malloc源码分析
学了这么久堆漏洞了,我想应该把glibc的malloc和free源码解析写一下了,希望能帮助一下刚上路的师傅,同时也巩固一下自身知识。
内存分配
我们平时写程序的时候,某些变量可能需要在开始就分配内存,这些内存是不可避免的。那么这些内存就是静态分配的,当程序编译完成之后,它就确定了占用这么多的内存。但是有时候,实际问题的规模没有预期那么大,我们不一定需要很大的内存,如果每次都按最大考虑那么就有很大一部分内存是被浪费的,这就是静态分配内存的弊端,虽然咱打acm的时候都是静态分配的,但是这没啥,因为每个问题不要超过它的总内存上限问题就不大(狗头。但是在内存不足的年代,如果都这样使用静态分配内存的方式,那么计算机的效率会被拖垮很多,所以就有动态分配内存的概念了。
glibc采用ptmalloc的管理方式去分配内存。
ptmalloc2的分配策略
那么动态分配内存要怎么去分配呢?如果我们需要占用除了我程序本身占用的内存以外的一块内存,那程序指定是没权限用的,得先向操作系统申请这一块内存的使用权。而操作系统没那么闲,分配几个字节的内存都要它去管,操作系统管理都是按页式的管理。而一页的内存是0x1000B,如果每一次申请我都向操作系统申请,每一次归还都直接归还给操作系统那么必定会增大操作系统的负担。因此分配内存的时候可以按照一个策略去分配,分配一定得尽量避免过多地使用系统调用,归还的时候可以等到程序结束时一并归还,这样的话操作系统的负担就大大下降了。
ptmalloc2的分配方式会在你第一次malloc的时候向操作系统申请0x21000B(132KB)的内存,然后后续分配就不会向操作系统申请内存,只有用完了的时候才会再次申请内存。
操作系统的问题解决了之后我们再来看看glibc怎么处理具体的分配细节。分配的时候我一定是切出一块特定大小才是最优的策略的,比如程序malloc(4),那我接切个4字节的内存给它用,malloc(1)那就给它一字节去使用。然而现实没有那么理想,因为如果我切下来的块用户程序完全可写的话,那么我怎么区分这个内存块是否被使用呢?然后内存块的分界线又如何界定呢?所以分割内存块的时候不可避免地要在内存块中额外开出一部分区域用于管理。那么可以在每个分配的内存块加上一个int数据作为此内存块的size,64位的操作系统可以使用long long。同理,为了管理方便,glibc在分配chunk的时候也并不是分配这么多就只能写这么多的。它也不想闲到去管1字节2字节这样的内存块。而且如果有这样的内存块,那么在分配指针的时候内存没办法对齐会出现很多麻烦的事。所以在分配内存块的时候,有一个SIZE_SZ,一次分配的内存必定是SIZE_SZ*2的整倍数,SIZE_SZ在32位操作系统下的值是4,64位的值是8。为了方便,以下把内存块统一叫chunk。
以32位操作系统为例,size的值必定为8的整数倍,二进制角度下看来,低三位永远是0,这样有点浪费了内存,因此规定size的低三位不作为实际的chunk大小,而是标志位。三个标志位从高位到低位分别是:
NON_MAIN_ARENA:是否为主分配,0表示是主分配,权值为4IS_MMAPPED:表示内存是否为mmap获得,0表示不是,权值为2PREV_INUSE:表示前面一个内存块是否被使用,0表示不被使用,权值为1
在64位操作系统中,多出一个标志位,但是这个标志位无任何意义,可能后续会赋予别的意义,但是它一样不影响chunk的大小。
在看malloc源码的时候可以看到一个宏定义。
1 |
|
那么就可以看到chunksize在取实际size的时候与了一个0xfffffff8,忽略了最低三位,64位操作系统则会忽略最低四位。
以下例子为64位操作系统
chunk最小的大小为0x20,为什么没有0x10大小的chunk呢,这么看来size占了8字节还能有8字节给用户去写似乎没问题。大不了我超过8B再分配0x20大小的内存嘛,这个疑问先放一下,我们来看看这样的策略它还有没有什么问题。
如果一个chunk被确定释放了,那么该以什么方式去管理。你会想到前面有一个prev_inuse位可以确定一个堆块是否被释放,你会想到改下一个chunk的标志位就可以了,但是如果这个内存块再次被需要呢,难道去遍历每一个chunk,一来要看size符不符合,二来还要看它有没有被使用,这样时间开销太大了。因为空闲的chunk可能散落在内存各个角落,管理零碎内存最好的办法就是链表。链表还得有表头,这个表头其实就是我们的main_arena中的bin。因此chunk上还得有一块内存是指针,指针又占了8个字节。
但是你可能想到,指针它只在块被释放的时候有用啊,0x10的块,一个size,一个指针,被分配的时候用指针作为数据域,被释放的时候指针用于链式管理。这样就解决了,这样也的确没问题。但是看看它这样的分配策略还有没有问题?如果我多次分配chunk很小的块,free之后它们便只能用于分配这么大的内存了。如果不加另一种策略组织起来,导致内存碎片越来越多,就容易耗尽系统内存。
那么就有ptmalloc的又一个策略:尽量合并物理相邻的free_chunk。咱们前面一直提到切割内存块,合并内存块就是切割的一个逆过程。在合并的时候我可能前面会有free的内存块,后面也会有free的内存块。那么我怎么在只知道我自身信息的情况下准确找到前后的chunk具体在哪呢。
想找到后面的很容易,我知道我自己所在的位置(指针),也知道我的size,那么相加就可以找到后面的size了。那么我如何找前面的size在什么位置呢?所以就不得不再开辟一个内存来存前一个chunk的信息了。通过prev_inuse位我很容易得知前一个chunk有没有被free,但是我并不知道前一个chunk的大小啊。所以在一个chunk的结构体,在size之前还会有一个prev_size。与前面那个指针同理,我只有在前一个块被free需要合并的时候才会想看看它在哪,他要是都还在用我都没必要去使用这个prev_size字段了。但是要注意,这个prev_size是服务于上一个chunk的。所以一个chunk的结构体就有0x10个不得不分配的字节,而且自己还不能用。因此0x10的chunk就没有意义了。所以源码中也会找到这样的定义:
1 |
说了这么多了,ptmalloc的策略大致总结一下就是:
一次系统调用会分配大块内存
程序结束后统一归还内存给操作系统
方便管理,内存分配尽量对齐,也就是所谓的size为某某整倍数
尽量分配最小能满足的内存块
链式管理空闲空间,适当的时候合并物理相邻的
chunk
而且根据以上分析我们可以得出一些关于chunk的结构体。
1 | struct chunk{ |
至此,我们大致就明白了ptmalloc的分配方式。
