区分,在对应寄存器的名字前加上 e(expand 扩展)表示 32 位的寄存器,此时我们仍可以用 ax 表示 eax 的低 16 位,al 表示 eax 的低 8 位。到了 64 位之后,为了区分,把所有的 e 替换成了 r(register 寄存器)。并且新增了 8 个寄存器 r8~r15。
除此之外还有一个很特殊的寄存器:ip,它指示了当前运行指令的地址,也就是我们广义所称的 PC 程序计数器。
操作数指示符 以下内容建议全文背诵。
大多数指令会有一个到两个操作数(operand),操作数可以是立即数(immediate),寄存器(register)或者是内存地址。具有两个操作数的指令会分源操作数(source operand)和目的操作数(destination operand)。
在有两个操作数的情况下:源操作数可以是以上三种的任意,目的操作数不能为立即数,并且源操作数和目的操作数不能同时为内存地址。
单操作数指令具体情况具体分析。
我们主要介绍第三类的操作数,也就是内存地址引用。书上介绍的场景比较多,我们直接介绍最一般的形式:
$Imm(x,y,z)表示了地址为 x+yz+$Imm 的内存空间。
数据传送指令 mov指令 我们最频繁用到的指令就是数据传送指令了,它的作用就是将源操作数的值传给目的操作数,限制于上面介绍的一样。为了区分不同的版本,我们有 movb,movw,movl,movq 分别表示 传送字节,传送字,传送双字,传送四字。但是需要注意有一个例外,在传送双字(movl)的时候,如果目的操作数为一个寄存器,则此命令会将寄存器的高四个字节全部置为 0。
而有这么一种情况,当目的寄存器字长较长,而源操作数字长较短时,我们需要对源操作数进行扩展,而扩展就引发了两种情况:符号(sign)扩展(movs)和零(zero)扩展(movz)。这样则又能引发 11 种不同的 mov 指令。从字节扩展到字,双字,四字。从字扩展到双字和四字,零扩展种没有从双字扩展到四字的指令,因为 movl 指令已经能帮我们自动零扩展了。
因此这里就有五种指令,再符号扩展和零扩展算一下就是 10 条指令了,再加上双字的符号扩展,就有 11 种类型了。
指令MOV S,R
描述
movzbw
从字节零扩展到字
movzbl
从字节零扩展到双字
movzbq
从字节零扩展到四字
movzwl
从字零扩展到双字
movzwq
从字零扩展到四字
movsbw
从字节符号扩展到字
movsbl
从字节符号扩展到双字
movsbq
从字节符号扩展到四字
movswl
从字符号扩展到双字
movswq
从字符号扩展到四字
movslq
从双字符号扩展到四字
这里其实也是很好记的,就是mov后面多三个后缀嘛,第一个字表示符号扩展(s)还是零扩展(z),第二个字符表示源操作数字长(字节b,字w,双字l),三个字符表示目的操作数字长(字w,双字l,四字q),这样就好记多了。
关于符号扩展和零扩展的区别,其实很简单,若源操作数是正数,也就是说在它字的范围内最高位为 0,符号扩展和零扩展是一样的,把高位无脑填 0 即可,如果从有符号角度来看为负数,也就是说在它字的范围内最高位为 1,符号扩展则会把高位全部填充为 1,而零扩展还是把高位填充为 0。
入栈(push),出栈(pop)指令 这两个指令本质也是数据传送指令,只不过它们只对栈进行操作。
push 是入栈指令,push S 的作用是把栈抬高八个字节(视操作系统位数而定),再将源操作数 S 放入开辟出来的栈空间中。
pop 是出栈指令,pop D 的作用是把内存栈顶的八个字节数据传送到目的操作数 D 当中,再将栈降低八个字节。
这里需要注意的是,这里的源操作数和目的操作数均不能为内存地址,因为 push 的目的操作数已经是栈里面的内存了,如果源操作数也是内存就违反了规定, Intel 是不允许我们直接将两个内存地址进行交换的,pop 同理,因此 push 的源操作数只能是立即数或者是寄存器, pop 的目的操作数只能是寄存器。
算数和逻辑操作 对于计算机来说,最重要的当然还是进行数据运算啦,我们一般运算就分为算数运算和逻辑运算,当然还有浮点运算,不过那个过于复杂我们不讨论,我们只讨论前两个。
一元运算
指令
效果
INC D
自增(D++)
DEC D
自减(D–)
NEG D
取负(-D)
NOT D
取反(~D)
这四条指令比较简单,不做详细分析
二元运算
指令
效果
ADD S,D
D+=S
SUB S,D
D-=S
IMUL S,D
D*=S(有符号)
MUL S,D
D*=S(无符号)
IDIV S,D
D/=S(有符号)
DIV S,D
D/=S(无符号)
XOR S,D
D^=S
OR S,D
D|=S
AND S,D
D&=S
SAL S,D
D>>=S(有符号)
SAR S,D
D<<=S(有符号)
SHL S,D
D>>=S(无符号)
SHR S,D
D<<=S(无符号)
这里需要注意:当左移右移的源操作数超过目的操作数的位数(w),那么它只会取得低 log2(w) (向上取整)位。
这些指令也有 b,w,l,q 的区别。
加载有效地址(Load Effective Address) lea指令用于加载有效地址,它其实就是 mov 指令的一个变形,用最直观的理解去讲,就是如果我 movq 8[%rdi,8,%rsi],%rax 的作用应该是把内存 %rdi+8*%rsi+8 这地址的八个字节给到 %rax 寄存器,而 简简单单把 movq 换成 leaq,就是不取值了,直接把算出来的地址,这个地址给到 %rax 寄存器。
它一般用于简单的计算比较多,比如以下代码。
1 2 3 4 void mul (long x,long y) { return x+4 *y; }
我们直接翻译成汇编是什么样的:
1 2 3 4 5 6 7 8 9 10 .code mul proc subq $10h,%rsp movq %rsi,%rax imulq $4,%rax addq %rdi,%rax addq %10h,%rsp retq mul endp end
当然我们目前学了这么多的知识也就允许我们写成这样了,但是如果我们用 LEA 指令就能大大缩短代码量,LEA 指令我们可以这么写:
1 2 3 4 5 6 7 8 .code mul proc subq $10h,%rsp leaq (%rdi,4,%rsi),%rax addq %10h,%rsp retq mul endp end
没错,就这么简单了,所以我们一般用 LEA 指令最多只是用一些简单的运算,或者我本来想取一个全局变量的内存地址,但是我如果直接 mov 就变成了取它的值,于是我改用 LEA 指令就能取到它的地址了,我目前能理解的也只有这两种情况了。
控制 然而,单一的顺序结构并不能满足我们的需求,我们希望程序在某些时候有所选择,希望某些时候去做重复的工作,这个时候程序将不再是顺序执行,而是会跳转执行。
跳转分条件跳转和无条件跳转,无条件跳转执行之后,则程序必定跳转到它指定的位置。如果是这样,那么程序运行与之前的顺序运行没什么区别,要实现分支结构和循环结构就需要用到条件跳转了。
条件码 在CPU当中,除了维护了 16 个整数寄存器外,我们还维护了一些状态寄存器(也称标志寄存器)。
常见的标志寄存器有
CF:进位标记,是否产生了进位
ZF:零标记,最近得到的操作结果为0
SF:符号标记,最近得到了一个负数结果
OF:溢出标志,最近的操作导致一个补码溢出
LEA 指令不会改变任何标志寄存器,INC 和 DEC 指令不会改变进位标志,有两个指令它们只改变标志位而不改变其它寄存器,那就是 cmp 指令和 test 指令。cmp 指令会与 sub 指令设置一样的标志位,但是不会改变目的操作数,test 指令则与 and 指令一样,但是也不会修改目的操作数,test 指令的常见用法就是 test %rax,%rax 来判断 %rax 的情况,当然这也可以看做是 cmp 0,%rax,与零做比较,又或者是进行掩码的与操作,根据结果判断某个标志位是否被设置。
访问条件码 条件码不会被直接读取,它一般用于条件跳转,条件设置和条件转移,它们一般有如下后缀。
指令后缀
同义后缀
条件码
设置条件
英文释义
e
z
ZF==1
相等(零)
equal(zero)
ne
nz
ZF==0
不相等(不为零)
not equal(not zero)
s
/
SF==1
为负数
sign(with -)
ns
/
SF==0
为非负数
not sign(without -)
g
nle
(SF^OF)==0&ZF==0
有符号大于
greater(not [less or equal])
ge
nl
(SF^OF)==0
有符号大于等于
greater or equal(not less)
l
nge
(SF^OF)==1
有符号小于
less (not [greater or equal])
le
ng
(SF^OF)==1|ZF
有符号小于等于
less or equal (not greater)
a
nbe
CF==0&ZF==0
无符号大于
above (not [below or equal])
ae
nb
CF==0
无符号大于等于
above or equal (not below)
b
nae
CF==1
无符号小于
below (not [above or equal])
be
na
CF|ZF==1
无符号小于等于
below or equal (not above)
这里比较复杂的大概就是有符号和无符号大小于了吧,但是其实只要理解到位是不难记的。
set指令 set 指令用于设置一个字节为全 1,它可以加入上述表中的条件后缀以用于条件设置。
跳转指令 无条件跳转可以使用直接跳转或者间接跳转,直接跳转比如 jmp *%rax,间接跳转就是对 %rax 所存的地址再次取值所得到的地址作为新的指令执行地址。
条件跳转指令的指令名称为 j + 条件后缀,比如 je 指令就是等于时跳转,条件跳转指令只能直接跳转,不能间接跳转。
跳转指令的编码 跳转指令表面上是要指定一个绝对地址,但是实际上编码的时候是采用了偏移量的方式去编码,它会根据跳转指令所编码的值去对自己的 %rip 寄存器加或者是减去一个偏移量,但是需要注意的是,偏移量是从下一条指令开始计算的,这也就是为什么 jmp 如果后面编码值为 0 不会产生一个死循环。
条件控制语句实现条件分支 比如这样的一个语句
1 2 3 4 5 6 7 int cmp (int x,int y) { if (x>y){ return 1 ; } return 0 ; }
