关于钉钉保存回放的方式
最近需要下载钉钉的录屏回放,但是管理员禁止了下载,找到了众多的方法都不得行,后面自己开辟了一个方法(我也不敢确定是不是没有人用这个方法,反正这个方法不是通过搜索得到的。。
先说说我通过搜索资源得到了些什么方法吧,其实大多数就指向一种方法——通过fd抓包找到m3u8的下载地址,然而我在用fd抓包的时候并没有找到m3u8的下载地址,也有说用旧版本的钉钉的,但是我发现根本扫不上去,于是我仔细观察fd得到的包,发现播放视频的时候大部分出现了 .TS文件格式的url请求。
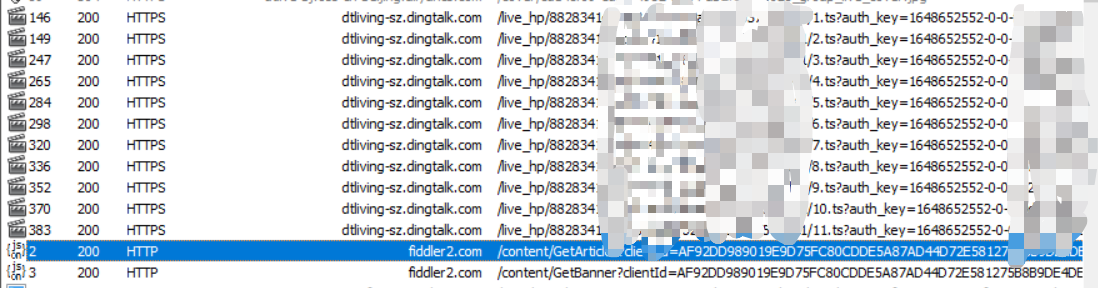
可以看到每过一会就会请求一个对应的 ts 文件,我也去搜了一下 ts 文件的含义,差不多就是视频的切片。因此如果我能得到所有的ts的下载地址,那么我就相当于得到了这个视频。
但是在请求这个 ts 文件的时候必须加上一个 auth_key 参数,然后这个参数貌似也是个随机的散列值,目前信息有限没办法计算出这个散列值的排布规律,但是我能得到一个最朴素的做法:暴力得到所有的 ts 的url,然后一个一个下载,最后用 ffmpeg 去合并就好了。