ptmalloc2的具体分配策略
前面我们讲到了,对于空闲块使用了链式管理方式。但是对于不同大小的chunk,它又有细分。这里先给一个概念:bin,字面意义垃圾桶,用于装free_chunk的垃圾桶,在这里可以理解为链表表头。
以下均以glibc 2.23版本解析
fast bin
对于size较小的free_chunk,我们认为它很快就会被再次用到,因此在free 0x20~0x80大小的chunk时,我们会把它扔进fast bin里面,字面意义,里面存的free_chunk很快会被再次用到。fast bin 管理free_chunk采用单链表方式,并且符合后进先出(FILO)的原则,比如以下程序段
1 | x=malloc(0x10); |
那么z会得到y的指针,w会得到x的指针。
并且fast bin的chunk的之后的chunk prev_inuse位永远为1。也就是说它永远被视为在使用中,但是通常这个使用中是用于检测参不参与物理相邻chunk的合并,所以不会参与物理相邻的chunk的合并,也不会被切割。它的匹配规则就是,定量匹配。比如我想要一个0x30的chunk,没有就是没有,没有我就找其它的,不会说0x40好像还挺合适就拿了,不会。
fast bin一共有10个,main_arena结构体中,用fastbinsY来存储每一个fast bin的链表头部,32位系统中,fast bin,从0x10开始到0x40,有7种fast bin,64位系统从0x20开始到0x80,也是七种fast bin。单个fast bin链表上的chunk大小一定严格相等。
一定情况下可以修改global_max_fast的值来调整fast bin的个数,64位系统下这个值通常为0x80,代表小于等于0x80的chunk都为fast bin。
其余的链表头部都在bin数组当中。并且由于只有fast bin是单链表结构,其余bin都是双向链表结构,bin会成对出现。
unsorted bin
对于非fast bin大小的chunk,被释放时会首先进入unsorted bin。unsorted bin在特定的时候会进入small bin 和 large bin。
非fast bin的bin都是用一对bin指针来描述的,这两个bins也要看成一个chunk,然后初始它们的fd和bk都指向自身的prev_size那个位置。比如main_arena+104这个地方是bin数组的第一个,然后呢main_arena+104和main_arena+112分别就是unsorted bin的头部,它们本身虽然不是chunk,但是要理解它们的初始状态还是得看成一个chunk。所以main_arena+104和main_arena+112的初始值就是main_arena+88。如图:
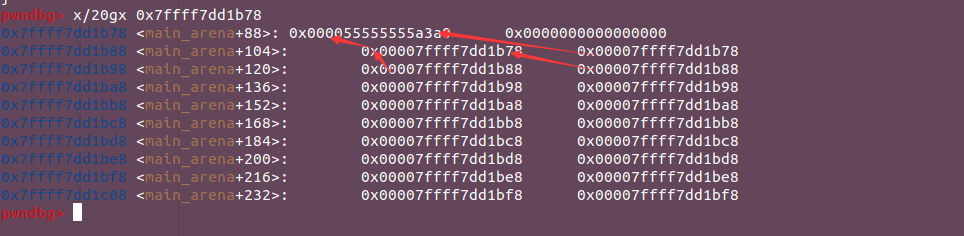
设置这一个bin的主要目的是扮演一个缓存层的角色以加快分配和释放的操作,链表中chunk大小不一定相等且无序排列。
当需要检查unsorted bin的时候,会遍历整个链表,寻找第一个能满足的chunk大小切割。如果切割后的大小不足2*SIZE_SZ,则不会切割,而是将整个堆块返回给用户使用。
small bin
一共有62个,从最小的chunk开始,公差为SIZE_SZ*2,双链表管理。它的特点也是跟fast bin一样,单条链表chunk大小相等,但是它会参与合并,切割。先进先出(FIFO)的策略。它表示的范围就是4*SIZE_SZ~126*SIZE_SZ
large bin
large bin与small bin不一样,large bin表示的是一个范围。一共有63个(假设下标0~62),从small bin最小不能表示的chunk开始,大到无穷。
它表示的范围类似一个等差数列。
| 起下标 | 止下标 | 公差 |
|---|---|---|
| 0 | 31 | 16*SIZE_SZ |
| 32 | 47 | 32*SIZE_SZ |
| 48 | 55 | 64*SIZE_SZ |
| 56 | 59 | 128*SIZE_SZ |
| 60 | 61 | 256*SIZE_SZ |
| 62 | 62 | ∞ |
最小的large bin是small bin的最小不能表示的大小。
所以large bin从128*SIZE_SZ开始。那么下标为0的large bin表示的范围就是128*SIZE_SZ~144*SIZE_SZ(左闭右开),同理下标为1的large bin表示的范围就是144*SIZE_SZ~160*SIZE_SZ,以此类推,等到32的时候就在原来的基础上加32*SIZE_SZ作为右开区间
它会以二维双向链表进行维护,对于bin中所有的chunk,相同大小的chunk用fd和bk指针相连,对于不同大小的chunk,采用fd_nextsize和bk_nextsize指针连接。并且沿着fd_nextsize指针,chunk大小递增。
top_chunk
我们之前说过,第一次malloc的时候,操作系统会给我们0x21000B的内存,它是作为一个top_chunk存在的,可以把top_chunk看成heap的边界。top_chunk的地址会被记录在main_arena+88的位置。gdb中通过p/x main_arena的命令也可以查看main_arena 的具体结构。
分配流程
首先用户malloc请求一个内存,先将请求的内存大小转换成chunk的大小,通过以下宏定义转换。
1 |
大概逻辑就是寻找一个最小能满足的chunksize作为chunk大小。
什么是最小能满足呢,我们看看一个size=0x20的chunk能有多少区域给用户写:0x20字节分别为prev_size,size,fd和bk,prev_size和size都不允许写,但是我们可以写fd和bk,以及下一个块的prev_size,前面我们也说过,当这个块没有被free的时候,它的fd,bk以及下一个chunk的prevsize位都是可以给用户任意写数据的,所以size=0x20,我们可以写的数据段为0x18。最小能满足就是说,当我请求的内存小于等于0x18的时候,我给你size=0x20的chunk,一旦多了就继续加0x10,也就是2*SIZE_SZ。这里用了其它宏定义去描述它我们尚且不管,如果用一个函数来实现它的话大概就是这样。
1 | size_t request2size(size_t req){ |
所以在分配的时候我们尽量选择0x18,0x28这样刚刚好的数值,这样更容易发生溢出,哪怕溢出一个字节,也能够加以利用。