那么我们可以这样子写汇编语句。
1 2 3 4 5 6 7 8 9 10 .code cmp proc mov $0,%rax cmp %rsi,%rdi jbe L1 mov $1,%rax L1: ret cmp endp end
如果有 if … else … 语句的话,一般采用条件跳转和无条件跳转组合的方式去实现,比如如下的表达式
1 2 3 4 5 6 if (expr){ truepart } else { falsepart }
我们进行编译之后大概率会产生如下的汇编语句
1 2 3 4 5 6 7 8 test %rdi,%rdi jz L1 //truepart jmp done L1: //falsepart done: //over
条件传送语句实现条件分支 条件传送指令就和上面两类条件指令一模一样,符合条件时传送,不符合条件时不传送。
同样,如下语句
1 2 3 4 5 6 7 8 9 10 11 int main () { int z; if (x>y){ z=x-y; } else { z=y-x; } return z }
我们使用条件跳转语句可以很轻松地实现上述逻辑,但是我们也可以使用条件传送语句,事先算出两个部分 z 的值,先赋值假设正确的值,再用条件传送语句判断错误的条件赋值。
比如
1 2 3 4 5 6 7 movq %rdi,%rax subq %rsi,%rax;let %rax=x-y movq %rsi,%rbx subq %rdi,%rbx;let %rbx=y-x cmp %rsi,%rdi cmovle %rbx,%rax;if x<=y movq %rbx,%rax ret
可能你会疑问,这样子效率会不会遍低,因为如果运算更复杂一点,我需要把两个值都算出来,执行的指令会变多。确实,条件跳转比条件转移比起来执行的指令少,而且能泛用性广,举个例子:如果 if … else … 里面有其它语句,比如输出语句,那么我们条件传送指令显然就不能用,而条件跳转能应对这种情况。
但是条件传送实现的条件分支比条件转移实现的分支运行速度快。你可能很惊讶,为什么执行的指令多反而运行速度还快了,那是因为当今的 CPU 都是流水作业,一个指令的执行分为五个步骤,它同一时间可以执行五条指令对应的不同操作。而流水作业的前提条件是我能清楚地知道我接下来要执行的代码,如果我都不知道我接下来要执行什么代码,那么我肯定不能很好的运用流水作业了。
条件控制语句在执行完毕之前,谁也不知道它是跳转或者不跳转,也就无法知道它接下来要执行的指令,我们只能选择等待条件跳转指令执行完毕再次填充指令流水作业,速度自然就慢了。而条件转移并不改变指令的执行顺序,因此它依然能利用 CPU 的流水作业。
实现分支的方式
优点
缺点
条件跳转
能应对所有分支情况,执行的指令较少
执行速度慢,不能很好的利用CPU的指令流水
条件传送
执行速度快,能很好的利用CPU的流水作业
不能应对所有的分支状况,需要把所有的情况提前计算,执行的指令较多
循环 高级语言中,除了顺序,选择以外,还有一种结构就是循环结构了,但是事实上我们依然可以通过条件转移的方式实现循环的效果,例如:
1 2 3 4 5 6 movq $10,%rcx;set loop time do: ;do something subq $1,%rcx test %rcx,%rcx jns do
以上例程可以循环10次执行,并且可以通过修改立即数 $10 来改变循环次数。
把它转为 C 语言来写就很像我们的 do-while 循环语句:
1 2 3 4 5 6 7 void test () { int i=10 ; do { i--; }while (i>=0 ); }
那么除了 do - while 我们还有 while,for 三种类型的循环。
它们的模板分别是什么样的呢,我们来看看。
while 的 C 写法:
1 2 3 4 5 6 7 void test () { int i=10 ; while (i>=0 ){ i--; } }
对应的汇编代码:
1 2 3 4 5 6 7 8 9 movq $10,%rcx do: subq $1,%rcx test %rcx,%rcx js end ;do something jmp do end: ret
for 的 C 写法:
1 2 3 4 5 void test () { for (int i=0 ;i<10 ;i++){ } }
对应的汇编代码:
1 2 3 4 5 6 movq %rcx,0 do: ;something addq %rcx,$1 cmpq $10,%rcx jl do
如果循环语句中有 continue,我们就跳过循环体中的所有逻辑,直接到循环条件判断和循环变量的修改,如果有 break 我们直接跳出循环即可。
要点:掌握循环结构的写法和循环的判断 。
switch语句 其实有人说,switch 就可以理解为 if elseif else if … 的形式,其实从实现来说,两者并没有太大的差别,但是执行效率上会有巨大差别,如果语句在第 n+1 个条件成立了,那么程序进行了 n+1 次判断。而 switch 语句在多数情况下(case语句超过四条,值的跨度小)并没有使用条件转移来区分各个值之间的跳转,当然它会区分一般值和默认值(default),一般值我们使用跳转表的形式实现。
比如如下的语句:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void test{ long val=1 ; switch (n){ case 1 : val+=2 ; break ; case 2 : val-=2 ; break ; case 3 : val*=2 ; break ; case 4 : val-=2 ; break ; default : val++; } return val; }
将它翻译为汇编语言之后可能会出现这样的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 .L1: .quad .L2 .quad .L3 .quad .L4 .quad .L5 .quad .L6 test proc: movq $1,%rax subq $1,%rdi cmpq $3,%rdi ja L6 jmp *.L1(,%rdi,8) L2: addq $2,%rax jmp end L3: subq $2,%rax jmp end L4: mul $2,%rax jmp end L5: div $2,%rax jmp end L6: addq $1,%rax end: ret test endp
我们可以看到跳转表的一个优势所在,对于每一个条件,都可以只进行一次判断就跳转到指定位置运行,当然我们实际在用的时候,可能会出现空语句,或者是滑落的情况(即语句下面没有 break),如果出现滑落,我们就删除对应语句块的 jmp 命令,如果出现空语句(case 后面没有语句),我们不新增加标签,而是直接设置跳转表的位置为下一个有值的标签。
过程 过程是软件中一个很重要的抽象,它提供了一种封装代码的方式,用一组参数和返回值实现了某种功能,然后我们可以在程序中不同的地方调用这个函数。
运行时栈 C 语言调用机制的一个关键特性就是使用了栈结构提供的后进先出的管理原则。当 P 调用 Q 的时候,我们需要暂时保存 P 函数调用之前的一个状态,在调用完成之后予以恢复状态,当然,除了 %rax 寄存器,因为它需要返回值。
当 x86-64 过程需要的局部变量超出了我们所可以使用的寄存器时,函数就会选择在栈上开辟空间用于保存局部变量,这个局部变量的部分以及一些被保存的寄存器部分就是我们这个函数的栈帧。
转移控制 在调用函数的时候,我们需要让 %rip 寄存器到我们调用的函数代码段,调用结束之后,我们又需要让它返回原来的函数,因此这里就需要我们的 CALL 指令,CALL 指令也是无条件跳转指令,只是在跳转之前会增加一步,将当前的 %rip 压入栈中,等到被调用函数执行 ret 指令的时候,栈会把栈顶所保存的 返回地址 给到 %rip 寄存器。
建议跟则书上的图走一遍会理解更深刻。
数据传送 调用过程的时候,我们除了要交与控制权以外,我们还需要给定对应的参数,因此这里我们需要知道给函数传递对应的参数的方法。
重要知识,建议背诵:x86-64架构的函数调用传递参数的方式为:前六个参数分别传递给寄存器 %rdi,%rsi,%rdx,%rcx,%r8,%r9,若还有剩余参数,剩余参数从右往左依次入栈。
栈上的局部存储 除了寄存器不足以存放所有本地数据时会开栈空间来存放以外,如果对变量进行了引用,即取址操作(&),这个变量也必须放入栈中,栈开辟的局部存储会在函数调用结束的时候被释放掉。
寄存器的局部存储 一般情况下,如果局部变量比较少,局部变量都将被保存在寄存器当中,那么发生调用的时候,我们应该如何保存寄存器中的局部变量呢?第一种方法就是被调用函数不去动这些寄存器,调用结束之后那还是原来的值,也没有关系。但是如果被调用函数也需要使用这些寄存器呢?我们就只能先把它保存在栈中,等到结束的时候再去读取。
惯例中:%rbx,%rbp,%r12~%r15 被划分为被调用者保存寄存器,就是调用者不需要去管它,要相信被调函数会为你保存好这一切内容。当然其它的寄存器中,除了 %rsp 就都属于调用者需要保存的寄存器,被调函数在用这些寄存器的时候会认为调用者已经保存好了,自己无需保存可以直接修改寄存器。
数组的分配与访问 C语言的数组是一种将标量数据聚集为更大的数据类型的方式。
基本原则 数组 type A[n] 所占用的字节数 sizeof(A)=sizeof(type)n,我们要访问 A[i] 时,实际是访问内存地址为 XA+i sizeof(type) 的元素。
指针运算 C语言允许对指针直接运算,但是指针与整数的加减被重载过, p+i 相当于 Xp+i*sizeof(type) 的地址(Xp 表示数组 p 的基地址)。
嵌套数组 当我们定义了一个 int A[3][5] 时,相当于做了如下定义:
1 2 typedef int row3_t [3 ];row3_t A[5 ];
对于数组 A[N][M] 来说,A[i][j] 相当于访问内存地址为 XA+i*sizeof(int)M+j sizeof(int) 的元素。