然而这里我们并不需要看完所有的视频,我们可以快进,我理解的原理是这样的:假如把你的视频切成 20S一片,在你需要的时候请求,然而假如我不看完,直接跳过这个请求,那么它马上就会请求下一个视频的地址,然后此时被我们捕获到了,之后循环往复我们就能快速地得到所有的请求url,这里的话仅复制url可以快速把url全部复制过来。
这里我选择按键模拟器去点击这个右键播放,然后间隔频率设置成0.2S,每看1S跳过50S,相当于快进50倍,一个50min的视频我们在1min就能整完,这个效率还是不错的,如果发现ts有丢失那么你可以定位到那个地方重新观察一下请求,然后url复制过来。
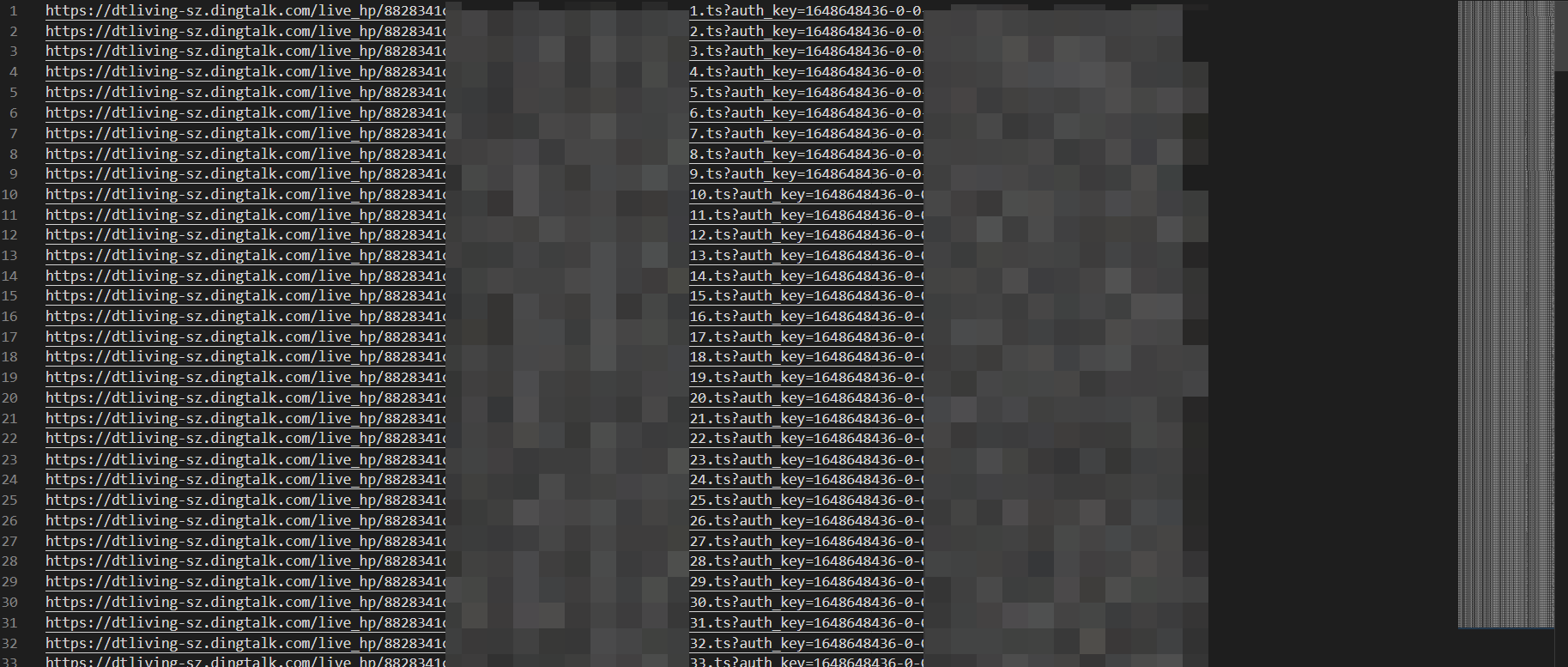
我本来想这么多url用爬虫读取url一个个爬然后保存的,结果不知道为啥报错了,于是我选择最蠢的办法:cmd命令。
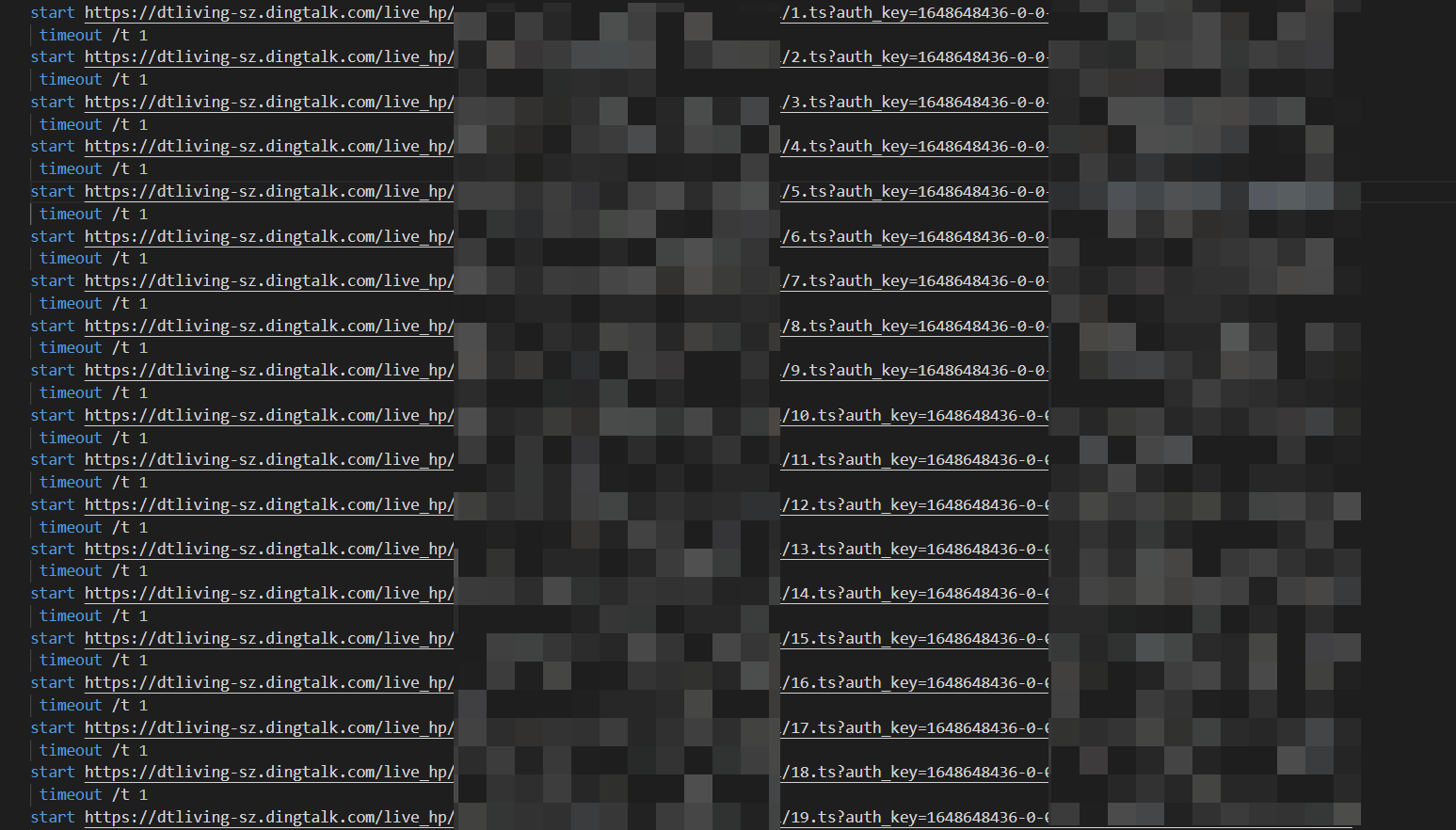
在所有url前加上start,然后后缀改一下bat,为了防止电脑卡顿,在每一个start前加上一个暂停的命令,然后我们得到了一个这样的文件:
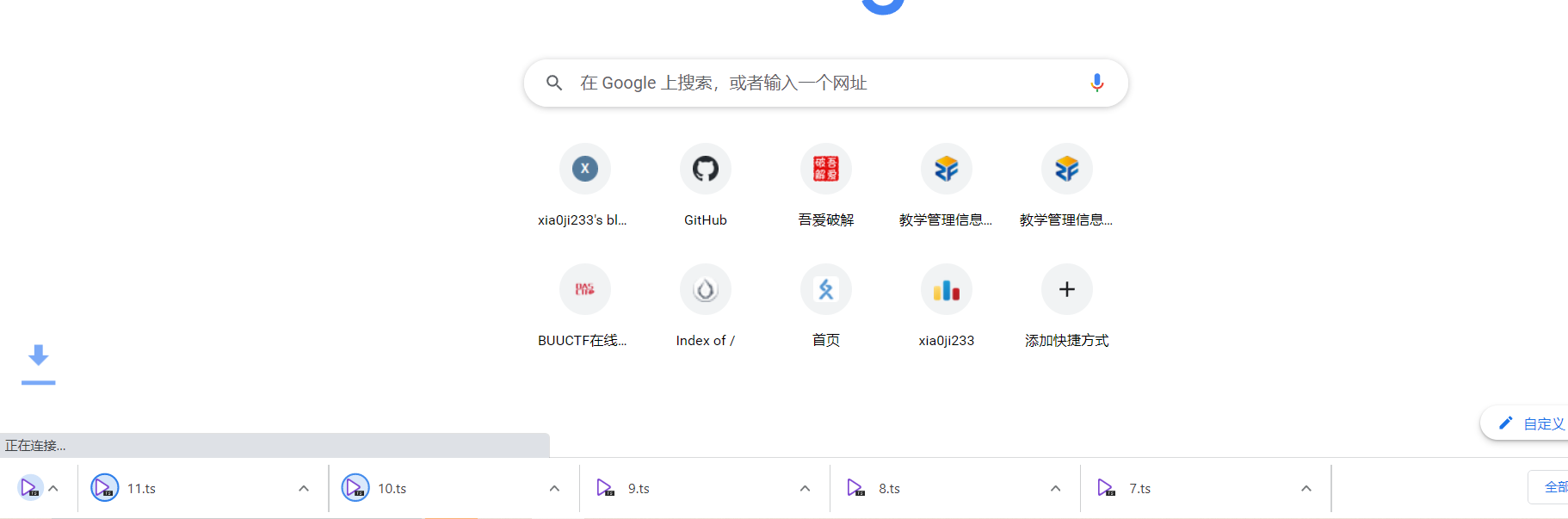
最后就是枯燥的请求了,这个等着吧,如果你觉得电脑hold的住那么你可以不加暂停的,它会周期弹网页出来,情况就是这样子的:
我还发现一个问题,就是它有时候这个回放并不是严格的就是正整数递增的,中间我有遇到过那种 10000001.ts 的文件,就是突然这样的,也不知道为啥,所以最后写合并指令的时候也比较难,但是难处千千万,靠自己还是能解决的。选择直接在里面放一个python脚本自动合并,合并的命令是这样的:
1 | ffmpeg -i "concat:文件1|文件2|文件3|……|文件n" -c copy output.mp4 |
里面主要的就是要扫一下目录获取所有的文件名并让他们按一定顺序排列,这个我也直接放一下吧,也挺简单的,没什么需要解释的。
1 | import os |
如果不放心可以先print一下看看得到的cmd是什么样的,下面给出我的目录图和运行图:
最后就是运行一遍那个命令了,看看有没有得到你们心心念念的视频吧。