那么算出了它的chunk_size之后呢,我们先会判断这个chunk_size是否<=global_max_fast,也就是是否在fast bin范围内。如果在则优先寻找能匹配的fast bin,如果该size的fast bin为空则会寻找small bin,small bin会寻找特定size的chunk返回。如果small bin也为空,或者找不到能满足的那就会去large bin中寻找,同样是最小能满足,找到之后返回或者切割之后返回。还找不到就会去unsorted bin,unsorted bin则会找第一个能满足的chunk并返回或者切割之后返回,unsorted bin 中每遍历一个不满足要求的unsorted bin就会把该unsorted bin加到合适的small bin或者large bin当中。如果切割之后剩余的部分<MINSIZE,那么则不会切割整个返回。
如果还是找不到,那么就会切割top_chunk。如果top_chunk都不能满足请求的大小,则会free top_chunk并再一次向操作系统申请新的top_chunk,这次申请同样还是申请一个0x21000B的top_chunk,通常情况下旧的top_chunk和新申请的top_chunk物理相邻,那么如果free 旧的top_chunk进入了一个非fast bin的链当中,就会被新的top_chunk合并。
如果一次申请的内存超过0x200000B,那么就不会在heap段上分配内存,将会使用mmap在libc的data段分配内存。通常利用就是每次分配给分配地址,分配size没限制那就malloc一个很大的内存就可以直接泄露libc的地址。
分配方式到此就讲完了。
malloc源码分析
接下来我们直接解读一下malloc的源码。
__libc_malloc源码分析
1 | /*------------------------ Public wrappers. --------------------------------*/ |
malloc实际上会直接调用这里的__libc_malloc函数,然后__libc_malloc也只不过是一层包装而已,实际上大部分的逻辑都是调用_int_malloc函数完成的,那么先来分析外面。
第一段
1 | void *(*hook) (size_t, const void *) |
定义了一个hook函数指针,如果hook!=NULL则直接调用hook指向的内容。hook是为了方便开发者调试的一个东西,比如我自己写了一个malloc函数想测试它的性能如何,那么我在这里直接让__malloc_hook=my_malloc就可以直接调用我自己写的malloc函数了。但是同时它也是最容易被劫持的,刚开始我们很多题目都是靠写__malloc_hook为一个onegadget,然后调用malloc去getshell的。在2.34版本中,__malloc_hook同其它大部分的hook都被删除了。
第二段
1 | arena_get (ar_ptr, bytes); |
通过arena_get获得一个分配区,arena_get是个宏定义,定义在arena.c中,
1 |
arena_lookup定义如下,也是获取分配器指针。
1 |
然后加锁,没了,获取分配器指针这一段不是我们主要要分析的,也就不过多去解析了。
第三段
1 | /* Retry with another arena only if we were able to find a usable arena |
它本身注释也写清楚了,在能够找到一个可用的arena之前尝试寻找另外一个arena,我这英文比较飘还请亲见谅。如果arena找到了但是_int_malloc居然返回0了,那么就重新寻找另一个分配器再次调用一次_int_malloc。完了之后呢,要给arena解锁,然后返回得到的chunk指针。
_int_malloc源码分析
由于比较长,为了摆脱水长度的嫌疑就不给看总代码了,需要的自己找glibc的源码就好了,下面我一段一段分析。
第一段:main_arena初始化
1 | INTERNAL_SIZE_T nb; /* normalized request size */ |
变量定义就不用看了,源码中也都标注出来了,这里最主要就是把用户请求的bytes转换成最小能满足的chunk size,然后它的变量名应该是nb,这个nb应该是nbytes的缩写。
1 |
|
这里原来也给注释了,这俩宏定义就是一样的,只不过做一个参数check。
这里还要注意一下那些宏定义:
1 | __glibc_unlikely(exp)表示exp很可能为假。 |
这三个宏定义在源码中经常能看到,其实它不会改编程序逻辑,只是告诉编译器这个很可能为某个值,就把否的情况作为跳转,真的情况就顺序运行下去,减少程序的跳转,一定程度上可以优化程序运行速度。或者还有一个简单粗暴的办法,你把这三个字符全都去了,不影响代码逻辑。
那么这一段的逻辑就是,如果在分配的时候arena为空,那就调用sys_malloc系统调用去请求一个chunk,然后memset这个chunk的数据段。
1 | /* ------------------ Testing support ----------------------------------*/ |
通常情况下perturb_byte为假,差不多意思就是如果你没有特殊设置,那么data段全为0字节,实际情况也确实是这样的。
第二段:fast bin的处理
1 |
|
这里嘛就会判断,你申请的这个nb是否<=global_max_fast,如果成立那么就会先在fast bin中寻找能满足的chunk,并且一定是完全匹配。它先找到av->fastbinY[idx]观察是否为0,如果不为0则说明该size的fast bin有chunk,那么就做以下动作:
取出av->fastbinY[idx]给victim
链表中删除这个victim,然后重新接回去。
中间有一个check,就是判断所给chunk的fastbinY链上的size是否=我需要的size,如果不相等那么直接报错退出。
末尾也有一个check
1 | /* |
就是check各个标志位,一般不会被触发,所以可以理解为fast bin在分配的时候只有这一个check,就是那个chunk的size一定是等于我申请的size的,过了就把这个chunk的指针返回,check没过报错,如果根本都没取到fast bin,那么就进行下面的逻辑了。
第三段:small bin的处理
1 |
|