异质的数据结构 结构体 C语言会用一个 Struct 声明创建一个数据类型,将可能不同类型的基本数据聚和到一个对象当中,用名字来引用结构的各个部分。编译器对结构体处理时会记录每个变量名在结构体当中的偏移,对应使用时找到相对应的内存地址取出元素。
对于 C 语言而言,为了方便内存管理会对数据类型做出这样的规定:大小为 n(n<=8) 的数据必须对齐在地址为 n 的倍数上,如果当前地址不符合要求则会往后顺延,中间的内存可能会因为填充产生浪费。
考虑如下结构体的声明:
1 2 3 4 5 struct S1 { int i; char c; int j; }
看似我们可以采取这样的一种形式:
1 2 3 4 5 struct S1 { int i; char c; int j; }
这样我们只需要花费 9 个字节的内存就可以分配完这个结构体。然而事实上为了方便内存管理,它会强制要求 int 对齐在 4 整倍的内存偏移量上面。
建议做一下例题 3.45,会对对齐这方面有更深的了解。
将控制和数据结合起来 到现在我们已经理解了数据和指令的基本操作,本节会详细讲述它们之间的一些详细应用,以及帮我们研究常见的缓冲区溢出漏洞及对应的对抗手段。
理解指针 指针是 C 语言的核心特色,它提供了直接对内存操作的一个手段。指针的类型表示了它指向的内存为什么数据类型,我们可以通过显式的强制转换来将一块内存数据以不同的形式表达出来。
我们来看看指针的特点
每个指针都有一个值,指定了指向的对象的地址。
*操作对于指针变量来说,作用是根据指针的数据类型取值。
强制类型转换不会改变指针的任何值,只会改变它数据的显示方式
指针可以指向函数
我们可以声明这样的一个函数指针
注意星号和变量名一定要一起加一个括号,不然星号会和前面的数据类型结合,整个声明就变成了一个函数的声明
GDB调试器 GNU 调试器 GDB 提供了许多有用的特性,允许我们机器级分析,具体可以用
来进入 gdb shell 调试程序,输入 help 可以查看具体命令和效果,常见的有
命令
效果
run
运行程序(在此给出参数)
quit
退出
kill
杀死程序
b xxx
下断点
delete
删除断点
s
单步运行
si
机器级单步运行
n
步过运行
ni
步过运行
c
继续运行
finish
步过运行直到ret
disass
查看反汇编代码
p
打印数据
info register
查看寄存器
help
调出手册
内存越界和缓冲区溢出 C在数组引用的时不会进行任何边界检查,而且局部变量和状态信息都存放在栈中,两者结合起来就会导致严重的程序错误,破坏栈中存储的信息,如果改变了尝试 ret 的位置,那么就会导致程序执行的位置发生非预期错误。
有一种特别常见的状态被称为 缓冲区溢出 ,通常是在我们在栈中分配字符数组的时候,输入的字符串超出了我们分配的大小。
比如这样第一个程序:
1 2 3 4 5 void echo () { char buf[8 ]; gets(buf); puts (buf); }
而 gets 函数会读取一整行,直到遇到 \n 时才会停止读入,不做任何长度判断,因此这个函数是危险的。
我们编译出这个函数的汇编代码可以得到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 endbr64 pushq %rbp movq %rsp, %rbp subq $16, %rsp leaq -8(%rbp), %rax movq %rax, %rdi movl $0, %eax call gets@PLT leaq -8(%rbp), %rax movq %rax, %rdi call puts@PLT nop leave ret
gets 函数的参数为 -8(%rbp) 也就是说超过8位之后,我们会覆盖到 rbp 所在的位置,如果再超过8个字节,那么就会覆盖到返回地址。
因此一般情况下我们不会使用 gets 函数去读入,这是不好的编程习惯。
缓冲区溢出更致命的一点就是让程序执行原本不会执行的函数,这是种比较常见的通过计算机网络攻击系统安全的方法。我们称编写攻击的脚本为 exploit code ,而我们直接输入的字节被称为 payload,一般情况下,攻击代码可能会尝试启动一个 shell 程序让攻击者获取对受害计算机直接操控的权限。
对抗缓冲区溢出攻击 我们有如下的几种方法:
栈随机化
栈破坏检测
栈不可执行
一般情况下,程序每次运行的虚拟地址都是固定不变的,这样会使得程序更容易遭受攻击,栈随机化使得每次程序运行时栈的位置都有变化,这类技术我们成为 地址空间布局随机化(Address-Space Layout Randomization) 当然,有防御,就会有攻击方法。我们只需要在缓冲区中插入比较多的 nop 指令,那么我们只要任意命中一个 nop 都可以导致我们恶意代码的顺利执行。这个序列的常用术语是 nop sled 差不多就是一直滑过去。如果随机化的可能性达到了 2^21,那么如果命中位置只有一个的话,我们就要赌这 2^(-21) 的概率,这显然不太能被接受,假如我们插入了 255 字节的 nop,那么我们任意命中 256 中的其中一个,我们都可以执行成功,概率直接缩小到 2^13,这个数字大小能稍微被接受了。
第二个思路是在造成严重的后果之前尽可能检测到栈溢出了,思想就是往返回地址之前插入一段随机数,在函数即将返回的时候,检查这段随机数是否被更改,如果被更改,调用 __stack_chk_fail 函数进行异常处理终止程序运行。一般这个随机数我们称为 canary(金丝雀 ,实际在下矿的时候主要用于探测煤矿是否有毒),现在的 gcc 版本默认添加 canary,但是我们可以通过参数 -fno-stack-protector 参数关闭这个保护。
第三个思路就是NX(NO EXECUTE) 让栈中不可执行代码,我们往栈中插入代码的思想也就变的不可行了,但是我们仍然可以使用 ROP 的思想去绕过这一保护。
CSAPP:bomblab 实验文件下载
我们只需要下载 writeup(实验说明) 和 Self-Study Handout(自学附件)即可。
解压附件我们可以得到一个源文件和一个二进制文件,但是源文件并没有给全,只给了大概的程序逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 #include <stdio.h> #include <stdlib.h> #include "support.h" #include "phases.h" FILE *infile; int main (int argc, char *argv[]) { char *input; if (argc == 1 ) { infile = stdin ; } else if (argc == 2 ) { if (!(infile = fopen(argv[1 ], "r" ))) { printf ("%s: Error: Couldn't open %s\n" , argv[0 ], argv[1 ]); exit (8 ); } } else { printf ("Usage: %s [<input_file>]\n" , argv[0 ]); exit (8 ); } initialize_bomb(); printf ("Welcome to my fiendish little bomb. You have 6 phases with\n" ); printf ("which to blow yourself up. Have a nice day!\n" ); input = read_line(); phase_1(input); phase_defused(); printf ("Phase 1 defused. How about the next one?\n" ); input = read_line(); phase_2(input); phase_defused(); printf ("That's number 2. Keep going!\n" ); input = read_line(); phase_3(input); phase_defused(); printf ("Halfway there!\n" ); input = read_line(); phase_4(input); phase_defused(); printf ("So you got that one. Try this one.\n" ); input = read_line(); phase_5(input); phase_defused(); printf ("Good work! On to the next...\n" ); input = read_line(); phase_6(input); phase_defused(); return 0 ; }
writeup 提示我们最好使用调试手段而是不要使用暴力手段,每一关我们都要有对应的正确输入才能保证炸弹不爆炸。
当然以现在的状态做这个实验就是小菜一碟。。
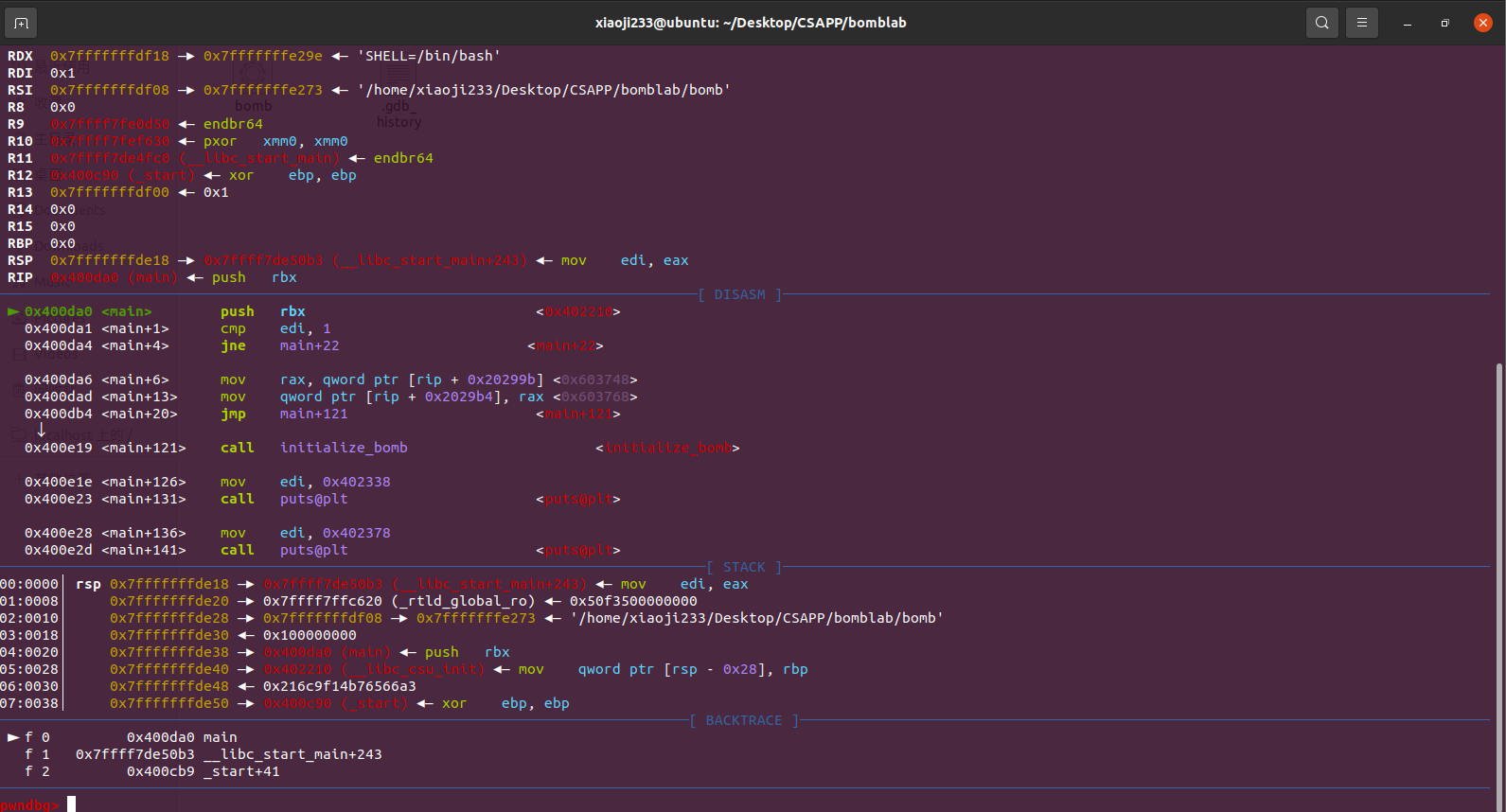
phase_1 那我们还是走流程,先起 gdb 调试。
一般选择 main 下断点,然后 r 去运行。
程序断在 main 函数的第一句中,这里我使用了插件 pwndbg,方便观察调试信息。
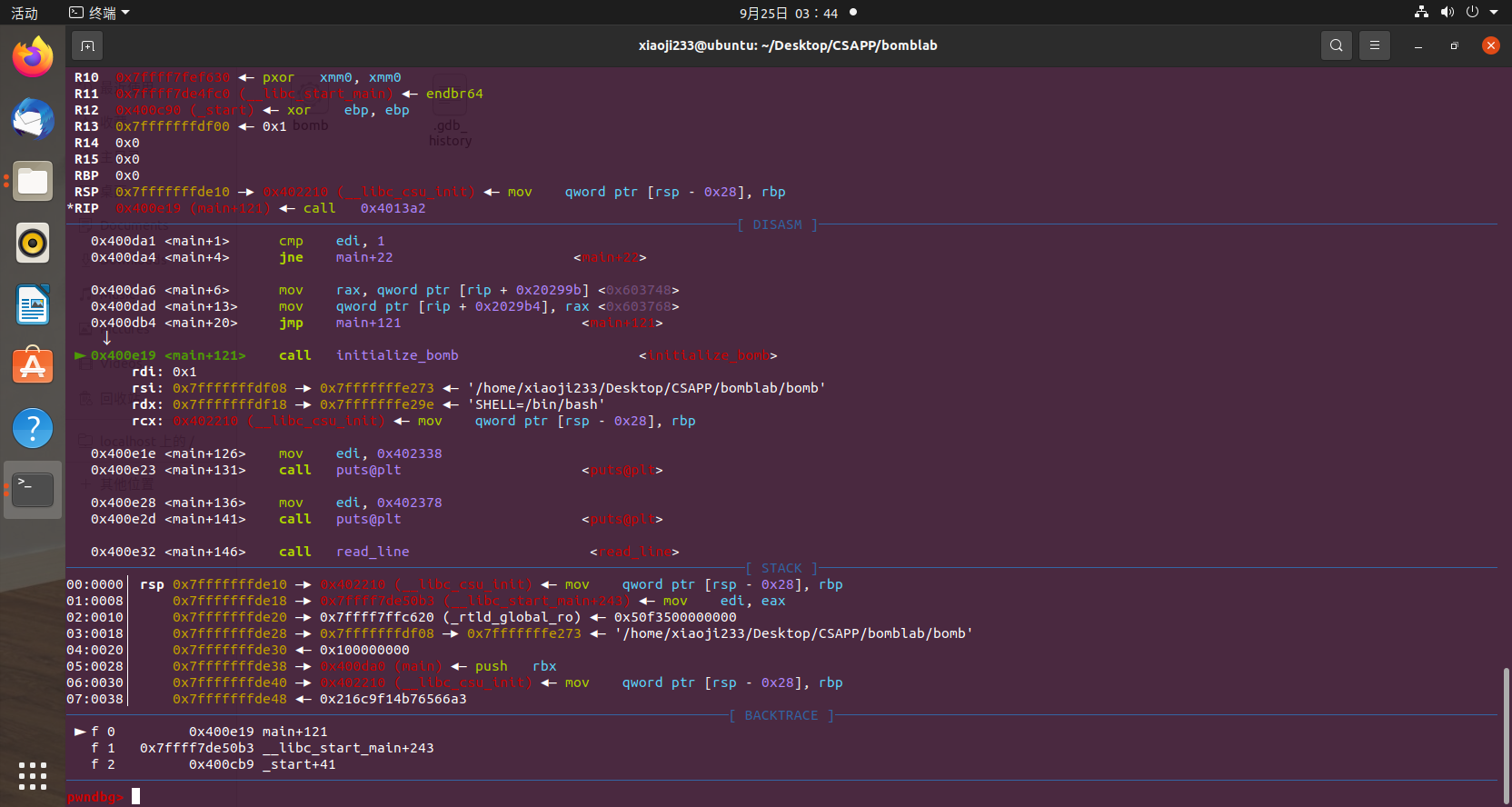
首先我们用 n 步过调试命令去运行到第一个函数
因为这里符号表是没有去的,我们在 gdb 里面还是可以看到这个函数名的,initialize_bomb 可以望文生义,就是初始化炸弹嘛。
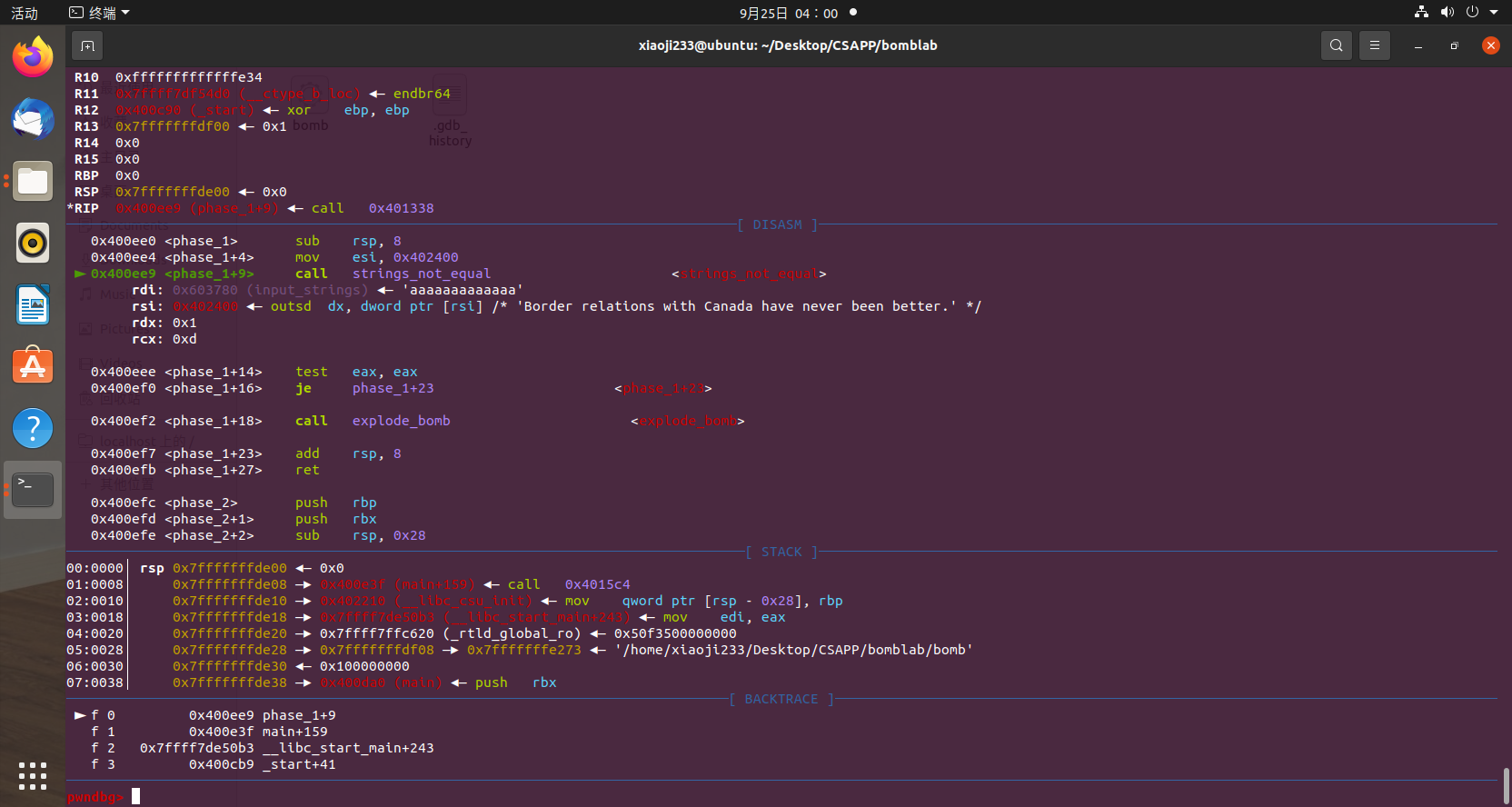
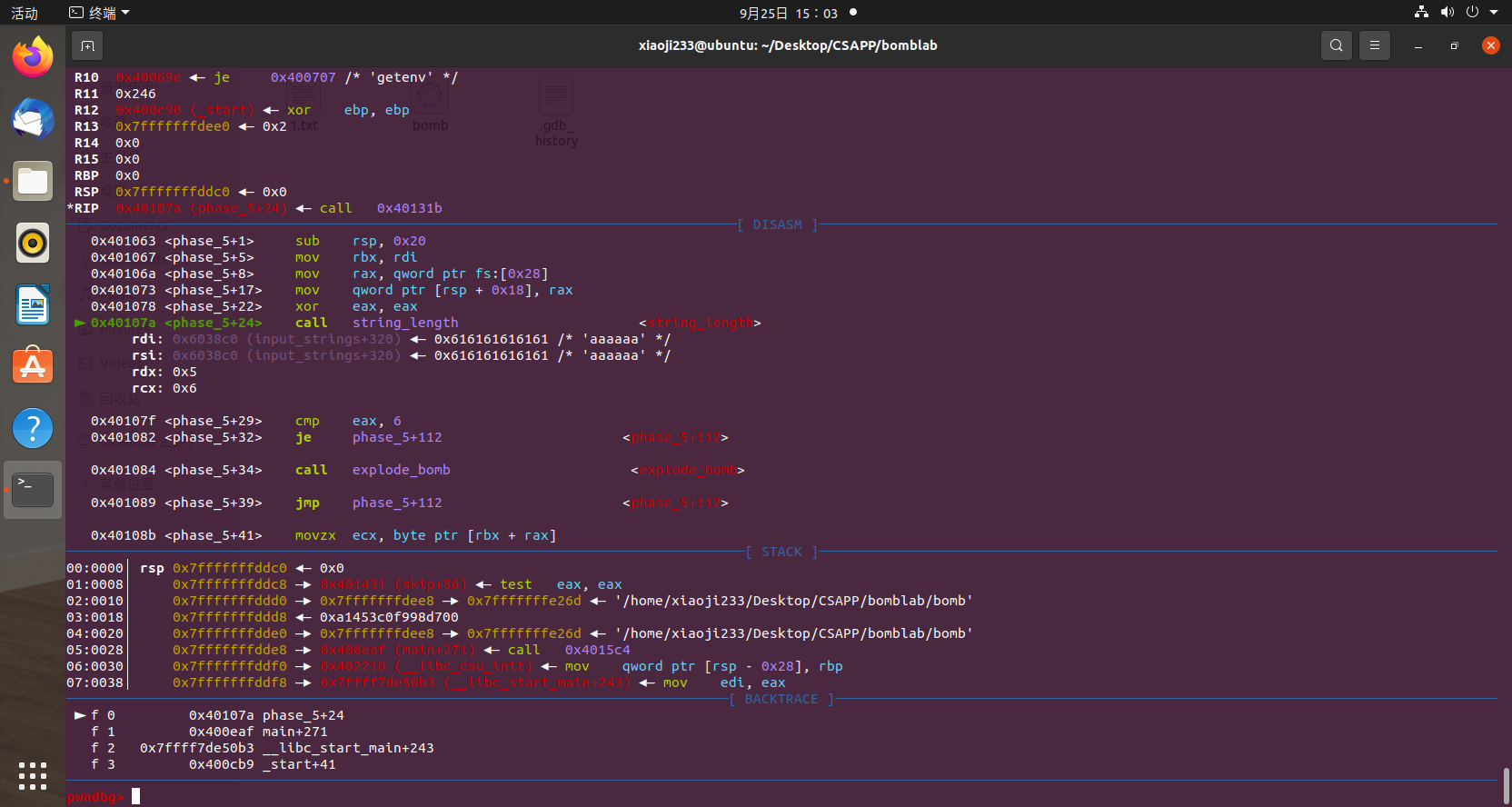
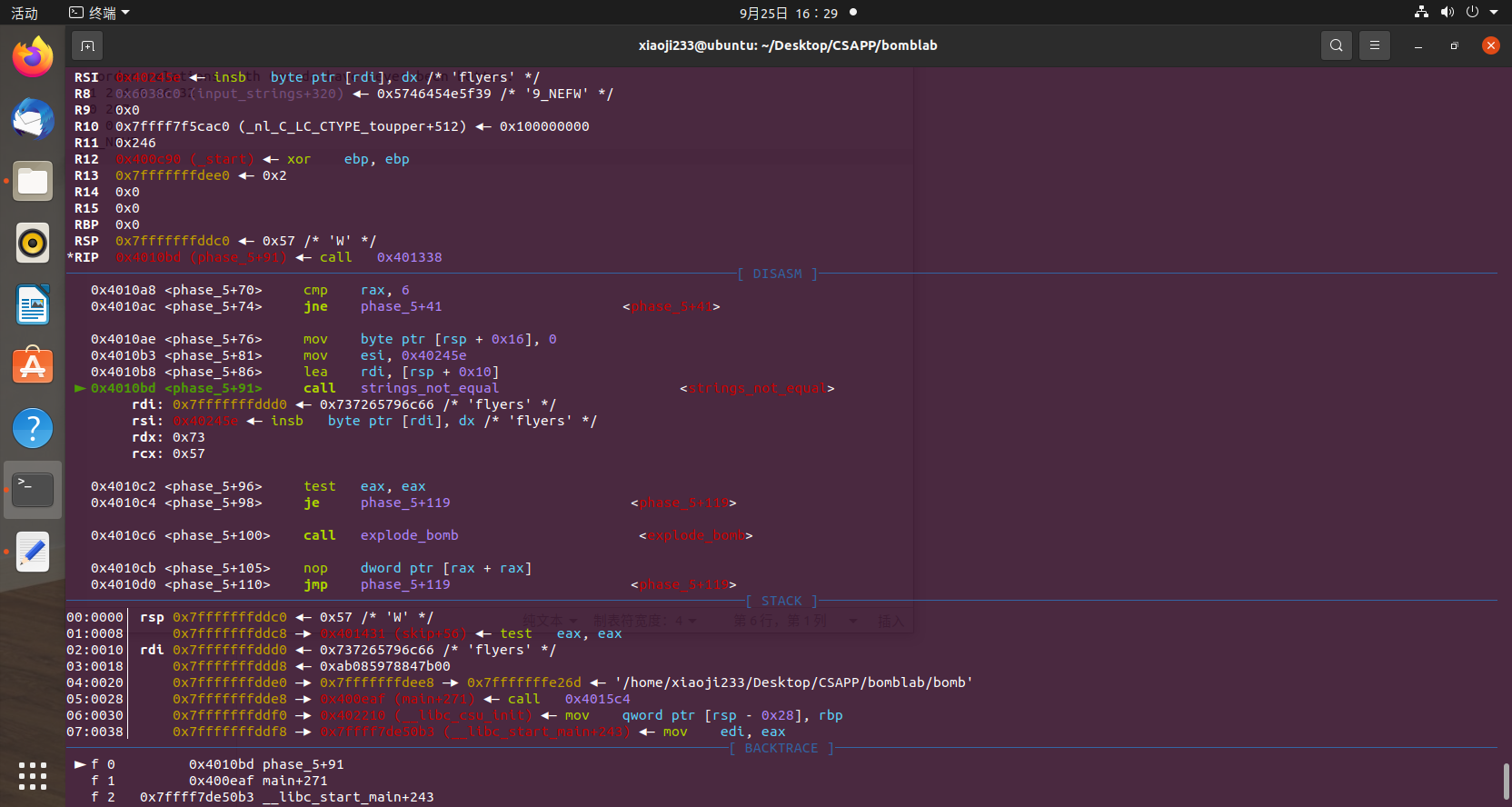
然后接着步过运行过去,运行到 readline 之后发现程序停下,开始要接收我们的输入了,随便输入一串字符之后发现程序输出一段话之后就直接结束了,那么我们直接往回看一看,有一个 phase_1 函数,这里我们不用步过命令了,用 si 步进命令跟到函数里面,然后接着 n,运行之后发现有一个函数叫 string_not_equal
并且 rdi 也就是第一个参数是我们所输入的字符串,第二个参数是一个字符串
Border relations with Canada have never been better.
