正则表达式的使用
最近在和战队一起的比赛中又出现了诸多想要学习的知识点,那就是re和QRcode,今天先学一下这个正则吧。
那么我已开始接触正则呢,应该是在学爬虫的时候,因为当时爬虫学的不太好也就没有接着学正则匹配。后来在换了linux系统之后经常会用到一个很有用的东西,那就是|grep。不得不说这个在找东西的时候真的是很有用的,比如
1 | $ls -l | grep "" |
那么本次和Nepnep战队参加xctf分区赛也是有一道修复二维码的题目,当时师傅们可能有些点没注意到,导致最后修复的二维码多达16000的扫描结果。
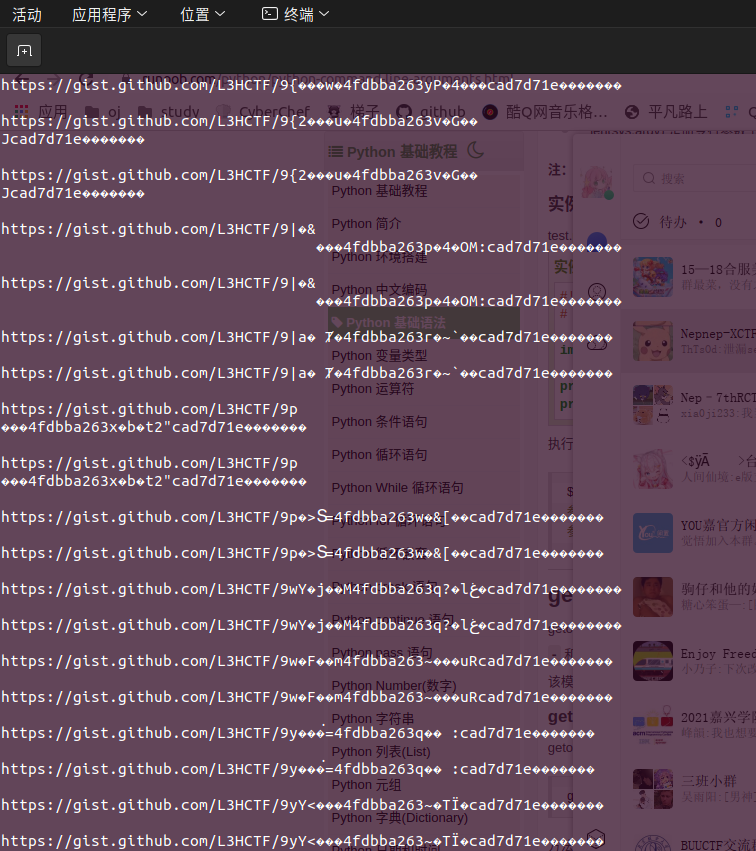
得到结果之后本以为要经历漫长的人工过滤,可是咱们战队的一位爷爷直接solved,而这位爷爷就是直接用了正则匹配。
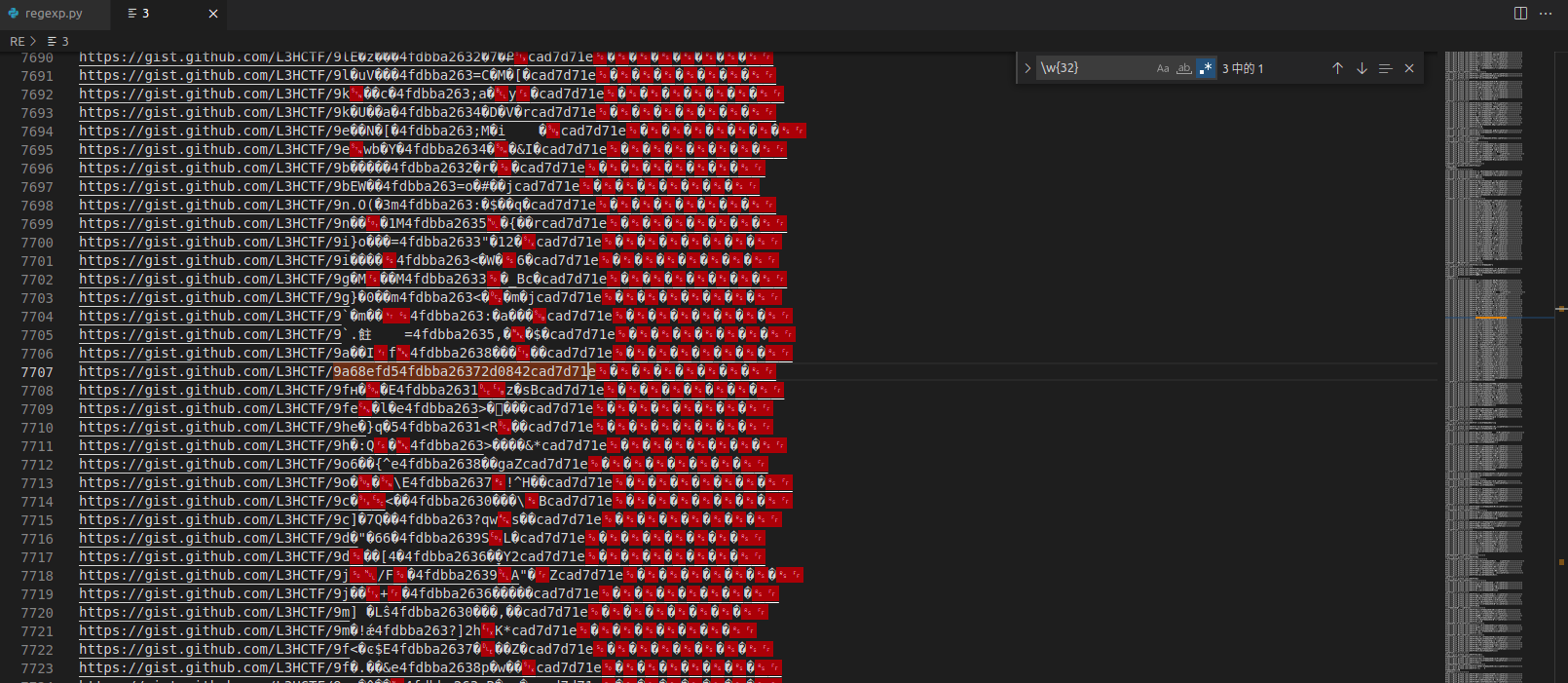
正则表达式
正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表示法、规则表达式、常规表示法,是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。
以上来自维基百科。
转义符
右斜杠(\)老转义符了,在右斜杠之后的一个字将会带有特殊含义,如果要匹配右斜杠则需要双写。
通配符
通配符我们熟知的就是星号(*)和问号(?),一般情况下它们分别代表任意多个字符或者是任意一个字符,在正则表达式中存在三种类似的符号,并且不能匹配任意字符,只能代表前面一个字符的数量。
1 | +:匹配一个或多个字符 |
例如
‘a+’可以匹配’a’,’aa’,’aaa’,’aaaa’……等字符串。
‘a?’可以匹配’a’或者空串
‘a*’则可以匹配第一种情况和第二种情况的并集。
匹配任意字符
[]方括号用于匹配单个字符。
例如
[abcde]可以匹配a,b,c,d,e中的任意一个字符。
如果加上^则代表匹配除了列表以外的所有字符。
例如
[^a]表示匹配所有非’a’的字符。
匹配次数限定
{}用于限定匹配次数
例如:
[ab]{3}表示[ab]匹配三次,[ab]{3,}表示至少匹配三次。
就先学这么多吧,后续再学就再加。