首先判断它在不在small bin的范围内,然后取出这个size的small bin的最后一个chunk。它添加是在头部添加的,因此是符合先进先出的,嗯。然后需要判断,如果最后一个chunk!=自身的话,两个情况:要么没初始化arena,那就初始化,要么它有一个合法的块。如果它指向自身那就没必要做过多的判断了,没有这个大小的small bin。
这里是调用了malloc_consolidate函数去初始话这个arena分配器,该函数逻辑如下,不重点解读。
1 | static void malloc_consolidate(mstate av) |
大致意思就是清空所有arena的chunk,可以看到大的if是判断global_max_fast是否为0,为0则初始化,调用malloc_init_state和check_malloc_state函数初始化堆。否则把所有的fast bin 取出来,先清除它们的标志位,然后扔到unsorted bin中尝试向前合并或者向后合并。
这个呢,不太能运行到,因为victim==0的时候,必还没初始化,没初始化到这里就要初始化,初始化了之后victim又不可能=0了,所以这里可以理解为就是初始化arena的。
1 |
|
这里判断了一下victim->bk->fd==victim。也就是当前这个堆块后一个堆块的fd指针是否指向victim,如果不等说明链表被破坏了,那么就报错退出。
然后set_inuse_bit_at_offset,这个也不难理解,因为现在这个small bin被取出来了要使用了,所以我得设置后一个块的prev_inuse为1证明它不是空闲堆块了。然后就是进行unlink操作,对链表熟悉的同学应该看得懂。如果我要删除victim元素那应该怎么写逻辑?
1 | victim->fd->bk=victim->bk; |
在这里呢,我们取链的最后一个chunk,也就是bin->bk=victim所以victim->fd=bin
然后前面有一个赋值就是bck=victim->bk。带进上面的式子就得到了源码里面这样的写法。
然后下面设置main_arena标志位,一波同样的check,然后返回内存指针。也就是这里的chunk2mem,我们这里用的chunk指针,但是其实我们要返回的应该是chunk中数据域的指针,所以这里用了这样的宏定义做替换。
然后就是清除data数据,但是这个一般不会被执行,前面也分析过了,然后返回。这是small bin找到对应的chunk的逻辑,如果small bin还没找到那么接下来应该要去找large bin了,那么我们接着往下读。
第四段:分配largebin时的操作
那么如果没有在small bin的范围内呢。
1 | else |
这一步比较耐人寻味。
先获取large bin的index,然后如果fast bin不为空,调用malloc_consolidate。这一步是什么意思呢?我们前面分析过malloc_consolidate,如果没有初始化,那么初始化,如果初始化了,那么合并所有的fast bin。但是这里,都已经有fast bin存在了,那么堆指定已经初始化了,所以这里执行的逻辑基本只能是合并所有fast chunk。为什么要在搜索large bin的时候合并所有fast bin呢?因为large bin的匹配方式是最小能满足,然后切割。
考虑这样一种情况:
如果一个0x20的fast bin和0x500的large bin物理相邻。此时我要申请一个0x510的large bin,如果此时fast bin被合并了,那么我就能找到一个0x520的large bin并把它返回给用户。如果我不做这一步,那么我找不到0x510大小的large bin,我就被迫只能切割top_chunk了,这样子就浪费了很大的一块内存。
那么这个会不会有多此一举的时候呢,也是会的,还是刚刚那种情况,假如我申请0x500的chunk。这样子合并之后又会被切割,那么这样子,之前的合并就显得多次一举了,但是它只是浪费了一部分时间开销,内存分配上还是执行上面的逻辑比较占优势。所以这一步可以理解为空间上的优化,但是牺牲了小部分时间。看不来的话可以多看看上面举得例子。
第五段:large bin和unsorted bin的相爱相杀
这里开始逻辑都混合起来了,不仅有large bin,unsorted bin,切割top_chunk,还有系统调用重新分配top_chunk。
第1小块
1 | for (;; ) |
首先外面套了一个while(1),然后里面有一个while循环,判断内容就是取得最后一个unsorted chunk是否与这个bin相等,这里大概就是开始遍历unsorted chunk了。
然后这里又有一个check。victim->size <= 2 * SIZE_SZ就是说chunk的size小于等于0x10,victim->size > av->system_mem就是说我一个块的size居然比我系统调用申请来的内存都多,那这肯定不合理啊,所以任意满足一个就会报错了。
第二小块
1 | if (in_smallbin_range (nb) && |
这里有四个条件:
in_smallbin_range (nb):申请small bin范围内的chunkbck == unsorted_chunks (av):bck=victim->bk=unsorted_chunks(av)->bk->bk,也就是说unsorted_chunks (av)->bk->bk=unsorted_chunks (av),翻译一下差不多就是unsorted bin中只有一个chunk。victim == av->last_remainder:就是说这个chunk刚好是最近被分割过的剩余部分。(unsigned long) (size) > (unsigned long) (nb + MINSIZE)):保证我找到的这个chunksize> 需要的最小块+MINSIZE。为了保证等会我切割出nb size之后剩余的chunk能>MINSIZE,这里我也不知道为什么不能等于,可能解读哪里有误吧,如果您知道请帮我勘误一下,谢谢了。
然后接下来就是切割victim,切割出一块刚刚好大小的chunk给用户,切割出来的chunk作为新的av->last_remainder,注意如果切割剩余的chunk size不符合small bin的大小,则fd_nextsize和bk_nextisze会被清空,因为剩余的的chunk会被放到unsorted bin当中。
然后设置victim的size为nb|PREV_INUSE,然后判断是否为主分配加上标记。
然后把remainder的prev_inuse位设置为1,因为前一个块已经被拿走使用了,所以这个prev_inuse要设置为1。