那么应该就是跟字符串比较的,当然我们输入的字符串肯定跟他们不一样,我们跳过之后发现函数返回值为 1,而后面 test eax,eax,并且为为零跳转。我们很清楚可以看到如果不跳转,下面就直接执行了 call explode_bomb,直接就爆炸,所以我们这里需要输入相等的字符串,成功过第一关
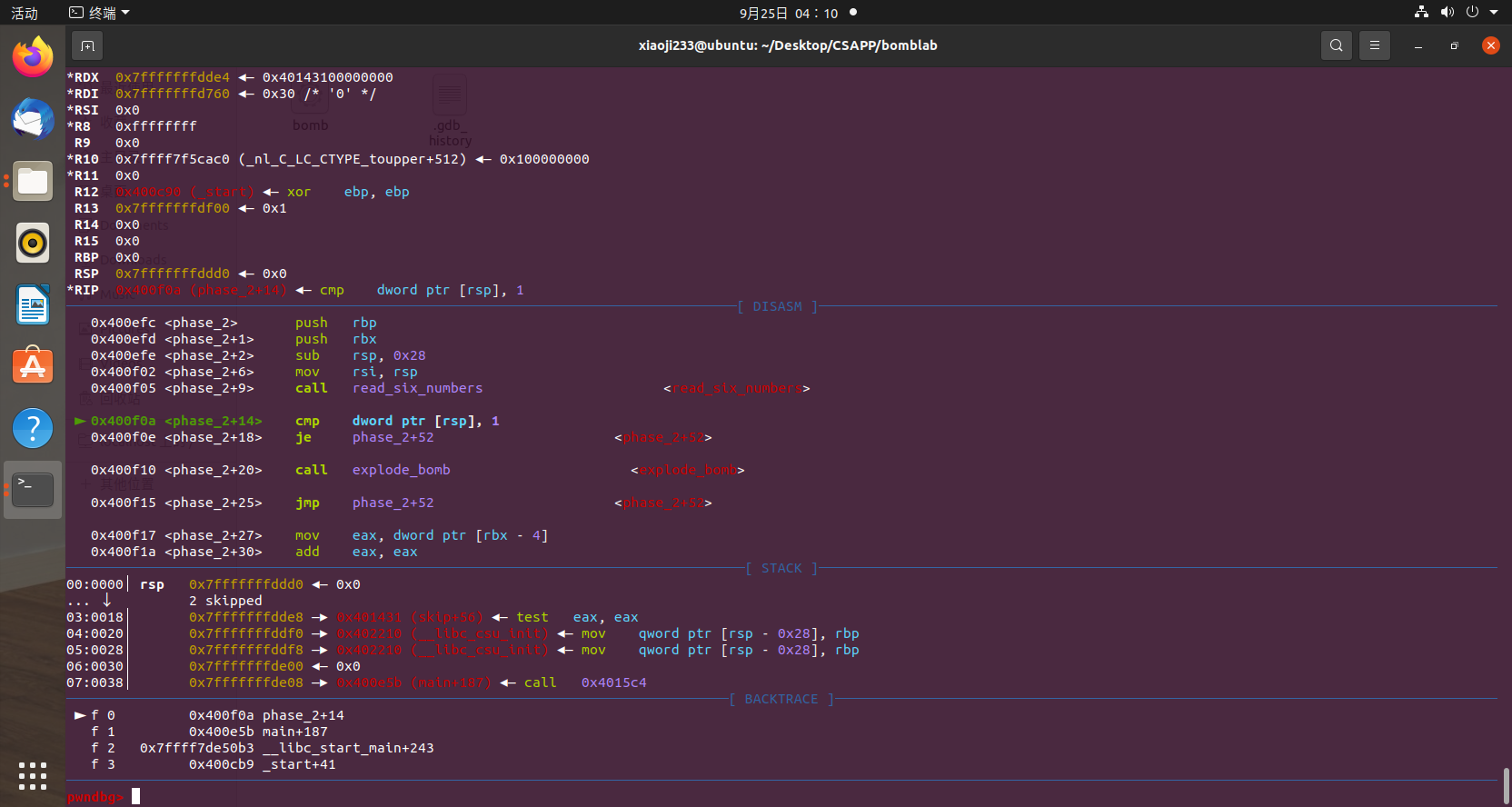
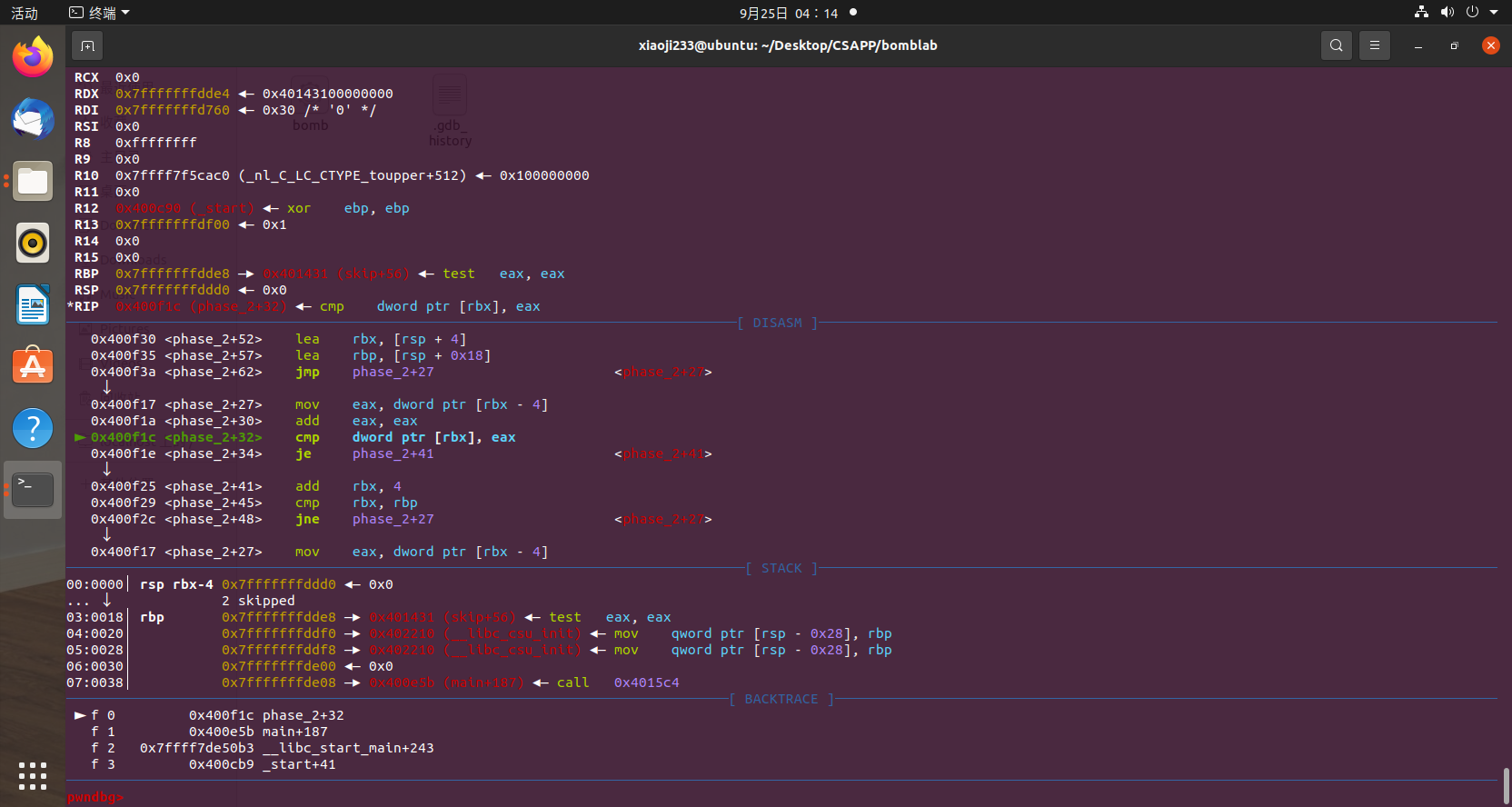
phase_2 这里我们同样随便输入一串字符串,然后跟到 phase_2 函数里面,发现调用了一个 read_six_number 函数,这个函数干什么的已经是太明显了,就是要读取六个数字。
那么我们直接输入 6 个零跟进去看看
这里 6 个数字很明显是存储在了栈上,那么这个地方拿栈中的数据和 1 作比较,如果相等跳转,不相等 call explode_bomb,所以这里我们需要让他相等,当然在调试器里面我们可以为所欲为,直接假装它们一样,跳转到对应的位置。
我们直接设置 $rip 寄存器帮助他跳转过去,使用这个命令:
1 pwndbg>set $rip=phase_2+52
然后发现进入了一层循环:
从上往下分析汇编代码,每次取出 [rbx] 的值与 eax 作比较,循环终止条件为 rbx==rbp,rbx每次循环+4,eax每次执行翻倍。其实这个地方应该就是在遍历我们输入的六个数了,那么第一个数是 1,后面都翻倍,我们不难想到这六个数应该是
1 2 4 8 16 32
第二个炸弹也成功拆除了。
phase_3 这里为了方便调试,我们选择在 phase_3 下断点(b phase_3),然后把前两个拆弹语句写到 1.txt 当中,然后在运行的时候加上参数就能直接跳过前两关,直接进入第三关的调试分析了。
在 gdb 调试器里面我们可以通过 r 1.txt 的方式添加命令行参数。
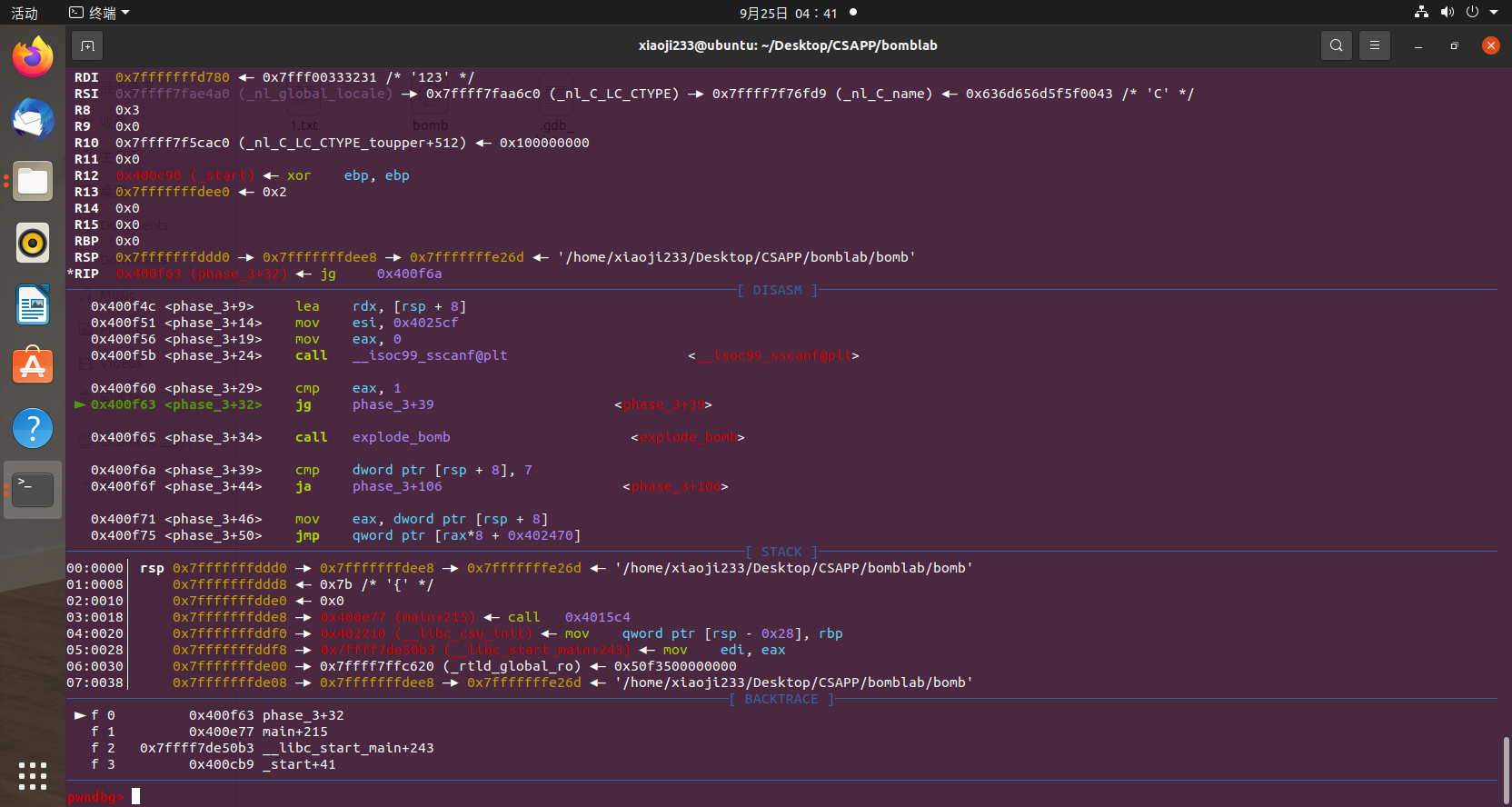
随便输入一串字符串之后,我们断在了 phase_3 函数当中,可以发现中间调用了一个 scanf 函数,并且有参数 %d %d,那么我们也可以推断应该是两个整数,于是我们换 0 0 进去调试看看。
然后下面是判断输入的数的个数要超过 1 个,其实也就是两个数了,然后跳转到下面的 cmp [rsp+8],7 并且超过 7 跳转,我们也可以通过 disass phase_3 看看这个跳转的地方。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 Dump of assembler code for function phase_3: 0x0000000000400f43 <+0>: sub rsp,0x18 0x0000000000400f47 <+4>: lea rcx,[rsp+0xc] 0x0000000000400f4c <+9>: lea rdx,[rsp+0x8] 0x0000000000400f51 <+14>: mov esi,0x4025cf 0x0000000000400f56 <+19>: mov eax,0x0 0x0000000000400f5b <+24>: call 0x400bf0 <__isoc99_sscanf@plt> 0x0000000000400f60 <+29>: cmp eax,0x1 => 0x0000000000400f63 <+32>: jg 0x400f6a <phase_3+39> 0x0000000000400f65 <+34>: call 0x40143a <explode_bomb> 0x0000000000400f6a <+39>: cmp DWORD PTR [rsp+0x8],0x7 0x0000000000400f6f <+44>: ja 0x400fad <phase_3+106> 0x0000000000400f71 <+46>: mov eax,DWORD PTR [rsp+0x8] 0x0000000000400f75 <+50>: jmp QWORD PTR [rax*8+0x402470] 0x0000000000400f7c <+57>: mov eax,0xcf 0x0000000000400f81 <+62>: jmp 0x400fbe <phase_3+123> 0x0000000000400f83 <+64>: mov eax,0x2c3 0x0000000000400f88 <+69>: jmp 0x400fbe <phase_3+123> 0x0000000000400f8a <+71>: mov eax,0x100 0x0000000000400f8f <+76>: jmp 0x400fbe <phase_3+123> 0x0000000000400f91 <+78>: mov eax,0x185 0x0000000000400f96 <+83>: jmp 0x400fbe <phase_3+123> 0x0000000000400f98 <+85>: mov eax,0xce 0x0000000000400f9d <+90>: jmp 0x400fbe <phase_3+123> 0x0000000000400f9f <+92>: mov eax,0x2aa 0x0000000000400fa4 <+97>: jmp 0x400fbe <phase_3+123> 0x0000000000400fa6 <+99>: mov eax,0x147 0x0000000000400fab <+104>: jmp 0x400fbe <phase_3+123> 0x0000000000400fad <+106>: call 0x40143a <explode_bomb> 0x0000000000400fb2 <+111>: mov eax,0x0 0x0000000000400fb7 <+116>: jmp 0x400fbe <phase_3+123> 0x0000000000400fb9 <+118>: mov eax,0x137 0x0000000000400fbe <+123>: cmp eax,DWORD PTR [rsp+0xc] 0x0000000000400fc2 <+127>: je 0x400fc9 <phase_3+134> 0x0000000000400fc4 <+129>: call 0x40143a <explode_bomb> 0x0000000000400fc9 <+134>: add rsp,0x18 0x0000000000400fcd <+138>: ret End of assembler dump.
我们很清楚的可以看到,超过 7 直接跳转 call explode_bomb。
其实这里我们就很清楚地发现了,这里应该是 switch 分发语句,这里有一个 0x402470 + 8*eax ,那么我们不难推测,0x402470 应该就是跳转表的位置了,我们使用命令
打印出跳转表的内容。
我们随便选一个,比如 eax=0 的时候,会跳转到 0x400f7c,这里 mov eax,0xcf,给 eax 寄存器赋值了,然后跳转到 0x400fbe 中和 [rsp+0xc] 进行比较,那么这里应该是我们输入的第二个数了,相等跳转绕过 call explode_bomb 函数。所以第三关,我们填写 0 207 可以过去这一关,当然也可以看看其它跳转位置分别给了啥值,这一关答案不固定。
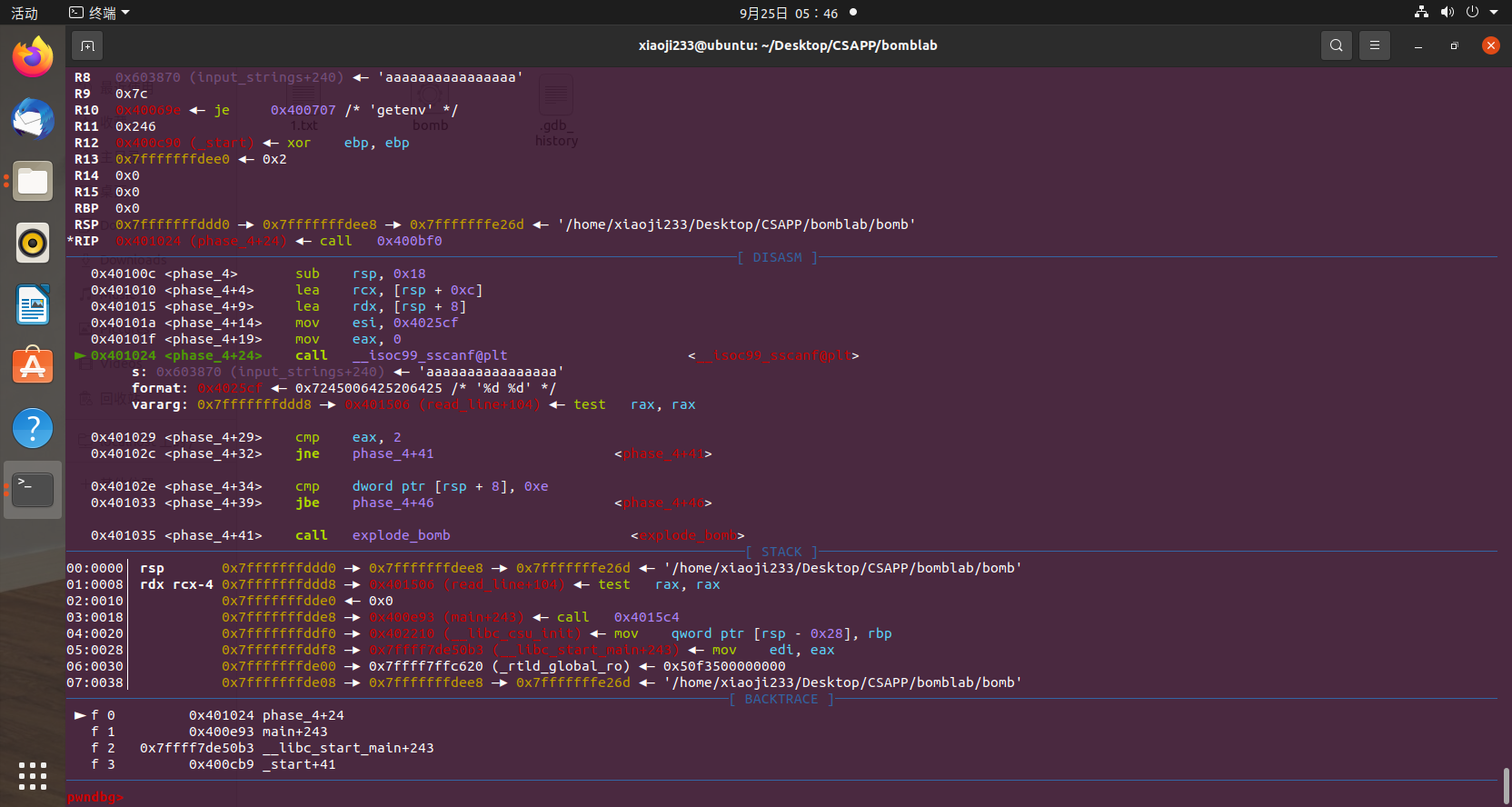
phase_4 同样的思路,我们把前三关的语句保存在文件当中,给第四个函数下断点,运行,输入,来到输入这里。
可以看到依然是两个整数,那重新来,换俩零看看。
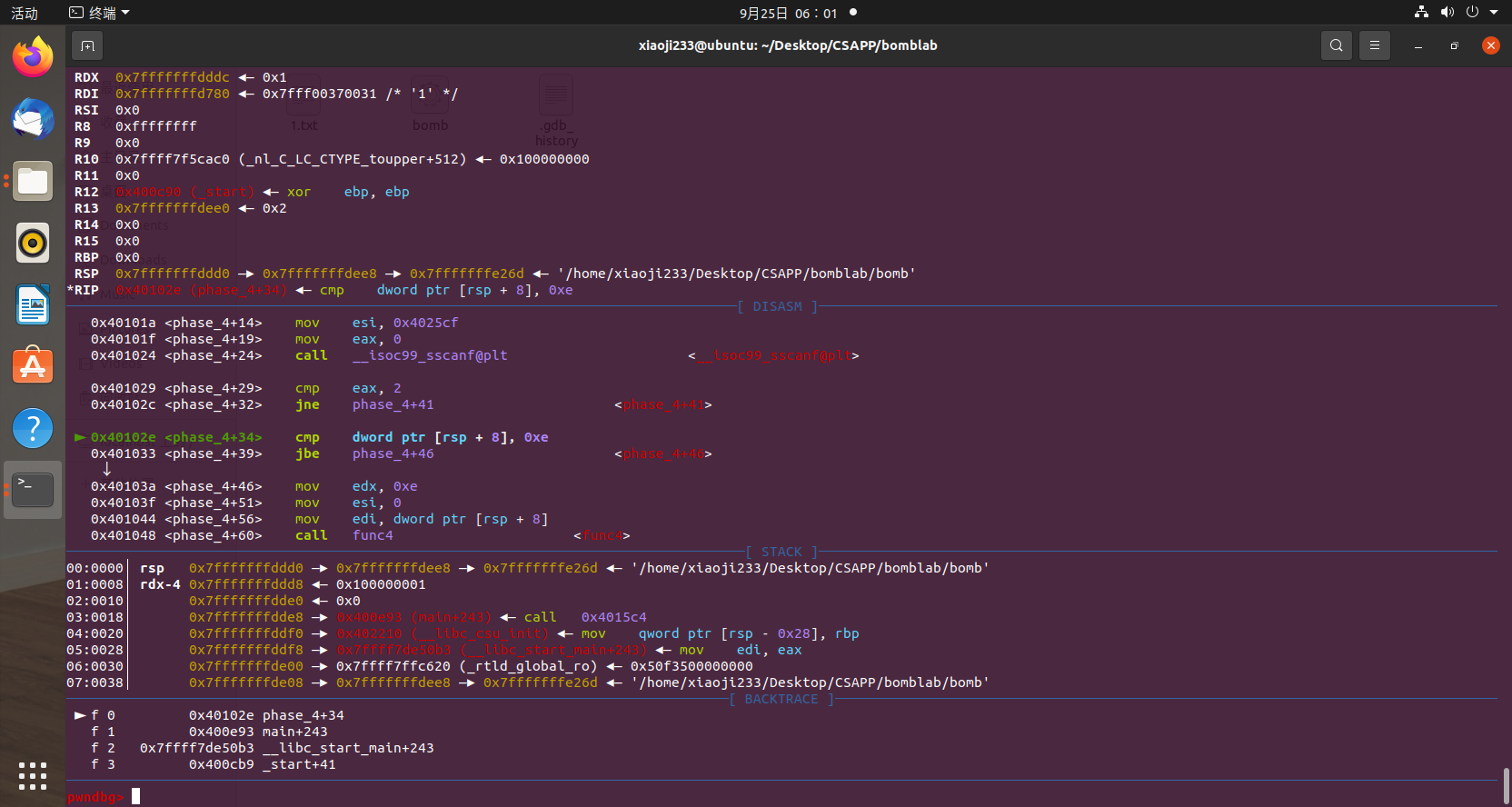
首先,第一个判断
判断输入的,应该是第一个数是否小于 0xe,小于则跳转到 +46的位置,那么我们可以反汇编看看它不跳转会到哪里去。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Dump of assembler code for function phase_4: 0x000000000040100c <+0>: sub rsp,0x18 0x0000000000401010 <+4>: lea rcx,[rsp+0xc] 0x0000000000401015 <+9>: lea rdx,[rsp+0x8] 0x000000000040101a <+14>: mov esi,0x4025cf 0x000000000040101f <+19>: mov eax,0x0 0x0000000000401024 <+24>: call 0x400bf0 <__isoc99_sscanf@plt> 0x0000000000401029 <+29>: cmp eax,0x2 0x000000000040102c <+32>: jne 0x401035 <phase_4+41> => 0x000000000040102e <+34>: cmp DWORD PTR [rsp+0x8],0xe 0x0000000000401033 <+39>: jbe 0x40103a <phase_4+46> 0x0000000000401035 <+41>: call 0x40143a <explode_bomb> 0x000000000040103a <+46>: mov edx,0xe 0x000000000040103f <+51>: mov esi,0x0 0x0000000000401044 <+56>: mov edi,DWORD PTR [rsp+0x8] 0x0000000000401048 <+60>: call 0x400fce <func4> 0x000000000040104d <+65>: test eax,eax 0x000000000040104f <+67>: jne 0x401058 <phase_4+76> 0x0000000000401051 <+69>: cmp DWORD PTR [rsp+0xc],0x0 0x0000000000401056 <+74>: je 0x40105d <phase_4+81> 0x0000000000401058 <+76>: call 0x40143a <explode_bomb> 0x000000000040105d <+81>: add rsp,0x18 0x0000000000401061 <+85>: ret End of assembler dump.