然后因为remainder的size发生了改表,所以下一个chunk的prev_size也要相应地改变。
剩下的前面类似的都讲过就不赘述了。
第三小块
1 | /* remove from unsorted list */ |
否则会先取出这最后一个chunk,把它移除unsorted bin。如果取出的这个size刚好等于这个nb,那就说明这个块一定是最合适的,直接把它返回了,不要迟疑。如果并不是最合适呢,那么先会判断一下它是否属于small bin,属于则执行以下的逻辑,把bck对应bin的bk,fwd为对应bin的fd,也就是找到那一对bin,fwd在前,bck在后。就没了,预计等会就要用这些指针把chunk链进去了。
第四小块
1 | else |
如果不是small bin,那就得进large bin了,要进large bin。这里要知道,large bin可是所有bin当中最复杂的bin了,一个chunk四个指针,一对bin管理一个二维双向链表,fd,bk指针与相同大小的chunk连接,fd_nextsize和bk_nextsize与不同大小的chunk连接。
然后呢,虽然fd和bk是连接相同大小的chunk,但是那一对bin还是相当于是fd和bk字段。除了表头以外,其余的不同大小的chunk都是靠fd_nextsize和bk_nextsize的。并且沿着bk_nextsize,chunksize递增。也就是说av->bin[index]->bk是第一个chunk,并且size 最小,然后通过bk_nextsize字段一直连接到av->bin[index]->fd,反向同理。还有一点需要注意:large bin所在的chunk并不与chunk双向连接。
这里给出一张large bin的结构图,看看能不能帮助理解一下
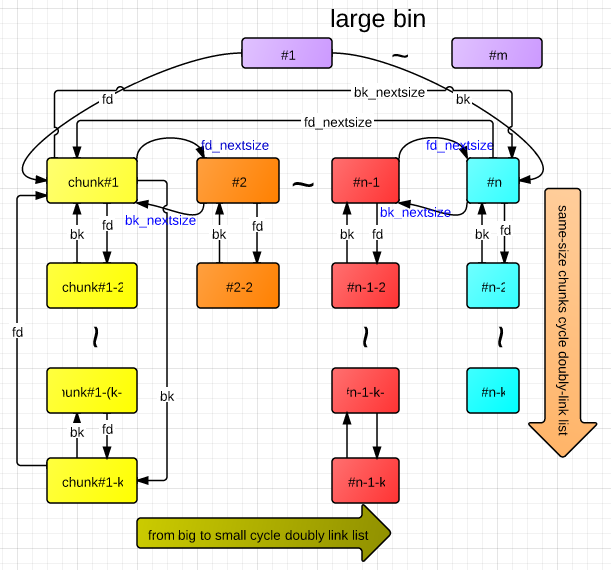
那么这里的bck指的是bin所在的chunk,fwd指的是最大的这个chunk。
bck->bk指的就是图上的n号chunk,也是这个large bin中最小的那个chunk,如果拿出来的unsorted bin它比最小的chunk还要小,那就已经可以确定插入在哪了,就不用做下面的循环再看看它在哪了。然后就是一个链表的插入操作,这里要注意的是,bin所在的chunk只有fd和bk指针,而其它chunk都是fd_nextsize和bk_nextsize连接的。我们只需要先在最大块和最小块之间插入,然后把bin->bk指向victim即可。
那么我们大概自己写一下操作看看与源码是否一致。首先不考虑bin,只考虑链表的情况下,我们先找到最大块和最小块。
1 | fwd=bin->fd; |
跟上面大致一样,只不过它这里fwd的值是那个large bin的chunk,直接通过fd指针也能直接找到最大的chunk。所以我后面的主要代码应该把fwd改成fwd->fd就跟上面一模一样了。
如果不是,那就接着往bk_nextsize这个指针上面找,找到大于等于的chunk为止。然后如果等于,就只需要用fd和bk指针与相等大小的chunk相连,如果没有相等,就得在fd_nextsize和bk_nextsize方向上插入,然后fd和bk都默认指向自己。这个我就不演试了,跟前面那个基本是一样的。
第五小块
1 | mark_bin (av, victim_index); |
这个就很简单了,就是一个插入操作,前面既然已经找到了插入的位置,这里一气呵成直接解决了。然后这里还有一个遍历unsorted bin的最大值,一次最多遍历10000个unsorted bin,这个也可以理解,如果我一次产生了很多的unsorted bin,然后我一次malloc,那边一直在循环搞这个unsorted bin,迟迟就没分配内存回来所以这里设定一个最大值。
到了这里,对unsorted bin的遍历就结束了。
第六小块
1 | if (!in_smallbin_range (nb)) |
这边就看这个最小能满足的nb是否在small bin的范围内。不在则执行,其实如果在的话,那前面有一个small bin的范围判断,如果small bin范围那,idx就是small bin,不在则是large bin的idx。small bin之前已经判断过一遍了,并且判断策略也跟之前不一样,所以这里加一个!in_small_bin_range的判断还是很有必要的。
来看下面的if语句,两个条件。
(victim = first (bin)) != bin:这个bin里面有chunk,并使victim=bin->fd(unsigned long) (victim->size) >= (unsigned long) (nb):找到目标chunk的size要大于等于这个最小能满足的size nb。
同时满足那么就可能要取这一块chunk来分配了,正如注释所说,如果bin为空或者最大的chunk还是比较小,那就跳过这个逻辑。然后victim = victim->bk_nextsize,这里victim是最大块,最大块的bk_nextsize就是最小块,这里应该也是尽量寻找最小能满足的块。正如循环所描述,如果victim的chunk size比我所需的最小能满足的chunk size nb还小,那就去寻找比他大的,因为是递增,所以能保证在chunk当中我一定会找到一个最小能满足的chunk。
这里解释一下两个最小能满足的意思:
首先nb是指用户需要的最小能满足的块的size,比如我只需要1个字节,但是我最小的chunk size都是0x20了,0x20的chunk就是对用户最小能满足的chunk size了。
如果能找到size=nb的块,当然是最好不过了,但是现实往往不会那么顺利,比如我只有一个0x30的块,如果我只有0x30而没有0x20的块,那么0x30就是我所有free块当中的最小能满足,其实这里nb应该叫最优能满足,但是我还是习惯这么叫了hhh。
然后呢找到这个之后就unlink这个块,把它从链中删除,拿出来之后进行一个判断,如果切割之后的块小于MINSIZE,那就不切割了,直接把它物理相邻的下一个快prev_inuse位设1,这个块就直接返回给用户了。否则就是切割,设置各种东西,这个前面有差不多的代码,我们主要看看剩下的块去哪里了,很明显,重新链入unsorted bin了。后面有一个check,如果unsorted bin->fd->bk!=unsorted bin,那么报错退出。这里需要注意,它只检测了unsorted bin->fd->bk是否等于那个unsorted bin,对于堆块来说我就是只检测了bk指针,这意味着fd指针如果修改为任意值不会在这里被检测到,这是一个利用小技巧,也只有你读过源码后才能好好理解这个unsorted bin attack了。然后如果剩余大小不在small bin范围内把nextsize指针全部清空,其它就是正常返回了。如果被切割的剩下chunk不在small bin范围内,就会清空它的fd_nextsize和bk_nextsize。因为它要回到unsorted bin里面,这两个字段就没什么用了,就会被清空。