那可以看到,不跳转直接 G 了,所以第一个数要小于等于 14。
我们直接就往后看吧,然后调用 func4 之前,传递了三个参数,rdi 给了我们输入的第一个数,rsi给了0,rdx 给了 14。
我们再看看 func4 的反汇编,是一个递归函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Dump of assembler code for function func4: 0x0000000000400fce <+0>: sub rsp,0x8 0x0000000000400fd2 <+4>: mov eax,edx 0x0000000000400fd4 <+6>: sub eax,esi 0x0000000000400fd6 <+8>: mov ecx,eax 0x0000000000400fd8 <+10>: shr ecx,0x1f 0x0000000000400fdb <+13>: add eax,ecx 0x0000000000400fdd <+15>: sar eax,1 0x0000000000400fdf <+17>: lea ecx,[rax+rsi*1] 0x0000000000400fe2 <+20>: cmp ecx,edi 0x0000000000400fe4 <+22>: jle 0x400ff2 <func4+36> 0x0000000000400fe6 <+24>: lea edx,[rcx-0x1] 0x0000000000400fe9 <+27>: call 0x400fce <func4> 0x0000000000400fee <+32>: add eax,eax 0x0000000000400ff0 <+34>: jmp 0x401007 <func4+57> 0x0000000000400ff2 <+36>: mov eax,0x0 0x0000000000400ff7 <+41>: cmp ecx,edi 0x0000000000400ff9 <+43>: jge 0x401007 <func4+57> 0x0000000000400ffb <+45>: lea esi,[rcx+0x1] 0x0000000000400ffe <+48>: call 0x400fce <func4> 0x0000000000401003 <+53>: lea eax,[rax+rax*1+0x1] 0x0000000000401007 <+57>: add rsp,0x8 0x000000000040100b <+61>: ret End of assembler dump.
假设它的函数是 int func4(x,y,z),那么我们可以大致分析一下它的逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int func4 (x,y,z) { int val=z; val-=y; int i=val; i>>=31 ; val+=i; val>>=1 ; i=val+y; if (i>x){ z=i-1 ; func4(x,y,z); } else { val=0 ; if (i<x){ y+=1 ; func4(x,y,z); val=2 *val+1 ; } } return val; }
以上函数的反编译原型大致是按照汇编语句一条一条翻译过来的,应该比较通俗易懂,对着汇编代码很容易就能读出来。
整合一下,形成下面的语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int func4 (x,y,z) { int val=z-y; int i=val; i>>=31 ; val+=i; val>>=1 ; i=y+val; if (i>x){ val=func4(x,y,i-1 ); } else { val=0 ; if (i<x){ val=func4(x,y+1 ,z); val=2 *val+1 ; } } return val; }
如果 func4 返回非 0,它也是直接跳转爆炸了,所以我们要让 func4 返回 0,它的调用是 func4(x,0,14),然后后面第二个数,为 0直接跳转走了,所以我们第二个这里输入一个 0 才可以。
我们也可以自己编写程序,来检查一下什么时候返回 0。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <stdio.h> #include <unistd.h> int func4 (int x,int y,int z) { int val=z-y; int i=val; i>>=31 ; val+=i; val>>=1 ; i=val+y; if (i>x){ val=func4(x,y,i-1 ); } else { val=0 ; if (i<x){ val=func4(x,y+1 ,z); val=2 *val+1 ; } } return val; } int main () { for (int i=0 ;i<15 ;i++) printf ("%d\n" ,func4(i,0 ,14 )); }
这里可以发现,x=0,1,3,7的时候才能返回 0。
所以我们第一次猜 0 0 大概率就直接过去了。
phase_5 一样的方法进去,然后随便输入个字符串
后面可以i发现有一个对长度的判断,要求长度为 6。
到最后可以发现调用了一个 string_not_equal 函数,被比较的正是 flyers 和我们的输入,难道这题跟第一题一样?
我们输入 flyers 测试看看。
可以发现发生了改变,我们的输入发生了变化,这一题其实比较接近真正的逆向题目了,对输入处理然后和一个字符串进行比较。
我们可以反汇编看看它如何处理的。
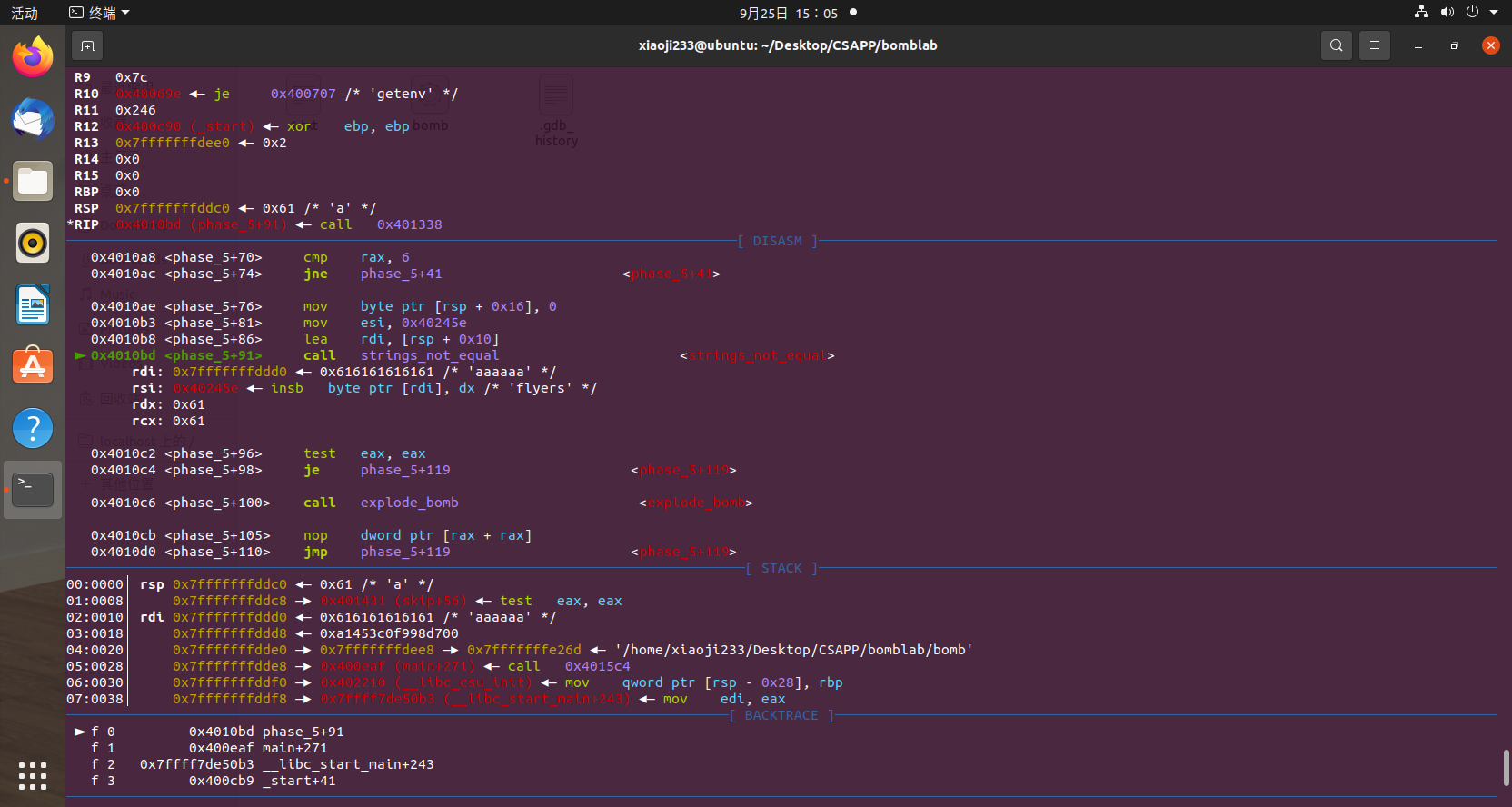
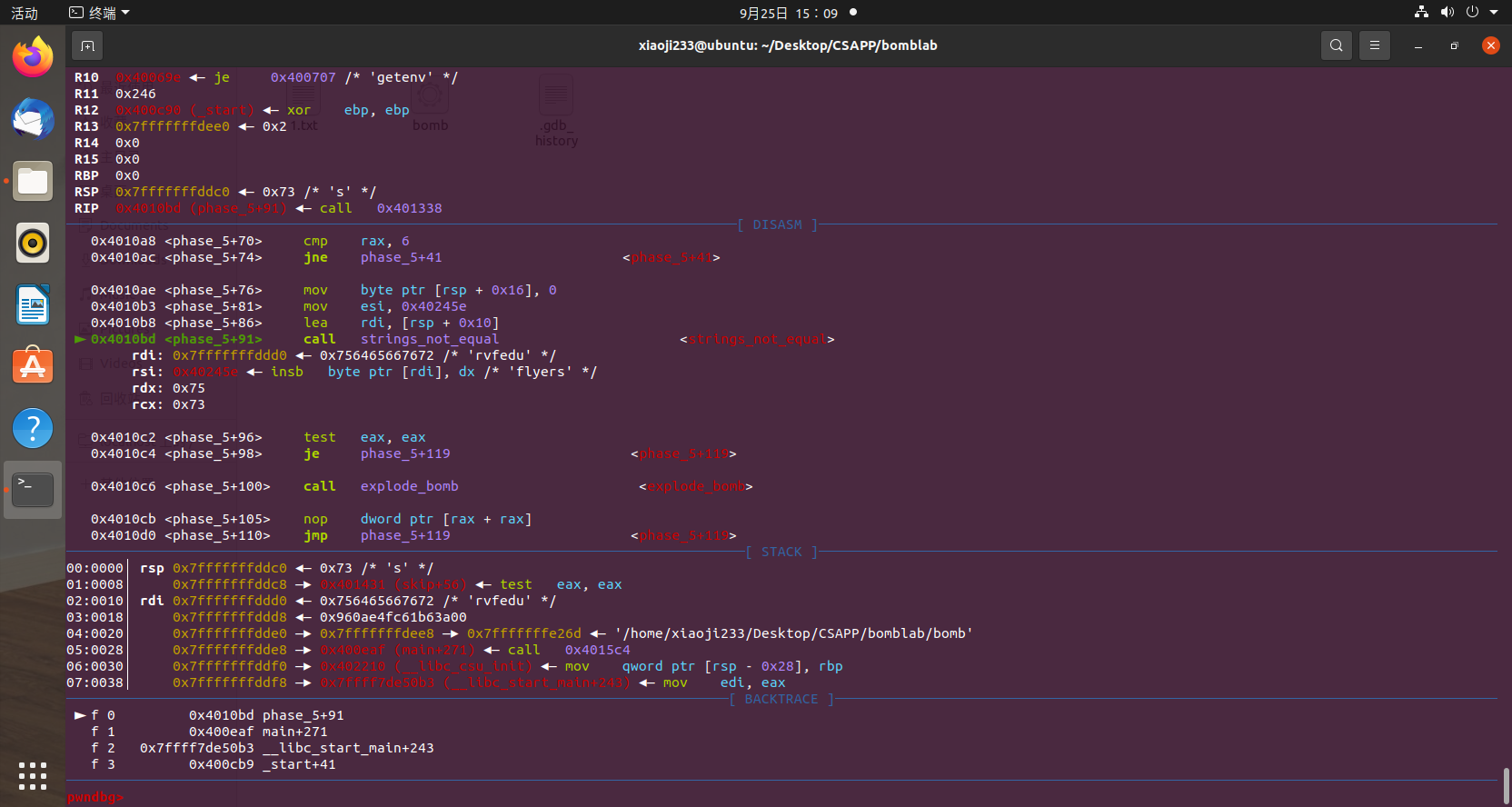
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 Dump of assembler code for function phase_5: 0x0000000000401062 <+0>: push rbx 0x0000000000401063 <+1>: sub rsp,0x20 0x0000000000401067 <+5>: mov rbx,rdi 0x000000000040106a <+8>: mov rax,QWORD PTR fs:0x28 0x0000000000401073 <+17>: mov QWORD PTR [rsp+0x18],rax 0x0000000000401078 <+22>: xor eax,eax 0x000000000040107a <+24>: call 0x40131b <string_length> 0x000000000040107f <+29>: cmp eax,0x6 0x0000000000401082 <+32>: je 0x4010d2 <phase_5+112> 0x0000000000401084 <+34>: call 0x40143a <explode_bomb> 0x0000000000401089 <+39>: jmp 0x4010d2 <phase_5+112> 0x000000000040108b <+41>: movzx ecx,BYTE PTR [rbx+rax*1] 0x000000000040108f <+45>: mov BYTE PTR [rsp],cl 0x0000000000401092 <+48>: mov rdx,QWORD PTR [rsp] 0x0000000000401096 <+52>: and edx,0xf 0x0000000000401099 <+55>: movzx edx,BYTE PTR [rdx+0x4024b0] 0x00000000004010a0 <+62>: mov BYTE PTR [rsp+rax*1+0x10],dl 0x00000000004010a4 <+66>: add rax,0x1 0x00000000004010a8 <+70>: cmp rax,0x6 0x00000000004010ac <+74>: jne 0x40108b <phase_5+41> 0x00000000004010ae <+76>: mov BYTE PTR [rsp+0x16],0x0 0x00000000004010b3 <+81>: mov esi,0x40245e 0x00000000004010b8 <+86>: lea rdi,[rsp+0x10] => 0x00000000004010bd <+91>: call 0x401338 <strings_not_equal> 0x00000000004010c2 <+96>: test eax,eax 0x00000000004010c4 <+98>: je 0x4010d9 <phase_5+119> 0x00000000004010c6 <+100>: call 0x40143a <explode_bomb> 0x00000000004010cb <+105>: nop DWORD PTR [rax+rax*1+0x0] 0x00000000004010d0 <+110>: jmp 0x4010d9 <phase_5+119> 0x00000000004010d2 <+112>: mov eax,0x0 0x00000000004010d7 <+117>: jmp 0x40108b <phase_5+41> 0x00000000004010d9 <+119>: mov rax,QWORD PTR [rsp+0x18] 0x00000000004010de <+124>: xor rax,QWORD PTR fs:0x28 0x00000000004010e7 <+133>: je 0x4010ee <phase_5+140> 0x00000000004010e9 <+135>: call 0x400b30 <__stack_chk_fail@plt> 0x00000000004010ee <+140>: add rsp,0x20 0x00000000004010f2 <+144>: pop rbx 0x00000000004010f3 <+145>: ret End of assembler dump.
很明显可以看到 +41 和 +74 之间形成了一个循环,循环次数为 6,大概是在对字符串每一位进行处理。先到 +41 观察一下寄存器的状态。
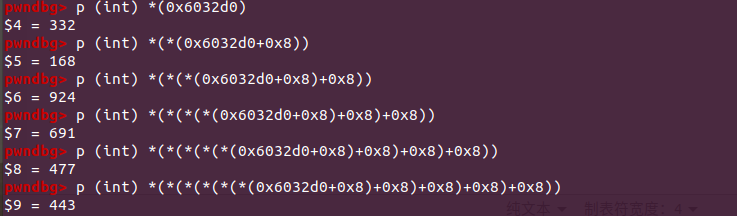
很明显 rbx 就是我们输入的 string,ecx每次取出一个字符然后低四位(&0xf)取出,和 0x4024b0 这个地址相加,所取字节应该会覆盖原来的字符串,那么我们看看 0x4024b0 这个字符串是什么,使用 p (char *)0x4024b0 命令打印。
1 $1 = 0x4024b0 <array> "maduiersnfotvbylSo you think you can stop the bomb with ctrl-c, do you?"
很明显,偏移量只有 0-15,所以实际表也就只是
maduiersnfotvbyl
我们的 flyers 在里面的偏移分别是
这只是低位,高位是不确定的,可以为任意值,我们0-15跑一遍,取出任何一个都可以。
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> int main () { char a[]={+9 ,+15 ,+14 ,+5 ,+6 ,+7 }; for (int i=0 ;i<6 ;i++){ for (int j=0 ;j<=15 ;j++){ putchar ((j<<4 )|a[i]); } putchar (10 ); } }
这里我输入了 9_NEFW
成功过关
phase_6 终于来到了这关,以前没有打过的一关。。
进去依然是读入六个数字。
可以看到读入的六个数存在了栈顶。
后面判断 dword[rsp]-1<=5,说明第一个数的范围就是 1-5。
后面疑似开始循环了,以 r12 寄存器作为循环变量。
后面就是 eax 取 r12 的值,然后再取 rax=dword [rsp+rax*4],这里就是循环读我们输入的数字,放到 rax 寄存器当中。
读到这里好像发现有双重循环,输出反汇编观察一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 Dump of assembler code for function phase_6: 0x00000000004010f4 <+0>: push r14 0x00000000004010f6 <+2>: push r13 0x00000000004010f8 <+4>: push r12 0x00000000004010fa <+6>: push rbp 0x00000000004010fb <+7>: push rbx 0x00000000004010fc <+8>: sub rsp,0x50 0x0000000000401100 <+12>: mov r13,rsp 0x0000000000401103 <+15>: mov rsi,rsp 0x0000000000401106 <+18>: call 0x40145c <read_six_numbers> 0x000000000040110b <+23>: mov r14,rsp 0x000000000040110e <+26>: mov r12d,0x0 0x0000000000401114 <+32>: mov rbp,r13 0x0000000000401117 <+35>: mov eax,DWORD PTR [r13+0x0] 0x000000000040111b <+39>: sub eax,0x1 0x000000000040111e <+42>: cmp eax,0x5 0x0000000000401121 <+45>: jbe 0x401128 <phase_6+52> 0x0000000000401123 <+47>: call 0x40143a <explode_bomb> 0x0000000000401128 <+52>: add r12d,0x1 0x000000000040112c <+56>: cmp r12d,0x6 0x0000000000401130 <+60>: je 0x401153 <phase_6+95> 0x0000000000401132 <+62>: mov ebx,r12d 0x0000000000401135 <+65>: movsxd rax,ebx 0x0000000000401138 <+68>: mov eax,DWORD PTR [rsp+rax*4] 0x000000000040113b <+71>: cmp DWORD PTR [rbp+0x0],eax 0x000000000040113e <+74>: jne 0x401145 <phase_6+81> 0x0000000000401140 <+76>: call 0x40143a <explode_bomb> 0x0000000000401145 <+81>: add ebx,0x1 0x0000000000401148 <+84>: cmp ebx,0x5 0x000000000040114b <+87>: jle 0x401135 <phase_6+65> 0x000000000040114d <+89>: add r13,0x4 0x0000000000401151 <+93>: jmp 0x401114 <phase_6+32> 0x0000000000401153 <+95>: lea rsi,[rsp+0x18] 0x0000000000401158 <+100>: mov rax,r14 0x000000000040115b <+103>: mov ecx,0x7 0x0000000000401160 <+108>: mov edx,ecx 0x0000000000401162 <+110>: sub edx,DWORD PTR [rax] 0x0000000000401164 <+112>: mov DWORD PTR [rax],edx 0x0000000000401166 <+114>: add rax,0x4 0x000000000040116a <+118>: cmp rax,rsi 0x000000000040116d <+121>: jne 0x401160 <phase_6+108> 0x000000000040116f <+123>: mov esi,0x0 0x0000000000401174 <+128>: jmp 0x401197 <phase_6+163> 0x0000000000401176 <+130>: mov rdx,QWORD PTR [rdx+0x8] 0x000000000040117a <+134>: add eax,0x1 0x000000000040117d <+137>: cmp eax,ecx 0x000000000040117f <+139>: jne 0x401176 <phase_6+130> 0x0000000000401181 <+141>: jmp 0x401188 <phase_6+148> 0x0000000000401183 <+143>: mov edx,0x6032d0 0x0000000000401188 <+148>: mov QWORD PTR [rsp+rsi*2+0x20],rdx 0x000000000040118d <+153>: add rsi,0x4 0x0000000000401191 <+157>: cmp rsi,0x18 0x0000000000401195 <+161>: je 0x4011ab <phase_6+183> 0x0000000000401197 <+163>: mov ecx,DWORD PTR [rsp+rsi*1] 0x000000000040119a <+166>: cmp ecx,0x1 0x000000000040119d <+169>: jle 0x401183 <phase_6+143> 0x000000000040119f <+171>: mov eax,0x1 0x00000000004011a4 <+176>: mov edx,0x6032d0 0x00000000004011a9 <+181>: jmp 0x401176 <phase_6+130> 0x00000000004011ab <+183>: mov rbx,QWORD PTR [rsp+0x20] 0x00000000004011b0 <+188>: lea rax,[rsp+0x28] 0x00000000004011b5 <+193>: lea rsi,[rsp+0x50] 0x00000000004011ba <+198>: mov rcx,rbx 0x00000000004011bd <+201>: mov rdx,QWORD PTR [rax] 0x00000000004011c0 <+204>: mov QWORD PTR [rcx+0x8],rdx 0x00000000004011c4 <+208>: add rax,0x8 0x00000000004011c8 <+212>: cmp rax,rsi 0x00000000004011cb <+215>: je 0x4011d2 <phase_6+222> 0x00000000004011cd <+217>: mov rcx,rdx 0x00000000004011d0 <+220>: jmp 0x4011bd <phase_6+201> 0x00000000004011d2 <+222>: mov QWORD PTR [rdx+0x8],0x0 0x00000000004011da <+230>: mov ebp,0x5 0x00000000004011df <+235>: mov rax,QWORD PTR [rbx+0x8] 0x00000000004011e3 <+239>: mov eax,DWORD PTR [rax] 0x00000000004011e5 <+241>: cmp DWORD PTR [rbx],eax 0x00000000004011e7 <+243>: jge 0x4011ee <phase_6+250> 0x00000000004011e9 <+245>: call 0x40143a <explode_bomb> 0x00000000004011ee <+250>: mov rbx,QWORD PTR [rbx+0x8] 0x00000000004011f2 <+254>: sub ebp,0x1 0x00000000004011f5 <+257>: jne 0x4011df <phase_6+235> 0x00000000004011f7 <+259>: add rsp,0x50 0x00000000004011fb <+263>: pop rbx 0x00000000004011fc <+264>: pop rbp 0x00000000004011fd <+265>: pop r12 0x00000000004011ff <+267>: pop r13 0x0000000000401201 <+269>: pop r14 0x0000000000401203 <+271>: ret End of assembler dump.
有点小长,剖分一下:
1 2 3 4 5 6 7 8 9 0x00000000004010f4 <+0>: push r14 0x00000000004010f6 <+2>: push r13 0x00000000004010f8 <+4>: push r12 0x00000000004010fa <+6>: push rbp 0x00000000004010fb <+7>: push rbx 0x00000000004010fc <+8>: sub rsp,0x50 0x0000000000401100 <+12>: mov r13,rsp 0x0000000000401103 <+15>: mov rsi,rsp 0x0000000000401106 <+18>: call 0x40145c <read_six_numbers>
这一部分是读入六个整数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 0x000000000040110b <+23>: mov r14,rsp 0x000000000040110e <+26>: mov r12d,0x0 0x0000000000401114 <+32>: mov rbp,r13 ;let rbp=r13 0x0000000000401117 <+35>: mov eax,DWORD PTR [r13+0x0] 0x000000000040111b <+39>: sub eax,0x1 0x000000000040111e <+42>: cmp eax,0x5 0x0000000000401121 <+45>: jbe 0x401128 <phase_6+52> 0x0000000000401123 <+47>: call 0x40143a <explode_bomb> 0x0000000000401128 <+52>: add r12d,0x1 0x000000000040112c <+56>: cmp r12d,0x6 0x0000000000401130 <+60>: je 0x401153 <phase_6+95> ;exit loop 0x0000000000401132 <+62>: mov ebx,r12d 0x0000000000401135 <+65>: movsxd rax,ebx 0x0000000000401138 <+68>: mov eax,DWORD PTR [rsp+rax*4] ;get number one by one 0x000000000040113b <+71>: cmp DWORD PTR [rbp+0x0],eax ;must be not equal 0x000000000040113e <+74>: jne 0x401145 <phase_6+81> 0x0000000000401140 <+76>: call 0x40143a <explode_bomb> 0x0000000000401145 <+81>: add ebx,0x1 0x0000000000401148 <+84>: cmp ebx,0x5 0x000000000040114b <+87>: jle 0x401135 <phase_6+65> 0x000000000040114d <+89>: add r13,0x4 ;r13 += 4 0x0000000000401151 <+93>: jmp 0x401114 <phase_6+32> 0x0000000000401153 <+95>: lea rsi,[rsp+0x18]
后面这里就是取出第一个值,然后判断减一之后要小于等于 5。
中间的一个循环感觉是要判断我们输入的数两两不一样。
1 2 3 4 5 6 7 8 9 10 0x0000000000401153 <+95>: lea rsi,[rsp+0x18] 0x0000000000401158 <+100>: mov rax,r14 0x000000000040115b <+103>: mov ecx,0x7 0x0000000000401160 <+108>: mov edx,ecx 0x0000000000401162 <+110>: sub edx,DWORD PTR [rax] 0x0000000000401164 <+112>: mov DWORD PTR [rax],edx 0x0000000000401166 <+114>: add rax,0x4 0x000000000040116a <+118>: cmp rax,rsi 0x000000000040116d <+121>: jne 0x401160 <phase_6+108>
这一段逻辑应该就是 遍历所有的数,然后让那些数等于 7-value[i]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 0x000000000040116f <+123>: mov esi,0x0 0x0000000000401174 <+128>: jmp 0x401197 <phase_6+163> 0x0000000000401176 <+130>: mov rdx,QWORD PTR [rdx+0x8] 0x000000000040117a <+134>: add eax,0x1 0x000000000040117d <+137>: cmp eax,ecx 0x000000000040117f <+139>: jne 0x401176 <phase_6+130> ;循环,类似取链表操作。 0x0000000000401181 <+141>: jmp 0x401188 <phase_6+148> 0x0000000000401183 <+143>: mov edx,0x6032d0 0x0000000000401188 <+148>: mov QWORD PTR [rsp+rsi*2+0x20],rdx 0x000000000040118d <+153>: add rsi,0x4 0x0000000000401191 <+157>: cmp rsi,0x18 0x0000000000401195 <+161>: je 0x4011ab <phase_6+183> ;exit loop 0x0000000000401197 <+163>: mov ecx,DWORD PTR [rsp+rsi*1] ;获取循环次数 0x000000000040119a <+166>: cmp ecx,0x1 0x000000000040119d <+169>: jle 0x401183 <phase_6+143> 0x000000000040119f <+171>: mov eax,0x1 0x00000000004011a4 <+176>: mov edx,0x6032d0 ;get basic address 0x00000000004011a9 <+181>: jmp 0x401176 <phase_6+130> ;goto get link list 0x00000000004011ab <+183>: mov rbx,QWORD PTR [rsp+0x20] 0x00000000004011b0 <+188>: lea rax,[rsp+0x28] 0x00000000004011b5 <+193>: lea rsi,[rsp+0x50] 0x00000000004011ba <+198>: mov rcx,rbx 0x00000000004011bd <+201>: mov rdx,QWORD PTR [rax] 0x00000000004011c0 <+204>: mov QWORD PTR [rcx+0x8],rdx 0x00000000004011c4 <+208>: add rax,0x8 0x00000000004011c8 <+212>: cmp rax,rsi 0x00000000004011cb <+215>: je 0x4011d2 <phase_6+222> ;exit loop 0x00000000004011cd <+217>: mov rcx,rdx 0x00000000004011d0 <+220>: jmp 0x4011bd <phase_6+201> ; loop 0x00000000004011d2 <+222>: mov QWORD PTR [rdx+0x8],0x0 0x00000000004011da <+230>: mov ebp,0x5 0x00000000004011df <+235>: mov rax,QWORD PTR [rbx+0x8] 0x00000000004011e3 <+239>: mov eax,DWORD PTR [rax] 0x00000000004011e5 <+241>: cmp DWORD PTR [rbx],eax 0x00000000004011e7 <+243>: jge 0x4011ee <phase_6+250> 0x00000000004011e9 <+245>: call 0x40143a <explode_bomb> 0x00000000004011ee <+250>: mov rbx,QWORD PTR [rbx+0x8] 0x00000000004011f2 <+254>: sub ebp,0x1 0x00000000004011f5 <+257>: jne 0x4011df <phase_6+235> 0x00000000004011f7 <+259>: add rsp,0x50 0x00000000004011fb <+263>: pop rbx 0x00000000004011fc <+264>: pop rbp 0x00000000004011fd <+265>: pop r12 0x00000000004011ff <+267>: pop r13 0x0000000000401201 <+269>: pop r14 0x0000000000401203 <+271>: ret
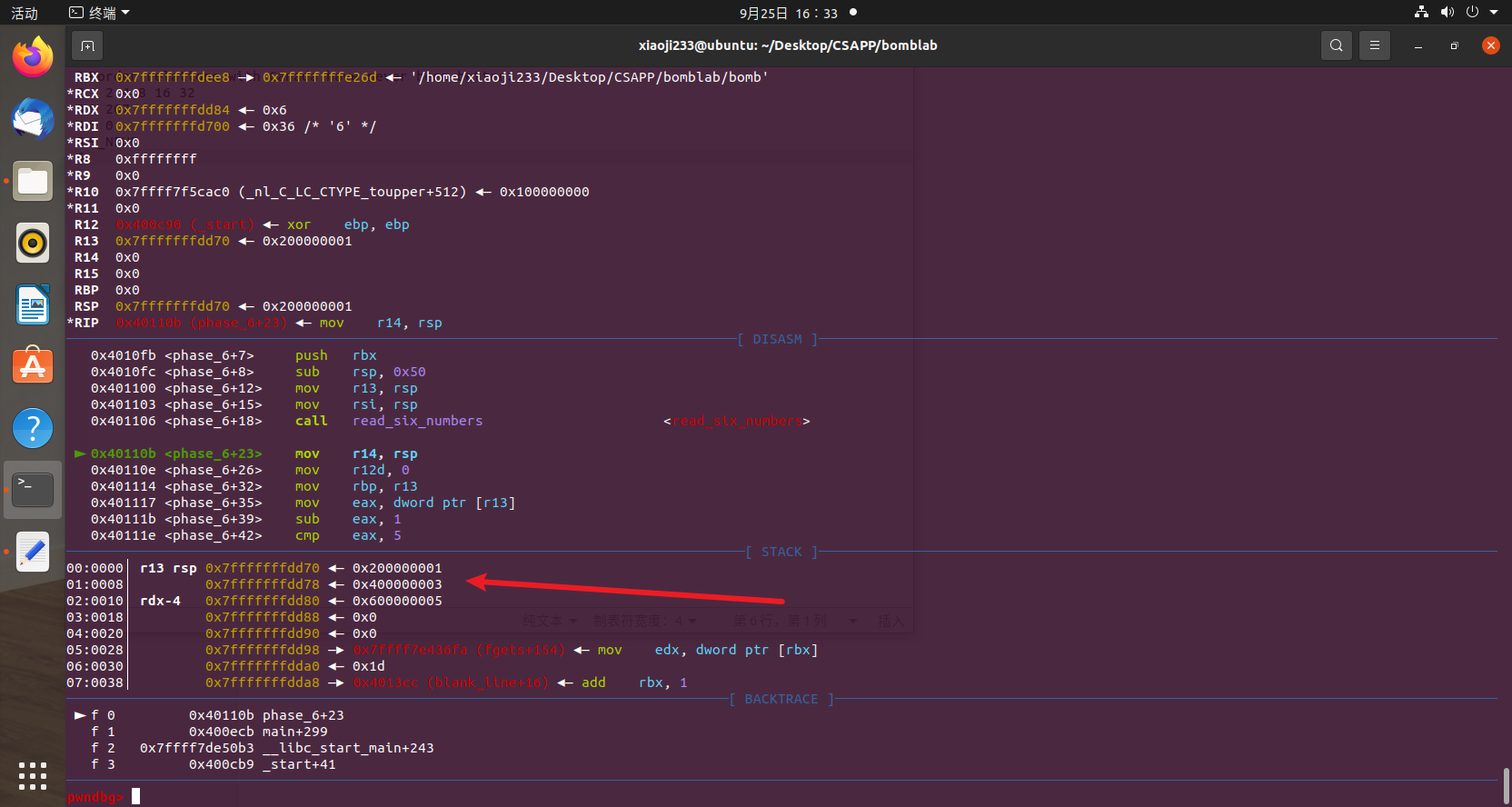
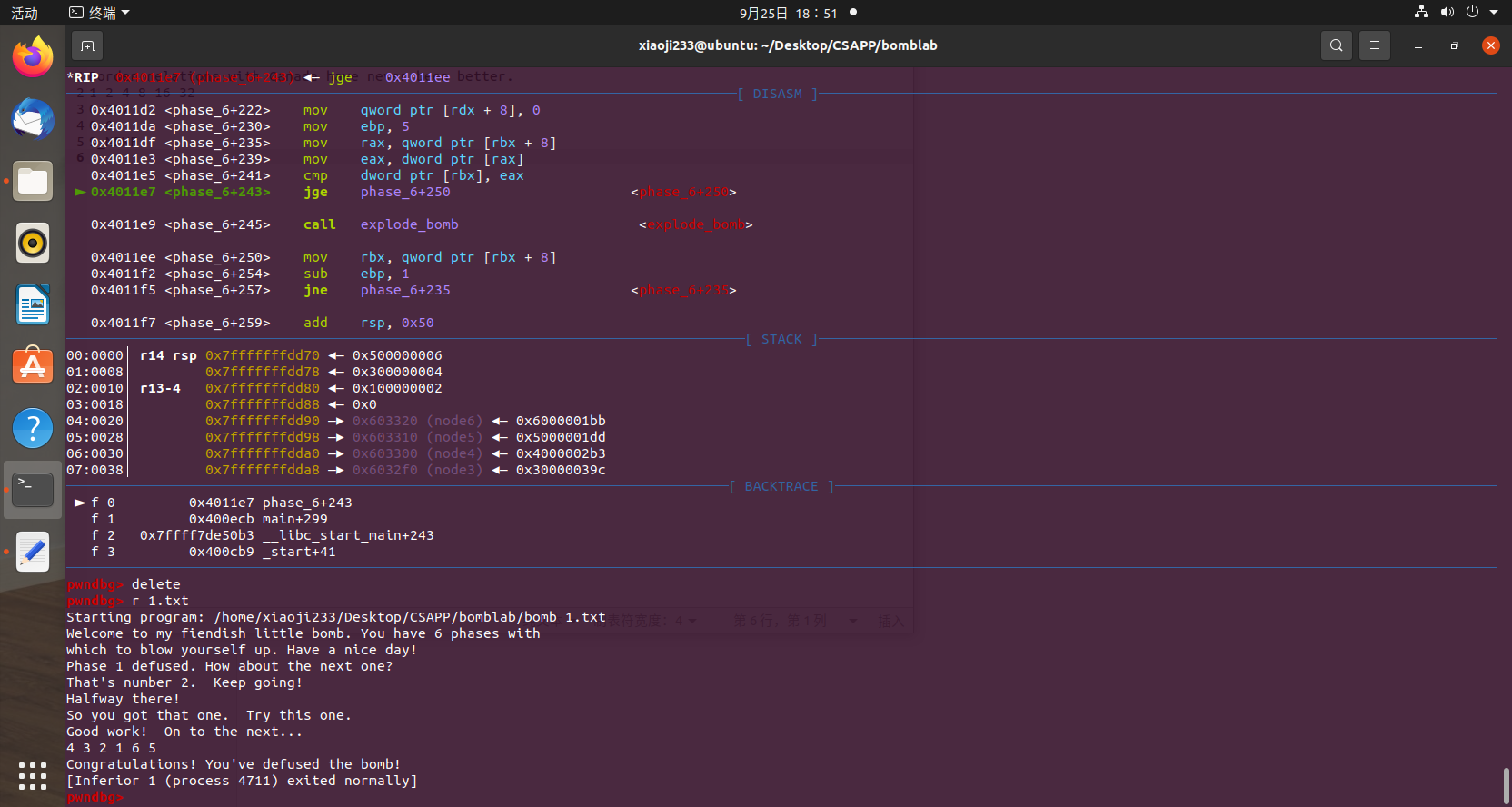
它这里链表有一个基址,我们从基址这里开始,看看里面的 value。
他应该是按照我们输入的一个数字,然后取出链表对应深度的值,放到栈后面,然后比较是否严格 >=,如果有一个小于就不行。我们在 +222 处下好一个断点,然后 1 2 3 4 5 6 输入看看。
可以发现,这里的 0x1bb 就是链表最后一个值,因为我们输入 1,然后用 7 减去得到了 6,所以第一个值就是最后一个值,我们先调整一下它自己的一个大小,排个序。下标排序为 2 1 6 5 4 3,再拿 7 减去得到 5 6 1 2 3 4。
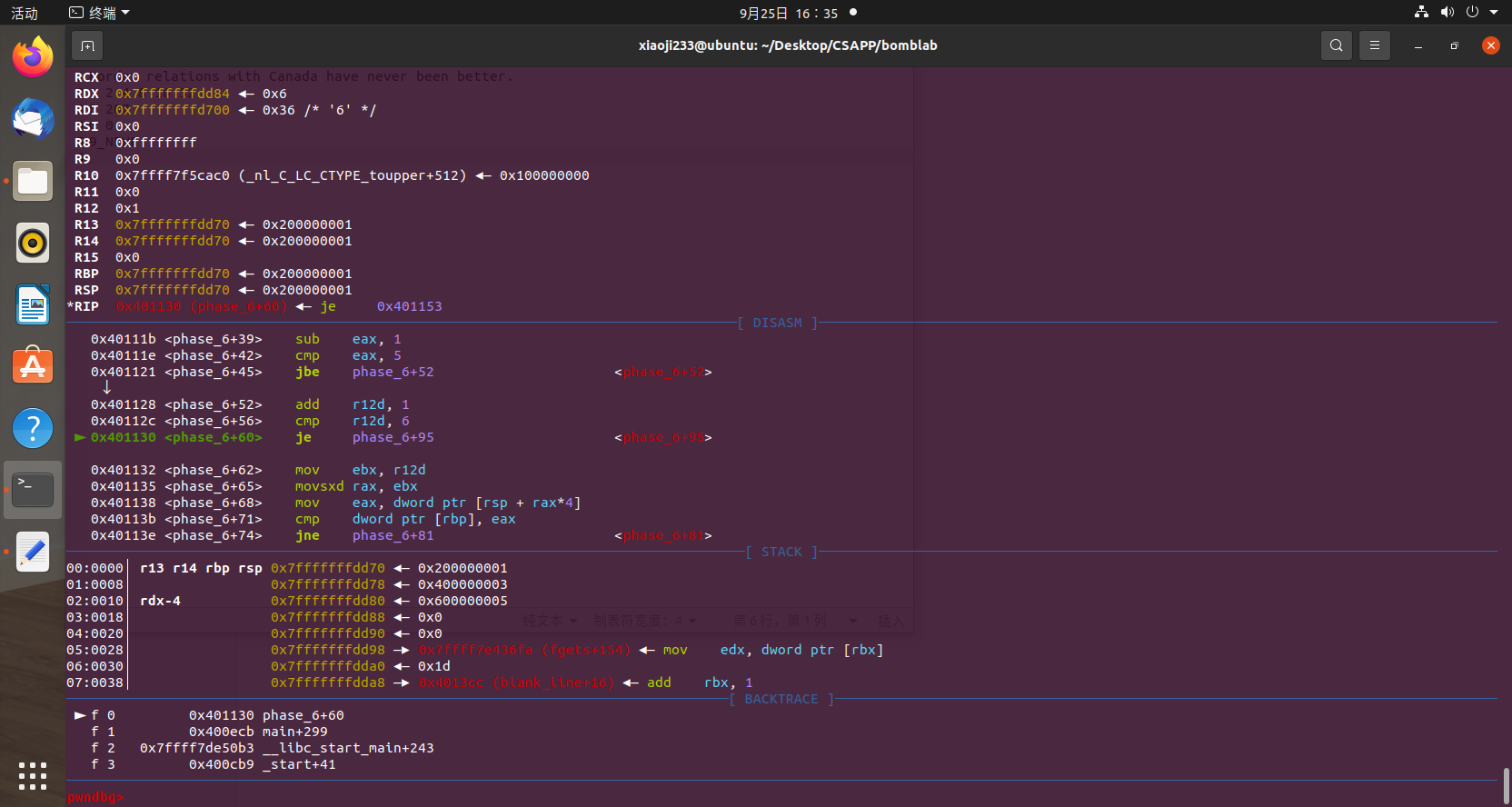
但是输入发现还是爆炸了,动调,发现它要降序,后面的要大于等于前面的,但是因为前面判断不能重复,所以我们降序,倒一下顺序就可以实现了。
4 3 2 1 6 5
总结 phase_1:学习了 if 选择结构的汇编代码,并学会逆向分析选择结构的代码。
phase_2:学习了循环结构的汇编代码,并学会逆向分析循环结构的代码。
phase_3:学习了 switch 分发器的汇编代码,并用跳转表实现了其结构。
phase_4:学习了递归结构的汇编代码,并学会其逆向分析的方式。
phase_5:学习了基本逆向工程的写法,基本的字符串转变算法,了解了如何破解一个注册机程序。
phase_6:学习了链表的数据结构,结合数据结构合理地推测程序逻辑。
CSAPP:attacklab 待更新
CSAPP:bufferlab 待更新