第七小块
1 | ++idx; |
我们来讲一讲arena的binmap结构,这个用于快速检索一个bin是否为空,每一个bit表示对应的bin中是否存在空闲chunk,虽然不知道为什么前面没有用到。这一段就是说,如果large bin搜索完了都没有找到合适的chunk,那么就去下一个idx里面寻找,这很合理。然后一共有4个int,每个int32位表示一块map,一共表示128位。
第八小块
1 | for(;;) |
我们来看看两个条件
bit>map:如果这个位的权值都比它整个的map都大了,说明map上那个bit的权值必定为0bit==0:如果这个bit都是0说明这个index也不对。
满足其一就看看别的index。
然后如果说map==0,说明这整个block都没有空闲块,就直接跳过,不为0则退出去执行下面的操作,如果超过了block的总数,那就说明unsorted bin和large bin中也没有合适的chunk,那我们就切割top_chunk了,这里用了一个goto跳转,我们后面分析。
第九小块
1 | /* Advance to bin with set bit. There must be one. */ |
此时我已经找到了一个合适的block,然后就是看block的各个位了。从低位开始,如果检查到map那一位对应为0就找下一位,我们前面提到bk为large bin的最小块,所以先考虑它,当然不能说map里面说这里有它就有,我还得自己判断一下这个bin里面是不是真的有,如果没有(bin->bk==bin),那么我就要及时把标志位清除然后bit<<1去寻找下一个index。
最后一小块
1 | else |
如果它确实有chunk呢?然后其实它还是跟前面一样的,在large bin中找到chunk的处理方式,unlink,切割,判断,设置标志位,切割后及时更新last_remainder,这里就是一个large bin的遍历。
还要讲一下的就是这个check,依旧是对unsorted bin的一个check,判断第一个unsorted chunk的bk指针是否指向unsorted bin的位置。这里需要把割剩下的chunk重新放回unsorted bin。至此整个unsorted bin和large bin的分配就讲完了。
第六段:切割top_chunk
1 | use_top: |
这一步比较简单,就是说先从av->top拿到top_chunk的地址。判断大小尝试切割,如果不能切割,它也不会尽量去麻烦操作系统,先调用malloc_consolidate去合并所有的fast bin里面的chunk。然后合并之后接着步入之前的循环,重新找一次small bin large bin unsorted bin,因为现在可能已经有合适的chunk了对吧。
然后如果还是没有合适的呢?就会进入这里的else,调用sysmalloc去分配内存,一次还是分配0x21000的chunk作为新的top_chunk,原来的top_chunk将会被free,一般来说如果你没有改过top_chunk的size,那么新的和旧的top_chunk将会是物理相邻,如果free 的top_chunk不在fast bin范围内,那就会和新的top_chunk发生合并。那么这一整个malloc源码就解读完了,我们来做一下总结。
总结
检查是否设置了
malloc_hook,若设置了则跳转进入malloc_hook,若未设置则获取当前的分配区,进入int_malloc函数。如果当前的分配区为空,则调用
sysmalloc分配空间,返回指向新chunk的指针,否则进入下一步。若用户申请的大小在
fast bin的范围内,则考虑寻找对应size的fast bin chunk,判断该size的fast bin是否为空,不为空则取出第一个chunk返回,否则进入下一步。如果用户申请的大小符合
small bin的范围,则在相应大小的链表中寻找chunk,若small bin未初始化,则调用malloc_consolidate初始化分配器,然后继续下面的步骤,否则寻找对应的small bin的链表,如果该size的small bin不为空则取出返回,否则继续下面的步骤。如果申请的不在small bin的范围那么调用malloc_consolidate去合并所有fast bin并继续下面的步骤。用户申请的大小符合
large bin或small bin链表为空,开始处理unsorted bin链表中的chunk。在unsorted bin链表中查找符合大小的chunk,若用户申请的大小为small bin,unsorted bin中只有一块chunk并指向last_remainder,且chunk size的大小大于size+MINSIZE,则对当前的chunk进行分割,更新分配器中的last_remainder,切出的chunk返回给用户,剩余的chunk回unsorted bin。否则进入下一步。将当前的
unsorted bin中的chunk取下,若其size恰好为用户申请的size,则将chunk返回给用户。否则进入下一步获取当前
chunk size所对应的bins数组中的头指针。(large bin需要保证从大到小的顺序,因此需要遍历)将其插入到对应的链表中。如果处理的chunk的数量大于MAX_ITERS则不在处理。进入下一步。如果用户申请的空间的大小符合
large bin的范围或者对应的small bin链表为空且unsorted bin链表中没有符合大小的chunk,则在对应的large bin链表中查找符合条件的chunk(即其大小要大于用户申请的size)。若找到相应的chunk则对chunk进行拆分,返回符合要求的chunk(无法拆分时整块返回)。否则进入下一步。根据
binmap找到表示更大size的large bin链表,若其中存在空闲的chunk,则将chunk拆分之后返回符合要求的部分,并更新last_remainder。否则进入下一步。若
top_chunk的大小大于用户申请的空间的大小,则将top_chunk拆分,返回符合用户要求的chunk,并更新last_remainder,否则进入下一步。若
fast bin不为空,则调用malloc_consolidate合并fast bin,重新回到第四步再次从small bin搜索。否则进入下一步。调用
sysmalloc分配空间,free top chunk返回指向新chunk的指针。若
_int_malloc函数返回的chunk指针为空,且当前分配区指针不为空,则再次尝试_int_malloc对
chunk指针进行检查,主要检查chunk是否为mmap,且位于当前的分配区内。free源码分析
那我们现在开始解读一下free的源码
__libc_free源码分析
1 | void |
free函数也是直接调用这里的__libc_free函数完成chunk的释放的操作的。
跟malloc一样,先读取__free_hook看看是否为空,如果为空则直接由free_hook指向的函数代为执行free,这里也是我们经常劫持的钩子函数,而且free_hook劫持起来比malloc_hook困难。但是一旦劫持成功也会很方便,就是说malloc_hook函数我只能写one_gadget,而一旦条件苛刻那么就还得调栈啊之类的一些操作。劫持到了free_hook我们就直接写system函数,然后free一个内容为/bin/sh的堆块就能稳定get shell。
然后执行free(NULL)无任何效果,直接返回。
将传入的指针转换为chunk的指针,因为用户得到的指针其实是&chunk->fd,这里改为chunk的指针。然后这里需要寻找这个堆块的分配器,看看这个堆块是从哪里分配出来的。之后就是调用_int_free函数去真正释放chunk
_int_free源码分析
同样我们分成几段来讲解,总源码也不直接给了。
第一段:free前的各种check
1 |
|
首先变量定义是差不多的,然后这里进行了一项check。
(uintptr_t) p > (uintptr_t) -size:这里让我有点费解,指针和size进行比较。通常情况下size取负之后会变得很大,比如0xfff...这样的大数值通常指针不会指向这样的地址,f开头的一般都是内核地址。所以p>0xfff....主要是应该要检测被free的chunk的size不要过大。misaligned_chunk (p):这里的话主要是这个chunk的指针与上掩码,掩码就是0x10-1也就是0xf,取出后四位观察是否为0,如果不为0则说明指针错误了,机会在这里报错。这里主要是检查对齐,指针需要指到0x10的整倍数的chunk才能被正常free,就是不知道malloc为什么不开这个检测,开了又有一大批利用手段用不了了(狗头。
check不通过就会用malloc_printerr打印错误信息,然后处理锁上的一些内容。
1 |
|
又有一个check
size < MINSIZE:如果size还比MINSIZE要小,那肯定size肯定出错了。!aligned_OK (size):chunk size也要对齐,但是这个check一般不会被触发,因为再取出chunk size的时候就会把最低位与掉。
然后它这里需要check一下这个free的chunk是正在使用的,怎么check呢,那就肯定是下一个chunk的prev_inuse位为0啦,具体的实现函数是这样的。
1 |
|
多的也不说了,相信都能理解的,根据自身指针和自身大小就可以很容易知道下一个chunk的位置,然后检测一下prev_inuse位判断我当前chunk是否被使用。
fast bin范围的处理
fast bin的check
1 | if ((unsigned long)(size) <= (unsigned long)(get_max_fast ()) |
这个大条件很明显就是判断这个free的chunk是否为fast bin,后面又判断且这个chunk的后一个chunk不为top_chunk,虽然根据自己的经验好像判断后一个不为top_chunk没什么意义。
然后满足的话就是一个check,判断size是否小于MINSIZE或者是size>=system_mem。就是排除一些不合理的情况然后会重新尝试拿分配器的锁然后再做一个判断,如果刚刚那个条件还是成立的话那就说明size真的被改成了非法数值,那就报错退出。
如果进来了但是没有执行报错呢,说明可能多线程有点问题,就释放这个arena的锁,这里我多线程不是很好也不知道该如何解释,但是这个应该不是主要分析的,咱们平时做题基本也不会遇到多线程编程的题目。
free fast bin
1 |
|
它先执行了一个free_perturb函数
1 | //free_perturb |
其实跟前面malloc那个函数差不多,就是看你有没有设置那个值,如果设置了就在free之前把堆块进行memset清空,但是不一样的是,perturb中memset第二个参数是要根据你设置的值再异或一个0xff的。
然后是用set_fastchunks(av)宏定义去初始化fast bin。之后根据size算出下标找到对应的fast bin,之后就应该把这个free的chunk链入fast bin里面。这里还有一个check,如果bin顶部的那个chunk和这次要free的chunk相等的话,就报错退出,这也就是我们熟知的double free漏洞了。那么说到double free我们来看看double free能造成什么后果。
假如我要free的chunk是A,我第一次free A,bin为空,链入其中,fast bin中多了一个A。第二次free A,A再次被加入fast bin中,然后会导致产生一个自己指向自己的指针。fast bin中的情况就是两个A,A->A。此时我申请一个和A一样大的chunk,A被申请走,fast bin中还剩下一个A,但是此时用户手里有一个A,fast bin中也有一个A。用户可以直接编辑A的指针域,比如我让它指向了got表中的free函数。那么此时fast bin中的情况就是A->free@got。然后我再次申请和A一样大小的chunk,A被取出来,fast bin中剩下free@got。那么我第三次申请就得到了在free@got那边的chunk,然后假如我偷偷修改一下free@got为system,那就能轻松get shell了。这里可以看到,free@got这个指针我是能任意编辑的,也就是说我想申请到哪都不是问题,这样我就能任意地址写了。
你可能有点疑问,我free了2个堆块,怎么出来3个堆块。那我们想想,如果遍历一个单链表,你怎么判断结尾?咱们一般都是判断x->next!=NULL但是原来那边A的next指针确实是NULL,但是你把指针改过了,就会认为fast bin还没有空。
但是实际情况往往没有那么简单,前面我们说过了,malloc取出一个fast bin的chunk的时候,会判断它chunk的size是否等于当前我要申请的size,如果不是就会报错退出。所以double free在利用的时候还是没那么”任意”的,而且这里也不允许你直接double free,但是直接不能不代表不能间接double free,如果我先free一个A,free一个B之后再free一个A,那么我再申请到A的时候修改A的指针域一样可以劫持,并且可以绕过这里的检测。
然后如果过了检测,那就将这个chunk假如fast bin的顶部。这里就是一个单链表的插入,具体自己写的话应该是这样
1 | p->fd=av->fastbinY[index]->fd; |
源码中与这个略微有点不一样,效果是一样的。所以也可以看出来这个是后进先出,只在fast bin的一端插入删除,跟栈差不多。
末尾还有一个check,但是这个check通常不会被触发,有会的师傅也请帮帮,因为是真的不知道hhh。
free非fast bin
这里分了两种情况,如果chunk是mmap分配的话那就调用munmap_chunk函数去free这个chunk,这个情况不属于我们主要要分析的内容,所以那边的else分支我们跳过,只分析非mmap分配的chunk。
第一部分:锁
1 | if (! have_lock) { |
这我熟,就是在用一个分配器的时候先加锁,用完了释放就行了。这主要是为了防止多个线程之间发生竞争,虽然我看过多线程是说有独立的堆空间,但是假设堆块正常使用,正常分配,不去做指针的越界操作,那么同一个分配器分配给不同的线程用也是完全可行的,我只拿到我自己用的指针在合法范围内用一样不会造成竞争的现象。以上出于我自己的大胆推测,如有不对还请指正。
第二部分:free之前的各种check
1 |
|
好,我们来看第一个check。
p == av->top:free的chunk为top_chunk。
top_chunk和其它bin一样,都是出于待分配状态,top_chunk永远不会被使用。因为如果切割了top_chunk,top_chunk马上会下移,所以正常分配是绝对不会分配到现在的top_chunk指针的,所以当你尝试free top_chunk的时候,就会报这个错。
第二个check
contiguous (av):检查分配器上的flags,其实我也不知道是干嘛的(捂脸。(char *) nextchunk>=(char *) av->top + chunksize(av->top):然后这个条件呢就是说如果我这个chunk的下一个chunk居然在top_chunk之后,那肯定就也有错了。
第三个check
!prev_inuse(nextchunk):就是说如果后一个chunk的prev_inuse为0,也就是说这个chunk处于被free的状态,那么这一次free就有可能造成double free了,就会报错。
第四个check
nextchunk->size <= 2 * SIZE_SZ:如果下一个chunk的size有问题一样也要报错退出,这里说的就是下一个chunk的size小于MINSIZE的情况,free的话因为会涉及到chunk的向前合并或者向后合并,因此对前后堆块的检查都很严格。nextsize >= av->system_mem:size超出系统分配给分配器的内存,那也报错。
第三部分:free之后向前合并
1 | /* consolidate backward */ |
这里就提到了我们之前讲到的一个问题,我一个堆块怎么向前合并,也就是如何准确地找到前一个堆块。向前合并的时候我先判断一下前一个chunk是否被使用,如果不被使用那么就要和前面的chunk合并。这里我就可以通过prev_size位去找到这个堆块,用自身指针减去prev_size就得到了前一个chunk的指针。
这里需要注意,因为前面那个chunk可能在large bin,small bin或者是unsorted bin的链表当中,那么我就得先把它从这些bin里面解脱出来,也就是unlink操作,合并之后成为一个新的chunk然后再加入unsorted bin。
这里向前合并的操作呢应该也没有很复杂,就是改个size然后把free的指针指到前面去,相当于是要free合并后的chunk了。然后unlink把前面的chunk在bin中删除。
第四部分:free之后向后合并
1 |
|
这里有一个特判后面的chunk是否为top_chunk,top_chunk的情况就非常简单,因为合并的chunk并不在任何bin里面,top_chunk后面也没有堆块不需要设置标志位。只需要改一下top_chunk的size,然后改一下指针,就完了。
那么我们分析不是top_chunk的情况,首先我先获取一下下一个chunk的是否被使用,如果没有被使用,那么把后面的chunk就先unlink了,然后自己chunk的size加上后面那个chunk的size成为新的chunk。否则,我就直接清空后面chunk的prev_inuse位,就是表示我这个chunk已经不被使用了。好了之后那就是把这个chunk链入unsorted bin。这里还有一个check,跟malloc那个一样,,后面基本也都一样了,就不细讲了,链入,设置标记为,设置prev_size,如果不在small chunk的大小还会清空fd_nextsize和bk_nextsize指针,如果不理解可以往上翻一下看看。目录标题为“最后一小块”,那边是切割bin的时候设置的。
第五部分:最后的处理
1 |
|
如注释所说,如果我一次释放了一个很大的空间(0x10000B),那么会调用malloc_consolidate合并所有fast bin,如果进程所在的分配区是主分配区并且可以收缩内存的话,就调用systrim收缩内存,否则就获得非主分配区的heap_info指针,调用heap_trim收缩heap。因为我们认为一次free很大的空间那么操作系统可以适当回收点内存了,大不了等你不够就再像我要嘛,资源的合理配置,很合理。
至此,free部分的源码也都分析完啦。
总结
就不向malloc一样描述具体步骤了,因为本身逻辑没有很复杂。主要就是free非fast bin chunk的向前合并或者向后合并。
free在fast bin范围内的chunk,直接将chunk链入fast bin,free非fast bin范围的chunk视具体情况向前合并或者向后合并然后加入unsorted bin,如果一次free太多的空间有可能会被操作系统回收。
小结
源码分析也就完结撒花了,后续可能会出heap的各种利用方式和利用手段,或者局部分析其它版本的libc。